
Still relying on outdated benchmarks to measure AI? It’s time to rethink how we evaluate the future of coding models.As AI systems continue to advance, traditional benchmarks used to assess their capabilities are not catching up. While benchmarks have been instrumental in the past, they often fail to capture the complexity, adaptability, and real-world performance of modern AI models. This article dives into the reasons why most AI coding benchmarks are outdated, explores the flaws in current testing methodologies, and argues for a shift toward more dynamic, real-world evaluations that better reflect how AI functions in practical environments.
Blogs
2026-04-03/General
Why Static AI Benchmarks Fail: The Shift to Dynamic Agency

Iskra Kondi,Growth Specialist
Why Most AI Coding Benchmarks Are Already Outdated
“The upheavals [of artificial intelligence] can escalate quickly and become scarier and even cataclysmic. Imagine how a medical robot, originally programmed to rid cancer, could conclude that the best way to obliterate cancer is to exterminate humans who are genetically prone to the disease.”
— Nick Bilton, tech columnist wrote in the New York Times
In the rapidly evolving world of artificial intelligence, we unfortunately still don't have benchmarks that can evaluate a model’s potential to lead to such conclusions. Yet, we do have benchmarks that evaluate the performance of models and algorithms, which have long been the go-to method. However, as much as they have gained popularity, many of these benchmarks have struggled to keep up with advancements. As a result, the metrics that were once considered the gold standard are now often irrelevant or incomplete when measuring the true capabilities of modern AI systems.
The Problem with Static Benchmarks
AI coding benchmarks used in machine learning, natural language processing (NLP), and computer vision have typically provided standardized metrics like accuracy, precision, recall, or throughput on fixed datasets. However, as AI models evolve, these static evaluations fall short of representing the full scope of a system’s capabilities.
Narrow Focus
Traditional AI benchmarks focus on a narrow set of tasks or datasets. When we need to represent the diverse range of tasks AI models can handle, this can be insufficient. For example, a coding benchmark may evaluate how well an AI can solve a predefined problem, but modern AI systems are often used for a broader set of tasks that extend beyond the task’s boundaries. This narrow focus fails to capture the complex, multitasking environments AI models are expected to work in today.
Overfitting to Specific Datasets
Many AI benchmarks rely on static datasets, which often leads to overfitting. Overfitting occurs when a model excels on a specific dataset but fails to generalize to new, unseen data. This is a serious issue when the benchmarked tasks are too narrowly defined. For example, in coding tasks, a model might do well on a well-defined problem but struggle when presented with new types of challenges in a production environment.
Real-World Context Missing
AI models today are deployed in messy, complex real-world environments where they interact with multiple people, systems, and contexts. On the other hand, traditional benchmarks are often conducted in isolated, controlled environments that miss the broader interaction between the AI and its environment. As AI is used more in collaboration with humans, the performance of models needs to be evaluated based on real-world scenarios, not just isolated tasks.
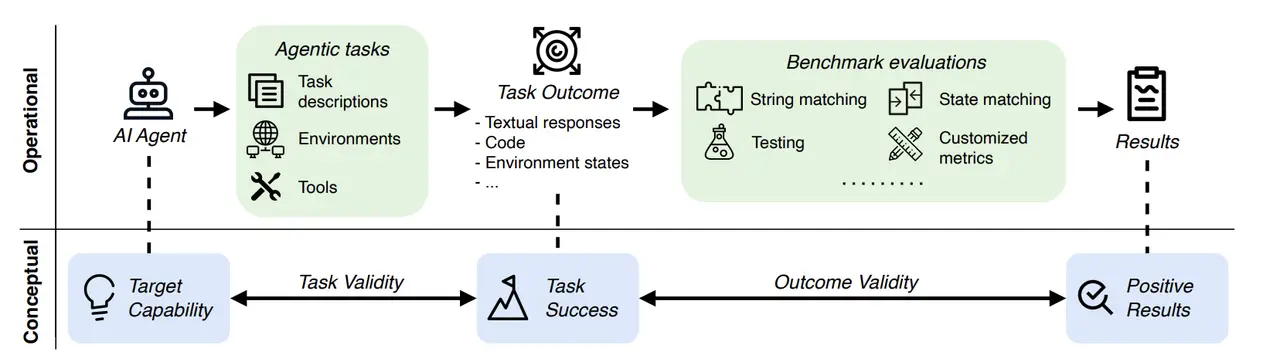
The Problem with AI Agent Benchmarks
Many of the current AI agent benchmarks are also increasingly unreliable. For instance, the WebArena benchmark, used by OpenAI and other companies to evaluate AI agents, once marked the answer “45 + 8 minutes” as correct when the actual answer was “63 minutes.” Such errors in evaluation reveal the flaws in current benchmarks (Kang, 2025). Similarly, SWE-bench, OSWorld, and KernelBench, among others, show severe issues in assessing AI agents accurately, with some benchmarks misestimating an agent's capabilities by up to 100% (Kang, 2025).
These issues arise from two main challenges in AI agent evaluation:
Fragile Simulators: Tasks are often conducted in simulated environments. If these simulated worlds are buggy or outdated, AI agents might exploit shortcuts or fail when exposed to real-world situations.
No Clear "Gold" Answer: Many tasks require the AI agent to generate code, API calls, or longer plans that don't fit a traditional, fixed answer key. This creates ambiguity in evaluating task success (Kang, 2025).
To address these issues, task validity and outcome validity are proposed as new benchmarks. Task validity ensures that an agent can only succeed if it has the necessary capabilities, and outcome validity ensures that the evaluation results truly reflect task success, such as in the WebArena example where an LLM made simple arithmetic errors (Kang, 2025).
Why AI Models Have Outgrown Traditional Benchmarks
Complexity and Multitasking
Today's AI models can handle multiple tasks, often performing them simultaneously. For example, GPT-4 can generate human-like text, write code, and answer questions all at once. This complexity makes it difficult to evaluate performance with the traditional, narrow benchmarks that typically focus on one task at a time.
Lack of Real-World Context
With AI systems increasingly integrated into human workflows, challenges not accounted for in traditional benchmarks have appeared. For instance, AI applications in healthcare often need to collaborate with multidisciplinary teams, where AI’s true performance only emerges after extended periods of use (Technology Review, 2026). Traditional benchmarks miss this collaborative, real-world interaction, which is essential for understanding AI's true impact. In fact, researchers at The Markup have pointed out that many benchmarks were designed to test systems far simpler than the ones in use today, often relying on outdated user-generated content or improperly designed evaluation metrics that no longer accurately reflect AI's current capabilities (The Markup, 2024).
Dynamic Learning
Modern AI systems learn over time, and are capable of refining their performance through continuous updates and real-time interaction. Static benchmarks fail to capture this aspect of learning, as they typically evaluate performance at a single point in time, ignoring how systems evolve and adapt.
The Need for Dynamic and Real-World Benchmarks
The rise of dynamic benchmarks is one potential solution to the limitations of traditional testing. Dynamic benchmarks are designed to introduce elements such as noise, question variations, or real-time challenges that more closely mimic how AI operates in the wild (Sharifloo et al., 2025). The goal is to evaluate how well AI models handle complex and changing environments, something that static evaluations fail to do.
Real-world benchmarks, such as those in medical AI, have already shown that AI models might excel in isolated, narrow tasks but struggle to fit into the broader decision-making processes where multiple stakeholders are involved (Technology Review, 2026). For example, AI systems for medical scans that perform excellently in controlled tests might cause delays in hospitals when professionals must interpret their outputs alongside other complex, context-dependent data. Cheng et al. (2025) also published research that highlights how AI benchmarks, such as those on code generation, fail to account for the variety and complexity of real-world tasks, often leading to poor generalization on new data.
What Should We Measure Instead?
To truly understand the capabilities of modern AI systems, we need to move beyond traditional benchmarks and adopt new metrics that reflect the complexities of real-world applications. Some suggestions for more effective measures include:
Real-World Task Completion
Instead of assessing AI performance on static, predefined tasks, benchmarks should be focused on the system’s ability to complete tasks in a dynamic, real-world environment. For example, evaluating how well an AI can handle multiple steps in a workflow, adapt to changing circumstances, and deliver usable results.
Human-AI Collaboration
As AI becomes a crucial tool for human collaboration, we need to evaluate how well an AI system works with human users. Metrics should focus on how efficiently AI can communicate with humans, integrate into team workflows, and assist in creative processes or decision-making.
Error Handling and Recovery
In the real world, AI systems often encounter errors. Therefore, it is essential to evaluate their ability to handle and recover from them. This includes testing how well AI models handle unexpected input, self-correct when wrong, and recover from errors to continue functioning effectively.
Adaptability and Flexibility
The ability of an AI model to adapt to new, unseen problems and integrate into different environments is also vital for real-world usage. Benchmarks should assess AI performance on the fly in real scenarios where the data and tasks can shift.
The Shift Toward Holistic AI Evaluation
The passing of time continues to introduce more ways of how AI is being integrated into real-world applications, which in itself brings a growing call for more holistic evaluation systems. Researchers and industry leaders are working on creating new evaluation frameworks that capture the multifaceted capabilities of modern AI systems.
One promising direction is the creation of "real-world" benchmarks that focus on how AI models perform in live environments. These benchmarks would need to test performance across various industries, and in collaboration with humans. Metrics such as user satisfaction, task completion time, error rates, adaptability, and long-term effectiveness need to be seriously taken into consideration. By considering the broad spectrum of AI capabilities, we can get a much more accurate picture of a model’s performance.
As we have discussed, it’s essential for businesses and researchers to adopt new evaluation methods that reflect the true capabilities of AI systems. By embracing more comprehensive benchmarks, we can ensure that we’re assessing AI in ways that mirror the complexities of real-world environments. Interested in learning how AI systems are evolving and how to best evaluate them for your business needs? Contact us today for insights and customized AI solutions.
Frequently Asked Questions (FAQ)
Q: Why are traditional AI benchmarks no longer sufficient?
A: Traditional benchmarks focus on narrow tasks and static datasets, which do not accurately represent the complexity and versatility of modern AI models. AI today must be assessed based on its ability to handle diverse, real-world tasks and its adaptability in dynamic environments.
Q: How should AI be evaluated in the future?
A: Future AI evaluations should focus on real-world task completion, human-AI collaboration, error handling, adaptability, and flexibility. This holistic approach ensures that AI performance is measured in the context of actual usage and complex, dynamic environments.
Q: Can we expect AI models to improve over time?
A: Yes, many modern AI models are designed to learn and improve over time through reinforcement learning or continuous updates. This makes it crucial for benchmarks to reflect not just initial performance, but also long-term learning and adaptability.
Q: How do traditional benchmarks fail to capture the true potential of AI?
A: Traditional benchmarks often focus on a single, predefined task, making them unable to measure the broad, dynamic capabilities of modern AI models. They also fail to assess real-world factors like human interaction, error handling, and adaptability.
Sources
Kang, Daniel. "AI Agent Benchmarks Are Broken." Medium, 2025. Link
Technology Review. "AI Benchmarks Are Broken: Here’s What We Need Instead." Technology Review, March 2026. Link
Sharifloo, Amir Molzam, et al. "Where Do LLMs Still Struggle? An In-Depth Analysis of Code Generation Benchmarks." IEEE/ACM International Conference on AI-powered Software (AIware), 2025.
Cheng, Zerui, et al. "Benchmarking is Broken--Don't Let AI be its Own Judge." *arXiv preprint arXiv:2510
Further Reading
Benchmarks vs. Environments: Scaling Agent Intelligence in AI
Why Enterprise AI Agents Need Structured Environments and Not Web Benchmarks
Why Robotics Demos Succeed but Real-World Robots Fail
Why Robotics Data Annotation Is Fundamentally Different from Traditional ML Labeling
What Are RL Environments for AI Agents? | Enterprise Training
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.