
Artificial intelligence agents are advancing rapidly, yet many teams still rely on static benchmarks to evaluate progress. While benchmarks provide standardization and comparability, they struggle to capture the dynamic, uncertain environments where agents actually operate. In short, benchmarks measure performance under fixed conditions, while reinforcement learning (RL) environments evaluate behavior under change. That distinction is increasingly critical in modern AI systems.
Blogs
2026-03-20/General
Benchmarks vs. Environments: Scaling Agent Intelligence in AI

Jessy Abu Khalil,Director of Sales Enablement
RL Environment vs Benchmark: Why Agent Training Needs More Than Static Eval
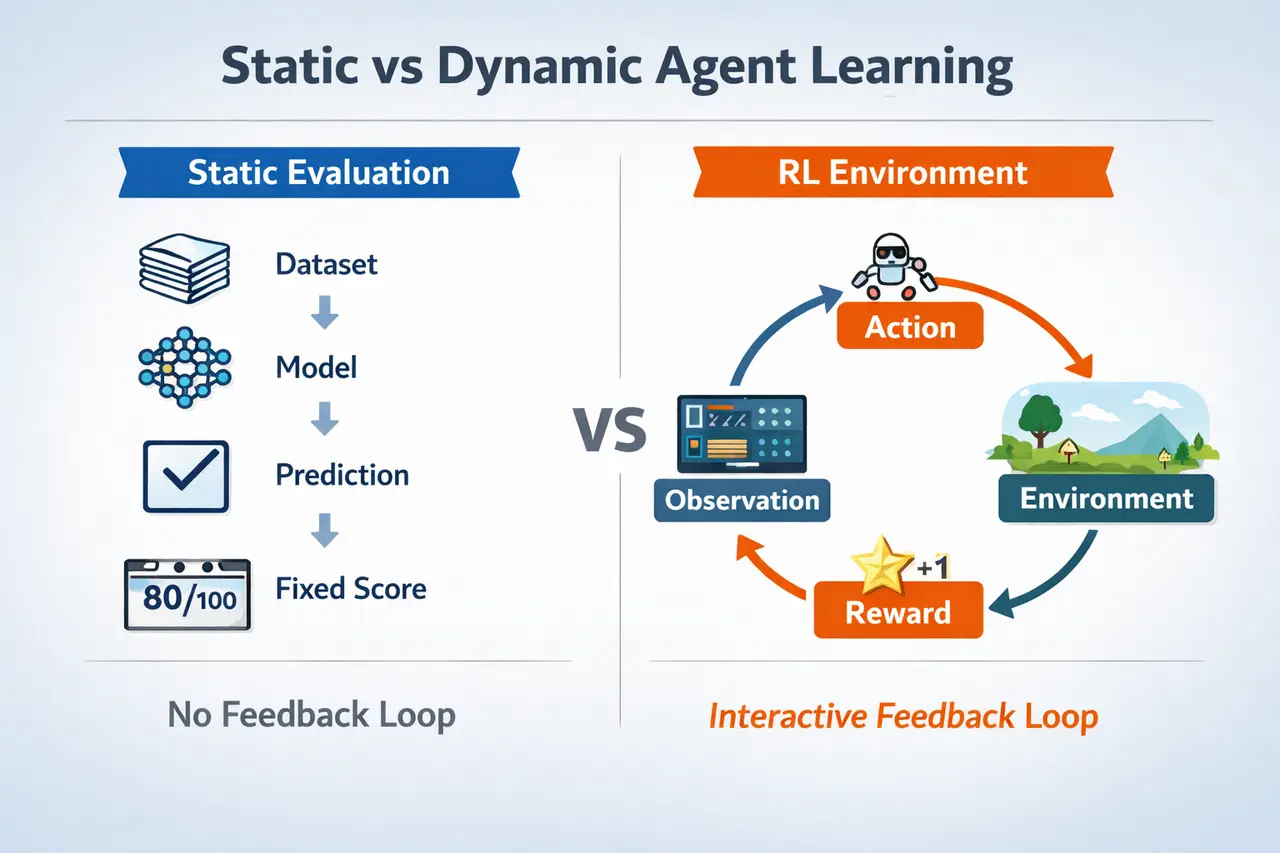
What Is a Benchmark vs an RL Environment?
Benchmarks are standardized evaluation datasets with fixed inputs and expected outputs. Classic examples such as ImageNet and MMLU allow researchers to compare models under identical conditions, making them essential for reproducibility and progress tracking. However, most traditional benchmarks assume that the task distribution is static and that the model does not influence future inputs.
Reinforcement learning environments, by contrast, are interactive systems in which agents take actions, receive feedback, and influence future states. This paradigm has driven major breakthroughs in AI. For example, AlphaGo achieved superhuman performance not through static evaluation, but through reinforcement learning over millions of simulated games (Silver et al., 2016).
More recent work on agent evaluation reinforces this shift. Frameworks such as AgentBench (Liu et al., 2023) show that language models evaluated in interactive, multi-step settings often perform very differently than in static benchmarks, particularly on tasks requiring planning, tool use, and long-horizon reasoning.
Summary: Benchmarks evaluate outputs, while RL environments evaluate behavior.
Why Static Benchmarks Fall Short for Agents
Temporal Dynamics Are Missing
Most benchmarks evaluate single-step predictions, whereas real-world agents operate across sequences of decisions.
This limitation is evident across domains. In AlphaGo, performance gains came from optimizing long-term strategies rather than individual moves. Similarly, recent work on language agents shows that models can perform well on single-turn reasoning tasks yet struggle when required to plan across multiple steps or maintain consistency over time (Liu et al., 2023; Liang et al., 2022 – HELM).
Summary: Agents trained only on static benchmarks often struggle with long-horizon reasoning.
No Feedback Loop for Learning
Benchmarks do not inherently provide a mechanism for learning from consequences. Once a prediction is made, the evaluation ends.
RL environments, however, are built around feedback loops. Agents receive rewards or penalties, update their policies, and improve through interaction. This paradigm has been validated across domains, from robotics to game-playing systems.
For example, OpenAI’s work on dexterous in-hand manipulation demonstrated that policies trained in interactive simulation—combined with domain randomization—could successfully transfer to the real world despite significant physical variability (OpenAI et al., 2018; Tobin et al., 2017).
In short: Benchmarks test what a model knows, while environments train what an agent does.
Ignoring Distribution Shift
Many benchmarks assume that training and test data come from similar distributions. In real-world deployments, this assumption rarely holds.
Research on domain randomization shows that exposing agents to diverse and noisy environments during training significantly improves real-world robustness (Tobin et al., 2017). Similarly, broader evaluations such as the Stanford AI Index Report (2024) highlight that model performance can degrade substantially when systems are deployed outside benchmark conditions.
Efforts like BIG-Bench (Srivastava et al., 2022) and HELM (Liang et al., 2022) attempt to address this by expanding coverage, but they still lack true interactivity and feedback.
Summary: Benchmarks assume relative stability, while RL environments prepare agents for change.
Case Studies: Where RL Environments Outperform Benchmarks
The advantages of environment-based evaluation become clear across multiple domains.
Robotics: OpenAI’s dexterous hand project showed that agents trained in simulation with domain randomization could transfer successfully to real-world tasks—something not achievable through static datasets alone.
Autonomous Systems: Companies such as Waymo and Tesla rely heavily on simulation environments to expose driving systems to rare and safety-critical scenarios. These edge cases are difficult to capture in fixed datasets but essential for real-world performance.
Language Agents: Recent agent frameworks (e.g., ReAct, tool-use agents, and AgentBench) demonstrate that reasoning, planning, and tool use improve significantly when models operate in interactive settings with feedback, rather than static prompt-response evaluations.
Key takeaway: Real-world capability emerges from interaction, not static evaluation.
Why You Need Both, But Not Equally
Benchmarks remain valuable. They enable quick comparisons, regression testing, and standardized progress tracking across models.
However, they are not sufficient for evaluating real-world capability. High benchmark scores do not guarantee robustness, adaptability, or effective long-term reasoning.
RL environments fill this gap by testing how agents behave over time, under uncertainty, and in response to feedback.
In short: Benchmarks are necessary for measurement, but environments are essential for capability.
Designing Better Evaluation Systems
The next generation of AI evaluation systems will combine both approaches. Static benchmarks can establish baseline competence, while interactive environments can stress-test agents in realistic conditions.
Recent research trends emphasize scaling not only data, but also environments—introducing stochasticity, diverse scenarios, and multi-step interaction. This shift is particularly important for agentic systems that must operate reliably in open-ended settings.
Summary: The key difference between benchmarks and environments is not just accuracy—but adaptability.
Key Takeaways
Benchmarks provide a controlled and standardized way to evaluate models, but they fall short in capturing dynamic, real-world behavior. Reinforcement learning environments enable agents to learn through interaction, adapt to changing conditions, and optimize long-term outcomes.
Final takeaway: Benchmarks measure performance, but environments build intelligence.
Further Reading
If you’re interested in AI evaluation, search disruption, and human benchmarking, explore:
GPT-5 vs. Gemini 3 Pro: Specialized Science Verdict from SuperGPQA
Beyond the Attention Bottleneck: How CAD Boosts Long-Context LLM Training Efficiency by 1.35x
EditReward: Outperforming GPT-5 in AI Image Editing Alignment
These articles expand on evaluation, benchmarking, and search-quality dynamics- helping you design AI systems that scale responsibly.
📩Contact Abaka AI to explore custom evaluation datasets for reasoning models and learn how we can support your enterprise AI deployment.
FAQs
What is the main limitation of AI benchmarks?
They are static and do not capture interaction, feedback, or sequential decision-making.
Why are RL environments important for agents?
They allow agents to learn from consequences, adapt to change, and improve over time.
Can benchmarks and RL be used together?
Yes. Benchmarks provide baseline evaluation, while RL environments test real-world capability.
Do higher benchmark scores mean better agents?
Not necessarily. Many systems perform well on benchmarks but struggle in dynamic environments.
What is changing in AI evaluation today?
There is a growing shift toward interactive, multi-step, and environment-based evaluation frameworks.
Sources
Silver, David, et al. “Mastering the Game of Go with Deep Neural Networks and Tree Search.” Nature, vol. 529, no. 7587, 2016, pp. 484–489.
OpenAI, et al. “Learning Dexterous In-Hand Manipulation.” arXiv, 2018, https://arxiv.org/abs/1808.00177
Tobin, Josh, et al. “Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World.” IROS, 2017, https://arxiv.org/abs/1703.06907
Stanford Institute for Human-Centered Artificial Intelligence. AI Index Report 2024. Stanford University, 2024,https://aiindex.stanford.edu/report/
Liu, Xiao, et al. “AgentBench: Evaluating LLMs as Agents.” arXiv, 2023, https://arxiv.org/abs/2308.03688
Liang, Percy, et al. “Holistic Evaluation of Language Models (HELM).” arXiv, 2022, https://arxiv.org/abs/2211.09110
Srivastava, Aarohi, et al. “Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models (BIG-Bench).” arXiv, 2022, https://arxiv.org/abs/2206.04615
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.