GPT-5 vs. Gemini 3 Pro: Specialized Science Verdict from SuperGPQA
Yuna Huang,Marketing Curator
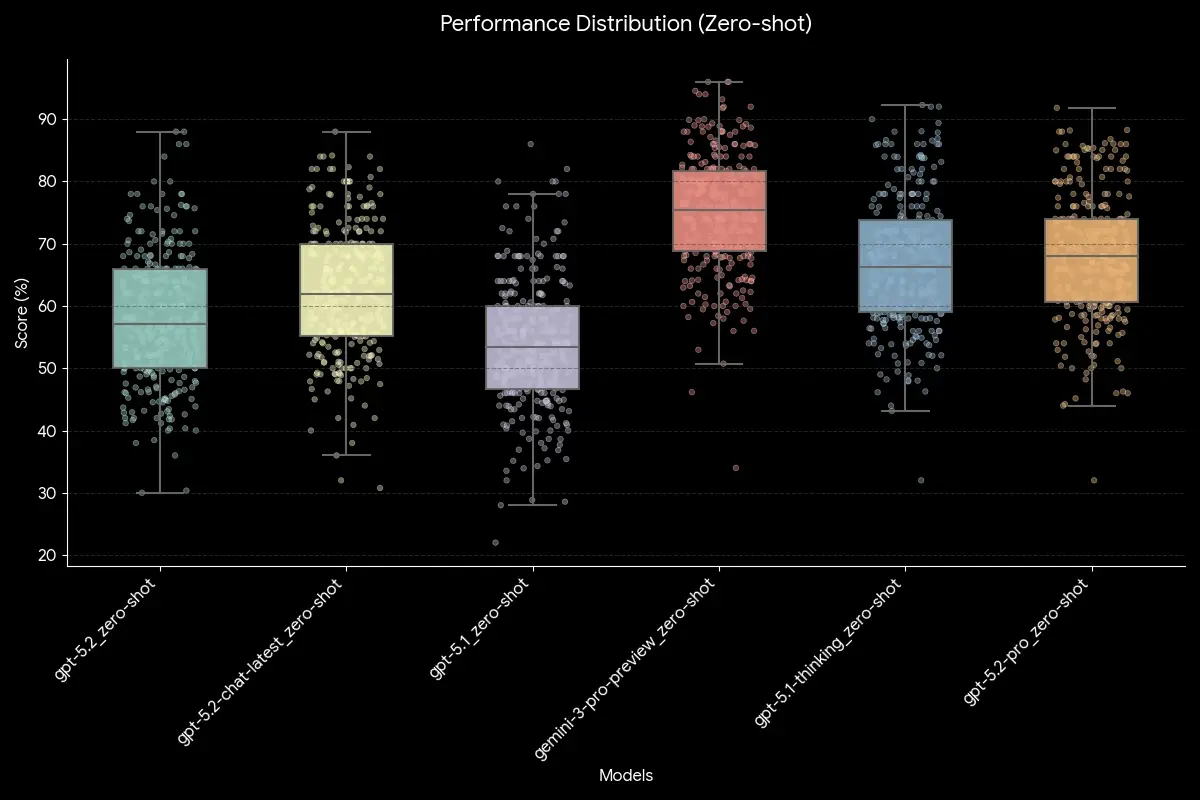
Gemini 3 Pro currently reigns supreme in domain expertise, outperforming the GPT-5 series in specialized scientific knowledge density. While GPT-5.1-Thinking excels in logic-heavy tasks, SuperGPQA data shows Gemini 3 Pro leads in "long-tail" disciplines like theoretical physics (79.75% accuracy) and aquaculture, making it the superior choice for deep-tech R&D applications.
GPT-5 Series vs. Gemini 3 Pro: Why Knowledge Density Trumps Pure Reasoning
The launch of OpenAI’s GPT-5.2 Pro has shifted the AI industry's focus toward "agentic reasoning" and complex logic. However, for enterprises in deep-tech sectors, reasoning is only as good as the underlying data it operates on. To find the true leader in "Hard Science," Abaka AI, as a core contributor to the 2077AI collective, helped conduct a rigorous evaluation using the SuperGPQA benchmark.
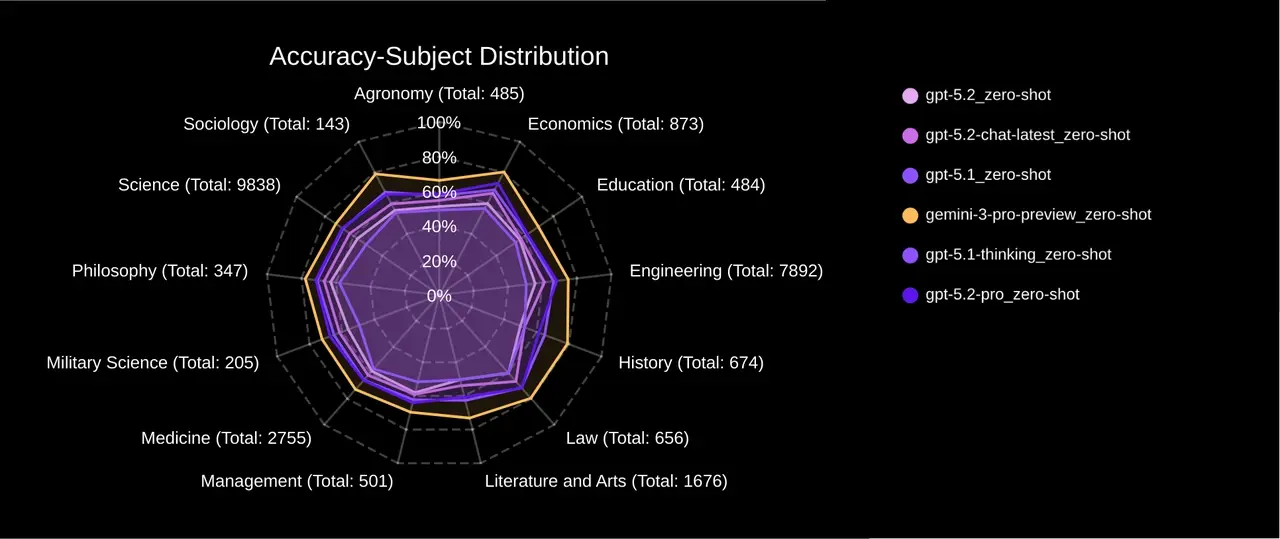
SuperGPQA is a gold-standard dataset covering 285 specialized disciplines, from Quantum Mechanics to Agronomy—designed to bypass surface-level internet data and test graduate-level professional knowledge.
The Verdict: Gemini 3 Pro Leads in Specialized Knowledge
Contrary to the "newer is always better" narrative, our data indicates that Google’s Gemini 3 Pro Preview currently holds a statistical edge over the GPT-5 series in high-stakes scientific domains. While the GPT-5 series excels in logic-heavy tasks, Gemini's internal "world model" appears to have a higher density of specialized information.
Hard Physics: The Robustness of World Models
Theoretical physics remains the ultimate stress test for AI. In our Relativity subfield (2,000+ graduate questions), the models performed as follows:
Gemini 3 Pro: 79.75% Accuracy
GPT-5.1-Thinking: 74.68% Accuracy
GPT-5.2 Pro: 70.89% Accuracy
In short, Gemini 3 Pro is used when precise physical intuition is required, while GPT-5.1-Thinking is preferred for pure logical deduction tasks.
The "Long-Tail" Knowledge Test: Aquaculture
In niche fields like Aquaculture—which lack the massive training corpora of general topics—Gemini 3 Pro maintained a robust 62.50% accuracy. GPT-5.2 Pro struggled significantly at 48.21%, a gap of over 14 percentage points. This suggests that Gemini 3 Pro is currently the statistical leader for applications requiring deep, memorized professional expertise.
Conclusion: Which Model Should You Deploy?
Choose GPT-5.1-Thinking if your application is a "reasoning puzzle" (e.g., code debugging or complex logic).
Choose Gemini 3 Pro if your application requires "domain expertise" (e.g., R&D in agrotech or theoretical physics).
FAQ
How does SuperGPQA differ from standard AI benchmarks?
Unlike MMLU, SuperGPQA focuses on "long-tail" graduate-level knowledge that is not easily found in common web crawls, preventing models from simply "memorizing" answers.
Why does Gemini 3 Pro outperform GPT-5 in specific sciences?
Data suggests Gemini 3 Pro has a more comprehensive multi-modal training foundation, allowing for better "internalization" of complex scientific concepts rather than just text-based reasoning.
Can these models be used for actual scientific research?
While they lead in accuracy, they should be used as "co-pilots" for researchers. The 70-80% accuracy range indicates they are powerful assistants but require human verification in high-stakes environments.