

Train Smarter Agents with
Production-Grade RL Environments
Real enterprise simulations. Real reward signals. Real results.
Agents that chat.
But can they work?
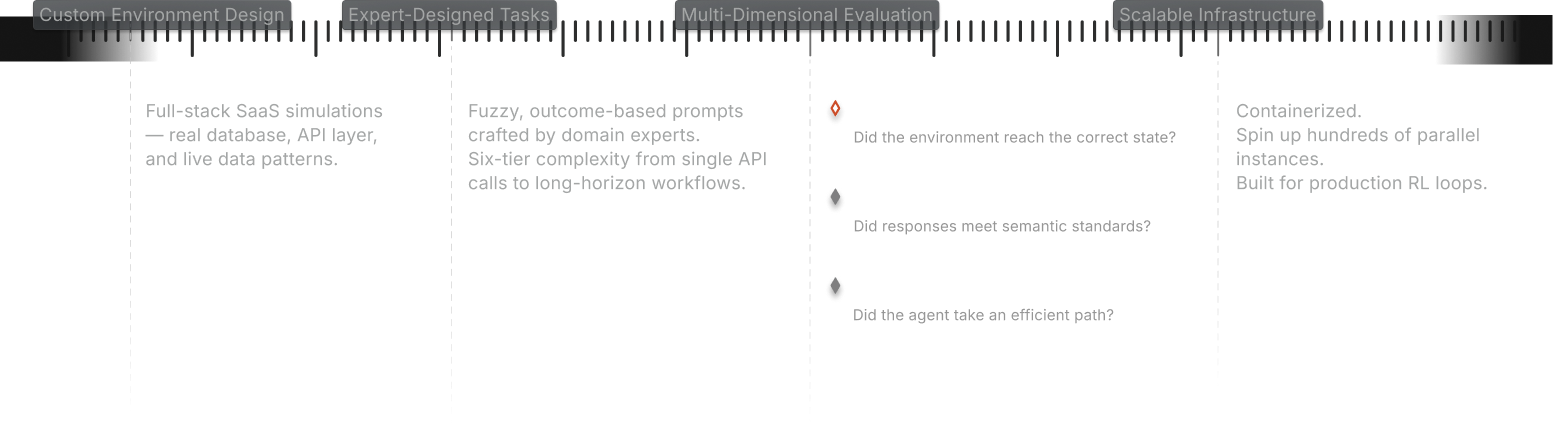
Real enterprise tasks require multi-step reasoning across live systems. An RL environment is a realistic simulation where agents practice workflows at scale — without touching production data.
Agent actions have real consequences on system state
Dense Reward Signal
Step-by-step feedback, not just pass/fail
Deterministic Reset
Reproducible training at massive scale
What Abaka Delivers
Who This Is For
Enterprise Messaging
Navigate channels, threads, and DMs in production-style workspaces seeded with real community data.
E-Commerce & Customer Service
Full marketplace with products, orders, inventory. Agents learn to search, compare, and manage customer requests.
Recruiting & HR Automation
Manage job postings, candidate stages, and interview scheduling with strict privacy controls.
Cross-Application Workflows
The hardest real-world tasks span multiple tools. We test the tool-switching and context-carrying enterprise agents need.
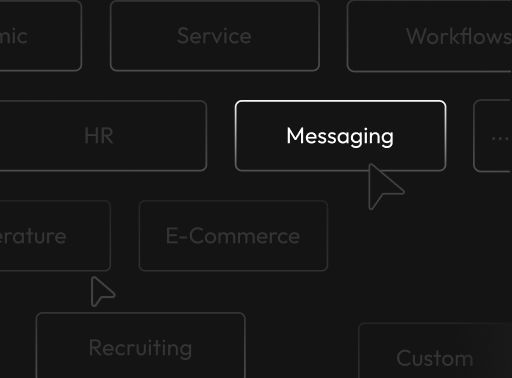

Custom Enterprise Domains
CRM, cloud services, and more — built to the same standard.
From First Call to Training Loop
Step 1 Define Goals
Target behavior, domain, task complexity, success metrics.
Step 2 Build the Environment
Full-stack simulation: API, database, data seeding, GUI, MCP-compatible interfaces.
Step 3 Generate Tasks & Evaluation
Thousands of tasks across six complexity tiers. Multi-dimensional rubrics. Validated for solvability and diversity.
Step 4 Integrate & Scale
Infrastructure-ready containers. Plug into your training stack. Ongoing support included.
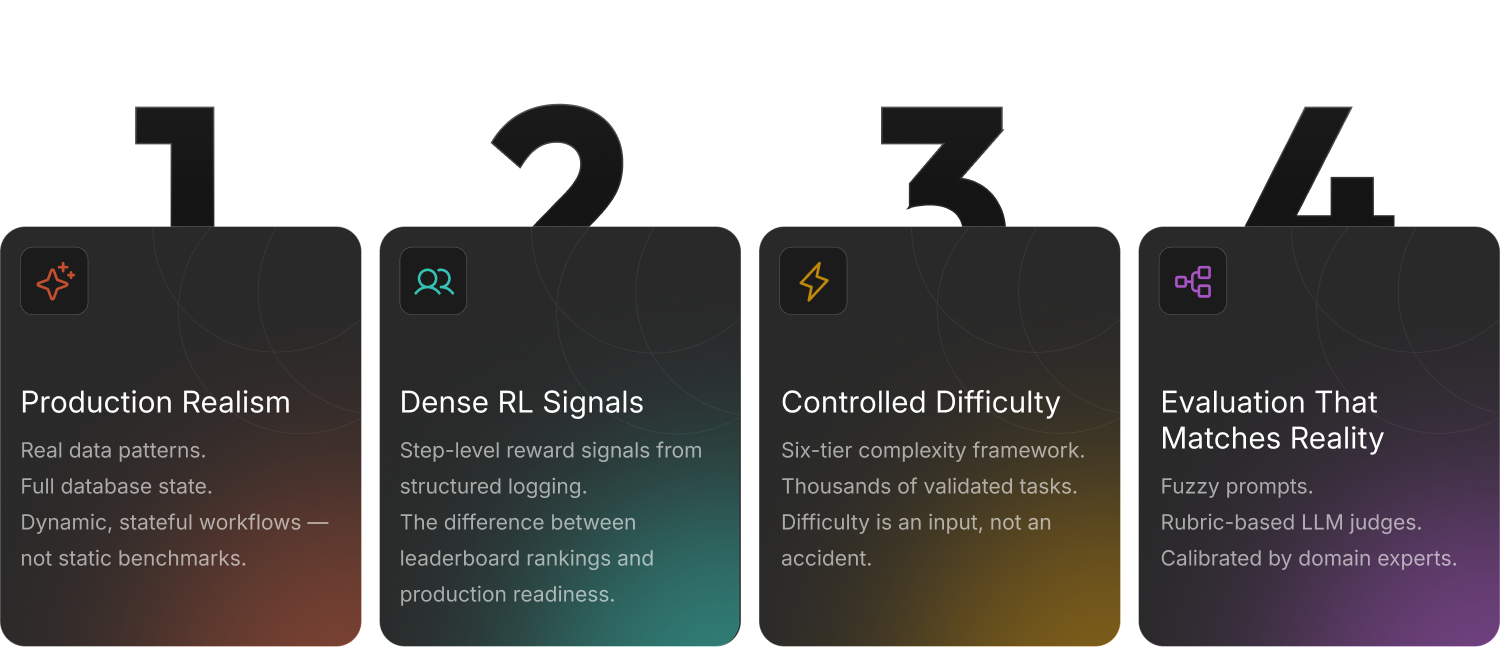
Why Teams Choose Abaka

Two Ways to Evaluate Real-World AI Agents
Judgment-Based Workflow Evaluation
Tests multi-step business workflows requiring prioritization and decision-making.
Success is about exercising sound judgment — not just completing steps.
Deterministic System Execution
Tests whether agents interact with software accurately and verifiably.
Every result is checked directly against system state.

Strong agents need both.
Judgment for ambiguous, human-centered tasks. Precision for deterministic system actions. Evaluating only one side gives an incomplete picture.
Ready to Build
Your RL Training Environment?
The environment layer is no longer optional — it is foundational.
Talk to an Expert