
EditReward is Abaka AI’s new human-aligned reward model built to solve the biggest bottleneck in AI image editing: the lack of a reliable, interpretable, high-fidelity “judge.” Trained on 200K+ expert-annotated preference pairs and designed with multidimensional reasoning, EditReward outperforms GPT-5 and GPT-4o on GenAI-Bench and AURORA-Bench, enabling the entire open-source ecosystem to build higher-quality, instruction-faithful generative models.
Blogs
2026-02-03/Research
EditReward: Outperforming GPT-5 in AI Image Editing Alignment

Yuna Huang,Marketing Curator
EditReward: A High-Fidelity Reward Engine for Human-Aligned Image Editing
The Architect’s Dilemma: The Trouble with Current Judges
The pursuit of the 'perfect' AI image editor has reached a critical pivot point. While frontier models consistently deliver breathtaking, instruction-faithful results, many development teams find themselves hitting a performance glass ceiling. This gap is no longer defined by raw compute or the number of model parameters; it is a fundamental crisis of alignment infrastructure.
Even for the most sophisticated engineering teams, the primary barrier to matching the world's leading generative models lies in the unreliability of current evaluation rewards. In today’s competitive landscape, the industry is plagued by three specific technical hurdles that prevent models from reaching production-grade precision:
Semantic Blindness of Coarse Metrics: Standard rewards like LPIPS or CLIP-score are often "blind" to semantic nuance. They fail to distinguish between a visually similar image that ignores the editing instruction and one that captures the intent perfectly.
The "VLM-as-a-Judge" Reliability Gap: Relying on general-purpose Vision-Language Models (VLMs) to score edits introduces significant noise. These models frequently suffer from "positional bias" and can hallucinate success in failed edits, providing a flawed compass for model optimization.
The High-Fidelity Data Deficit: Most current preference datasets are built on low-quality, inconsistent labels. Without expert-level calibration, the reward signals are too noisy to guide a model through the complex trade-offs between instruction fidelity and visual realism.
Without a high-fidelity critic to distinguish a "near-miss" from a "perfect hit," developers are forced to train on unverified data—limiting the model's ability to achieve true human alignment. To scale a world-class generative engine, the industry needs more than just bigger datasets; it needs a sophisticated "Expert Judge" to supervise synthetic data generation and drive Reinforcement Learning from Human Feedback (RLHF).
Bridging the Gap: From Evaluation to Evolution
Recognizing that superior model performance is a direct byproduct of superior reward signals, Abaka AI, in collaboration with Tiger AI Lab and the 2077AI research initiative, introduces EditReward.
We have moved beyond the limitations of passive benchmarking to build a commercial-grade reward engine that functions as an active data supervisor. By integrating academic rigor with industrial-scale data engineering, EditReward provides the surgical feedback loop required to break through the industry's current alignment bottleneck.
The EditReward Framework: Engineering a Precision "Judge"
To overcome the inherent limitations of standard evaluation, we have engineered a two-stage pipeline that bridges the gap between raw data and actionable reward signals. By combining expert-led data curation with a sophisticated training architecture, EditReward provides the surgical feedback loop required for high-fidelity image editing.
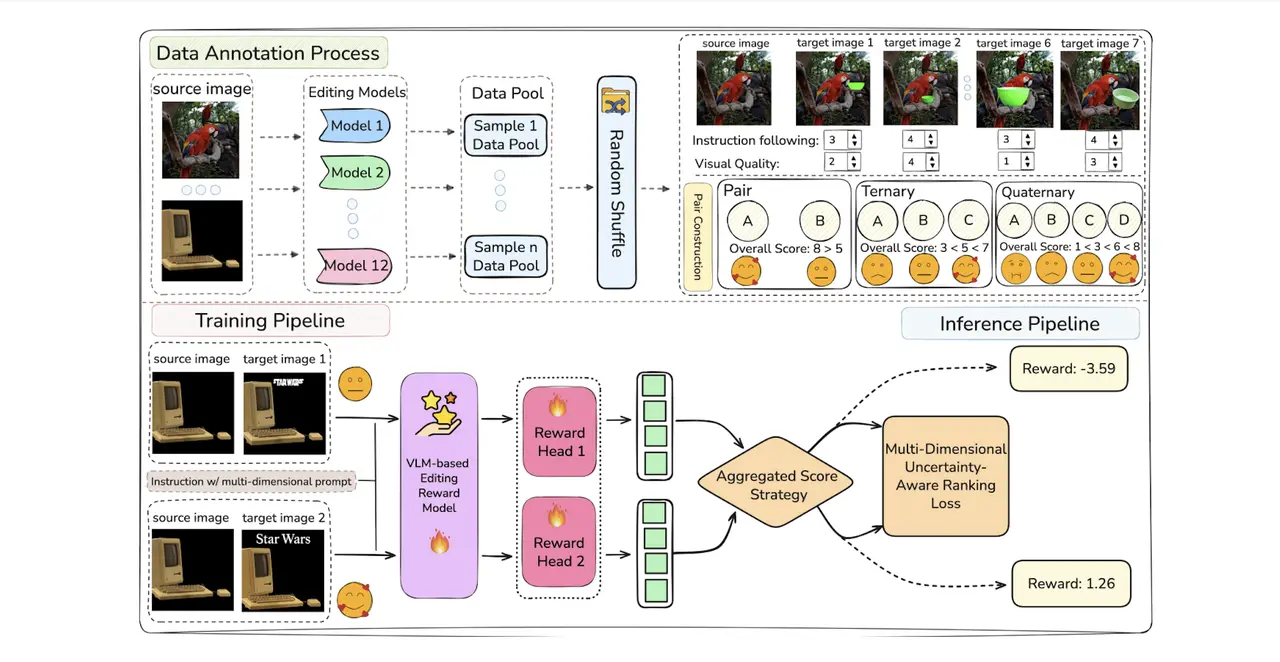
High-Fidelity Data Construction & Expert Annotation
The effectiveness of a reward model is fundamentally capped by its training foundation. We moved beyond noisy, automated labeling to build EDITREWARD-DATA, a large-scale preference dataset defined by expert precision.
Multi-Task Training & Inference Pipeline
The EditReward architecture is designed to translate human preference into a robust, probabilistic reward signal.
VLM-Based Multi-Head Architecture: We utilize a powerful Vision-Language Model (VLM) backbone that features dual reward heads to independently compute scores for both instruction fidelity and visual realism.
Aggregated Score Strategy: During training, separate dimensional scores are synthesized using a custom aggregation strategy, ensuring the model balances the trade-off between following a prompt and maintaining a realistic image.
Uncertainty-Aware Ranking Loss: A key technical breakthrough is the use of Multi-Dimensional Uncertainty-Aware Ranking Loss. By modeling rewards as Gaussian distributions, the system accounts for human subjectivity and label noise, resulting in a significantly more stable and accurate reward signal.
The EditReward framework replaces binary "good/bad" judgments with a Multi-Dimensional Uncertainty-Aware Ranking system. By disentangling Instruction Following from Visual Quality, and modeling scores as a probabilistic distribution, EditReward provides a surgical signal that captures the subtle interplay between a user's intent and physical plausibility.
Engineering the "Expert Eye": A Sovereign Infrastructure for Data Intelligence
EditReward is not merely a model; it is the manifestation of a sovereign data engineering philosophy. While the industry often treats data as a commodity, we treat it as an infrastructure of intelligence. At the core of this infrastructure lies EDITREWARD-DATA, a foundational corpus of over 200,000 expert-annotated preference pairs.
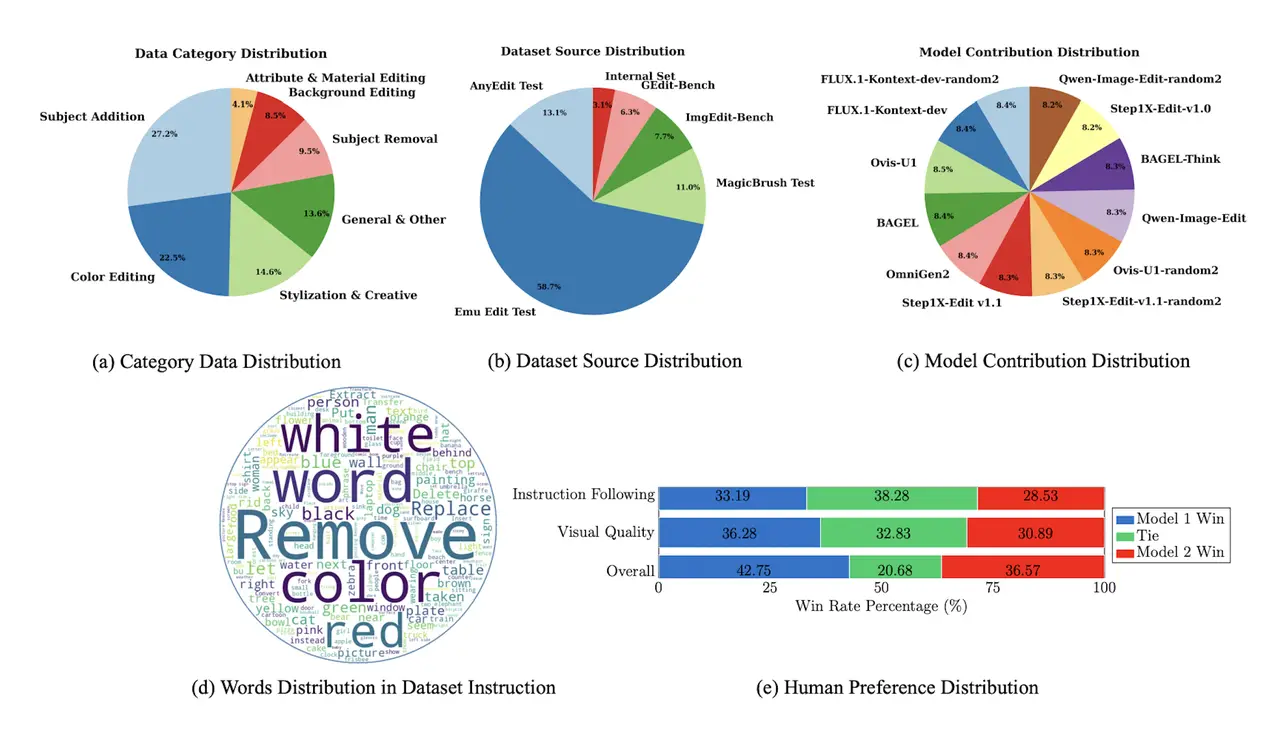
The Science of High-Fidelity Data Construction
Our solution transforms the "wild west" of crowdsourced data into a precision-engineered environment. We address the data quality gap through a specialized three-pillar construction strategy:
The Gold-Standard Expert Protocol: We have replaced low-fidelity crowdsourcing with an elite annotation engine. Every data point is curated by domain experts trained in a rigorous, standardized protocol, ensuring a level of semantic nuance and inter-annotator agreement that traditional labeling services cannot replicate.
Disentangled Dimensionality: Conventional reward models collapse complex visual reasoning into a single, opaque score, offering no actionable insight. EditReward's framework independently evaluates the "Semantic Delta" (Instruction Following) and the "Perceptual Anchor" (Visual Quality). This allows developers to diagnose whether a model failure is a breakdown in linguistic comprehension or a deficit in physical rendering.
Agnostic Architectural Diversity: To ensure universal applicability, we sourced candidates from 12 distinct state-of-the-art models, including Step1X-Edit and Flux-Kontext. This prevents the "judge" from inheriting the specific biases of any single architecture, creating a fair and robust critic for any generative pipeline.
The Abaka AI Advantage: Scaling Reward Intelligence
Abaka AI provides the industrial-scale engine that turns academic research into production-ready solutions. Our contribution centers on three technical breakthroughs that redefine how reward models interact with complex human preferences:
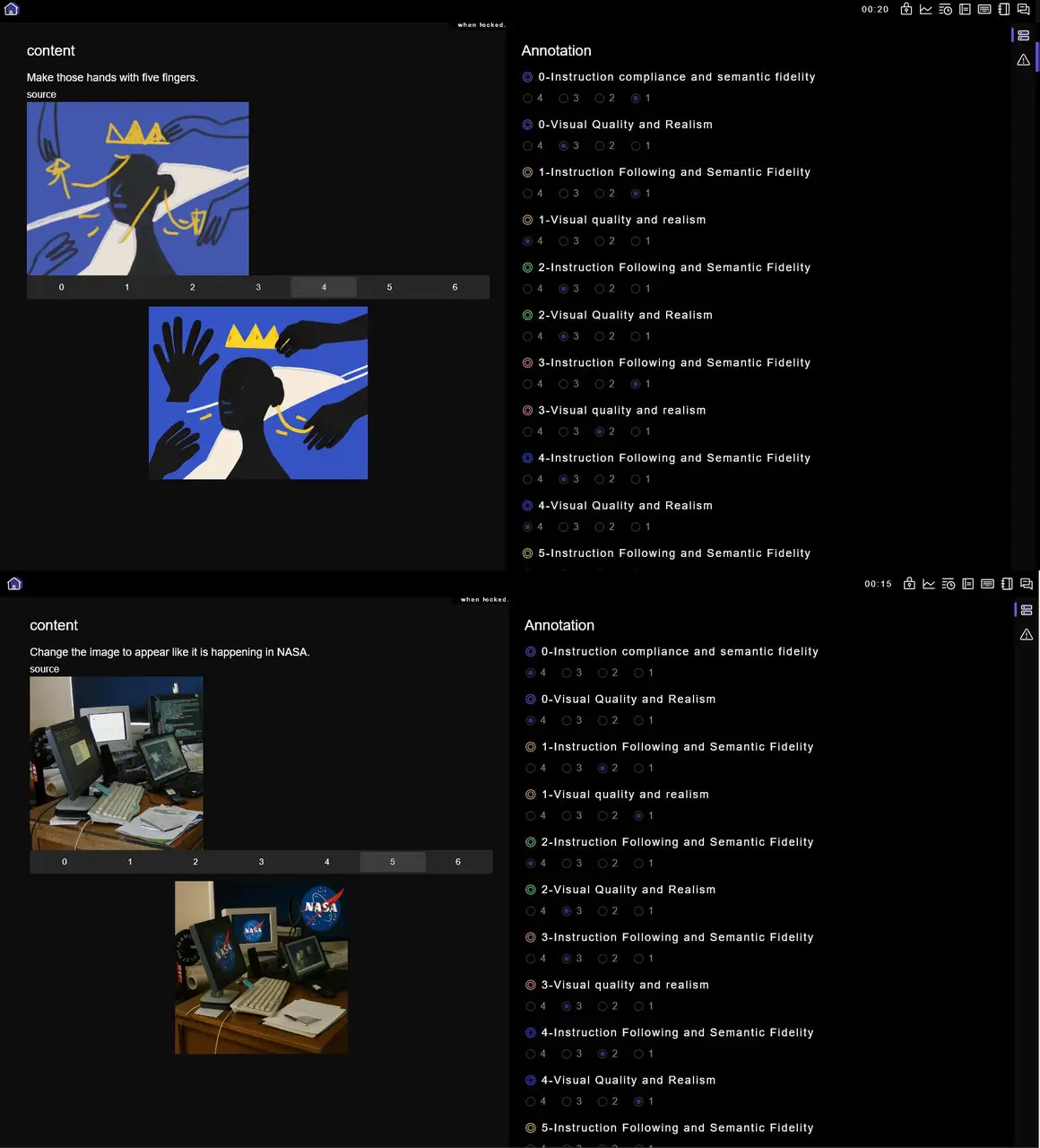
Probabilistic "Uncertainty-Aware" Ranking: Instead of assigning a fixed scalar, EditReward models its judgment as a Gaussian distribution. This allows the engine to mathematically recognize and "understand" its own uncertainty when faced with ambiguous edits or subjective human tastes.
Proprietary "Tie-Disentanglement" Strategy: In high-performance editing, models often produce results that are nearly identical in quality. While standard models fail to extract value from these "ties," our strategy decomposes them into granular training samples based on dimensional advantages. This allows us to extract learning signals from the most challenging edge cases where others see only noise.
Surgical Alignment Signal: By leveraging our multi-dimensional ranking loss, we provide a reward signal with significantly higher resolution than any general-purpose VLM. For enterprises, this means a faster path to model convergence and a more efficient RLHF (Reinforcement Learning from Human Feedback) process.
By establishing this high-fidelity data foundation, Abaka AI equips developers with the high-resolution feedback loop required to move beyond trial-and-error and toward a predictable, scalable path to frontier-level performance.
Performance That Speaks for Itself
The synergy between industrial-scale data engineering and academic rigor has yielded results that redefine the state-of-the-art (SOTA) in AI evaluation. In exhaustive benchmarking, EditReward consistently bridges, and in several key metrics, leaps over, the gap between standard evaluators and proprietary giants.
Redefining the Industry Benchmark
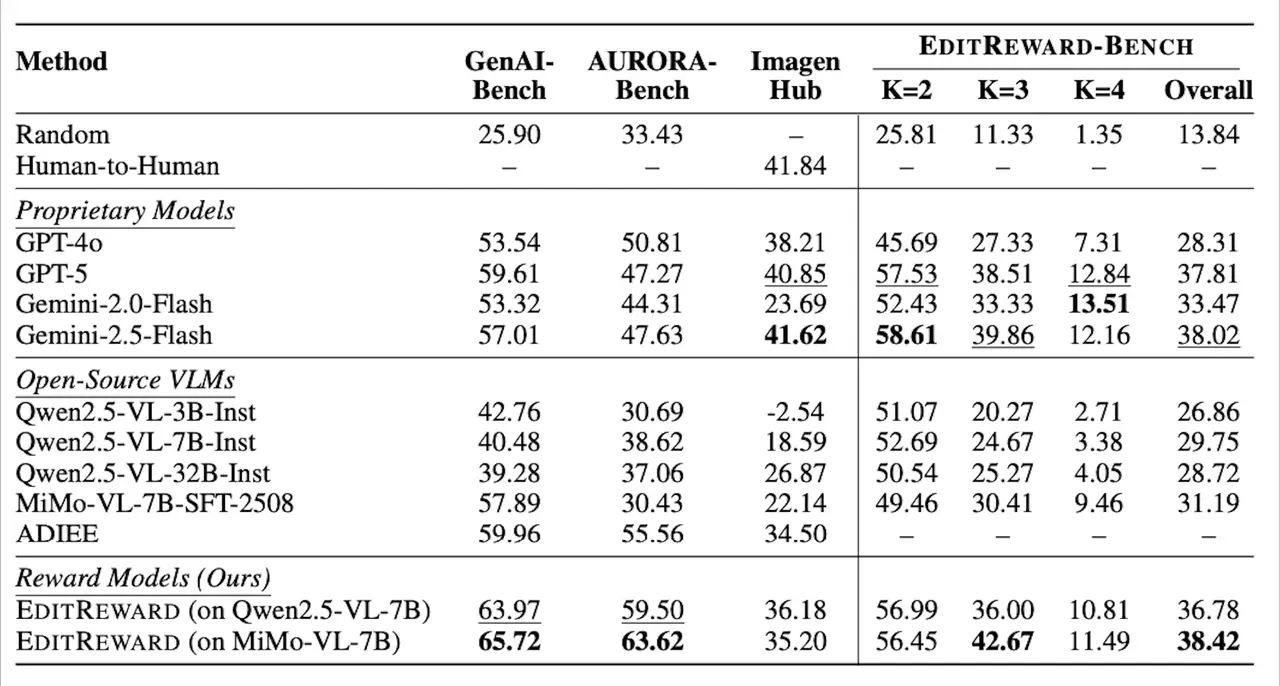
EditReward’s performance underscores a significant shift in alignment accuracy. On GenAI-Bench, EditReward achieved a human-correlation score of 65.72, fundamentally outclassing proprietary models like GPT-5 (59.61) and GPT-4o (53.54). This dominance extends to AURORA-Bench, where the model recorded a score of 63.62, marking a substantial gain over previous industry standards.
These are not merely academic victories; they represent a validation of a high-fidelity data strategy. This performance has established EditReward as a trusted infrastructure component for the world’s leading AI labs. Today, our methodology and data insights are being integrated into the research pipelines of teams at Gemini (Google DeepMind), Apple, and Salesforce, signaling a global industry shift toward specialized, high-resolution reward modeling.
The "Data Supervisor" Advantage: Coaching the Champion
The ultimate utility of a judge is not just to declare a winner, but to coach a champion. EditReward transcends the role of a passive benchmark to function as an active Data Supervisor, identifying the high-signal "gold" within massive, unverified data lakes.
To demonstrate this, we utilized EditReward to "prune" the noisy ShareGPT-4o-Image dataset. By filtering the collection down to the top 20,000 high-fidelity samples—less than half of the original volume—and training the open-source Step1X-Edit on this refined subset, the model’s performance underwent a phase shift. The overall score on GEdit-Bench rose from 6.7 to 7.1, placing a lean model on par with industrial heavyweights like Doubao-Edit.
This experiment crystallizes a fundamental shift in the AI development paradigm: High-quality reward signals are the most valuable currency in model training. In an era of infinite, noisy data, the ability to selectively amplify quality is the only viable path to reaching frontier-level performance while maintaining compute efficiency. EditReward provides the surgical precision required to turn that quality into a competitive edge.
The Future of Alignment: Precision at Scale
As the industry pivots toward more complex multimodal interactions, the demand for human-aligned feedback will only intensify. Whether you are an engineer seeking to refine a generative pipeline or a researcher pushing the frontiers of RLHF, EditReward offers the surgical precision and reliability necessary for the next leap in artificial intelligence. By bridging the gap between raw data and actionable intelligence, we enable the creation of models that are fundamentally more faithful, realistic, and trustworthy.
Ready to Explore the Data?
We invite you to join the growing community of researchers and developers utilizing high-fidelity alignment signals to drive their breakthroughs.
Dive into the Research: Visit our Project Page to explore the full paper, benchmarks, and the EDITREWARD-DATA corpus.
Power Your Breakthrough: Contact Abaka AI Data Expert today to learn how our high-fidelity data engine and commercial reward solutions can accelerate your model's journey to frontier-level performance.
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.