What Are RL Environments for AI Agents? | Enterprise Training
Longtian Ye,Member of Technical Staff
RL environments for AI agents are structured, stateful systems that simulate real software workflows, enabling agents to interact with tools, APIs, and evolving data to complete multi-step tasks. They are the missing layer between static benchmarks and real-world enterprise deployment.
What Are RL Environments for AI Agents? The Missing Layer for Enterprise Workflows
An agent receives a simple request: "I think I recently liked a post about a temple. What are its opening hours?"
For a human, this takes thirty seconds — open the app, scroll through liked posts, find the article, scan for the answer. For an AI agent, it is a multi-step reasoning chain: verify authentication, navigate to the user profile, open liked posts, identify the correct post by topic, open its detail page, and extract specific information from unstructured text. Each step depends on the last. Skip any, and the agent either fails or hallucinates.
Benchmarks vs Real Workflows: Why Agents Still Fail
AI agents are evolving from conversational assistants into systems that operate inside real software — navigating enterprise tools, executing multi-step workflows, and making decisions under ambiguity. But the infrastructure to train and evaluate them has not kept pace.
Most agent benchmarks today are static: fixed prompts, predetermined answers, single-turn interactions. They measure whether an agent can answer a question, not whether it can do work. Real enterprise workflows demand stateful environments where actions have consequences, data is messy, and correct answers depend on context that must be actively discovered. The bottleneck here is no longer the model. It is the environment.
RL Environments for Enterprise AI Agents: What We Built
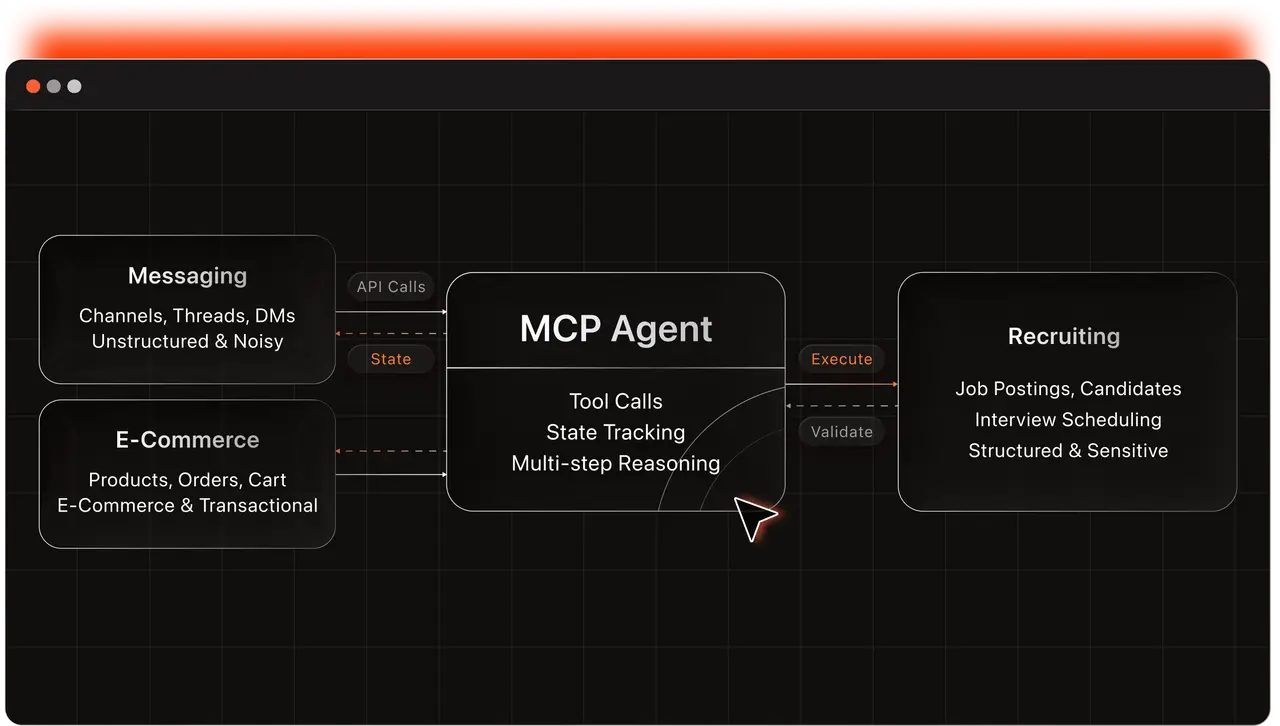
Abaka AI builds full-stack simulations of real SaaS applications as structured RL environments. Each environment is a working digital system with its own API layer, relational database, and persistent state that evolves through agent interactions.
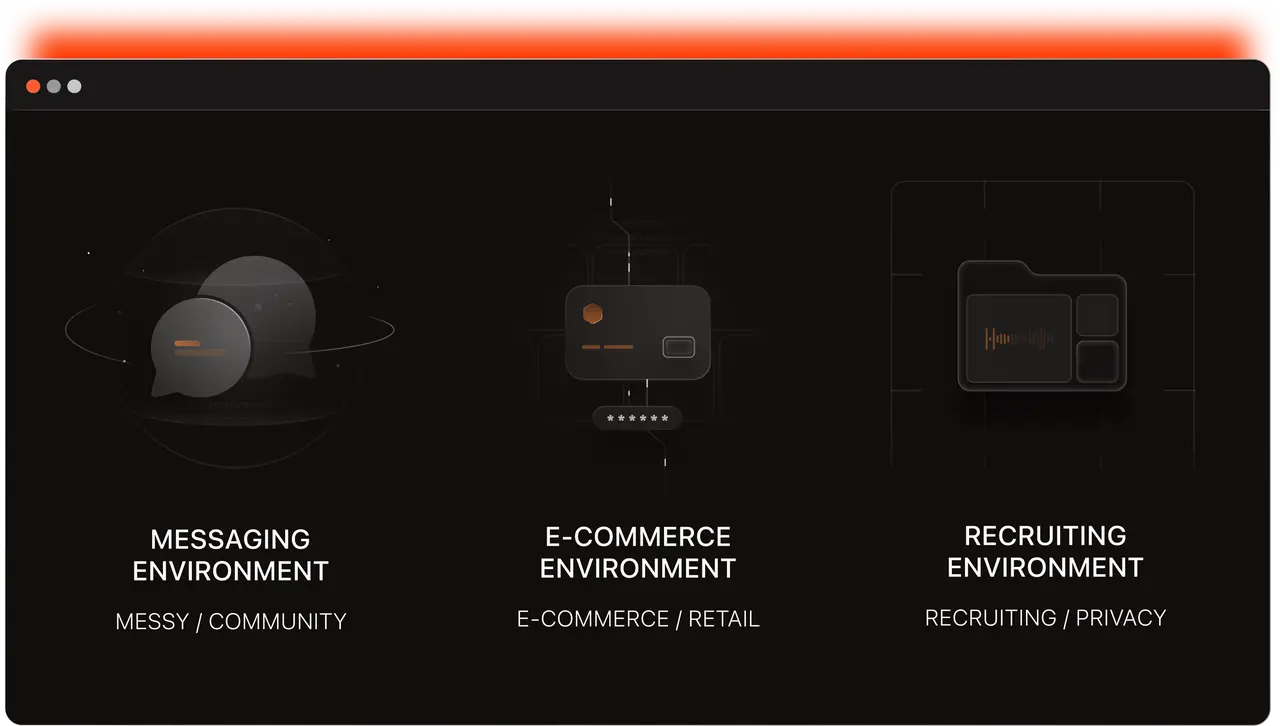
We currently operate three classes of environments:
Enterprise Messaging Environment — Unstructured & Noisy. A production-style enterprise messaging workspace. Agents navigate channels, threads, reactions, and direct messages. Data is seeded from open-source community conversations to preserve the messiness of actual workplace communication.
E-Commerce Environment — Transactional & Structured. A full-stack online marketplace with product catalog, user accounts, order history, and inventory. Agents search products, compare prices, manage carts, and track orders — reasoning across structured listings and transactional state.
Recruiting Environment — Structured & Sensitive. A recruiting pipeline built from de-identified internal candidate data. Agents manage job postings, candidate stages, and interview scheduling with strict privacy controls.
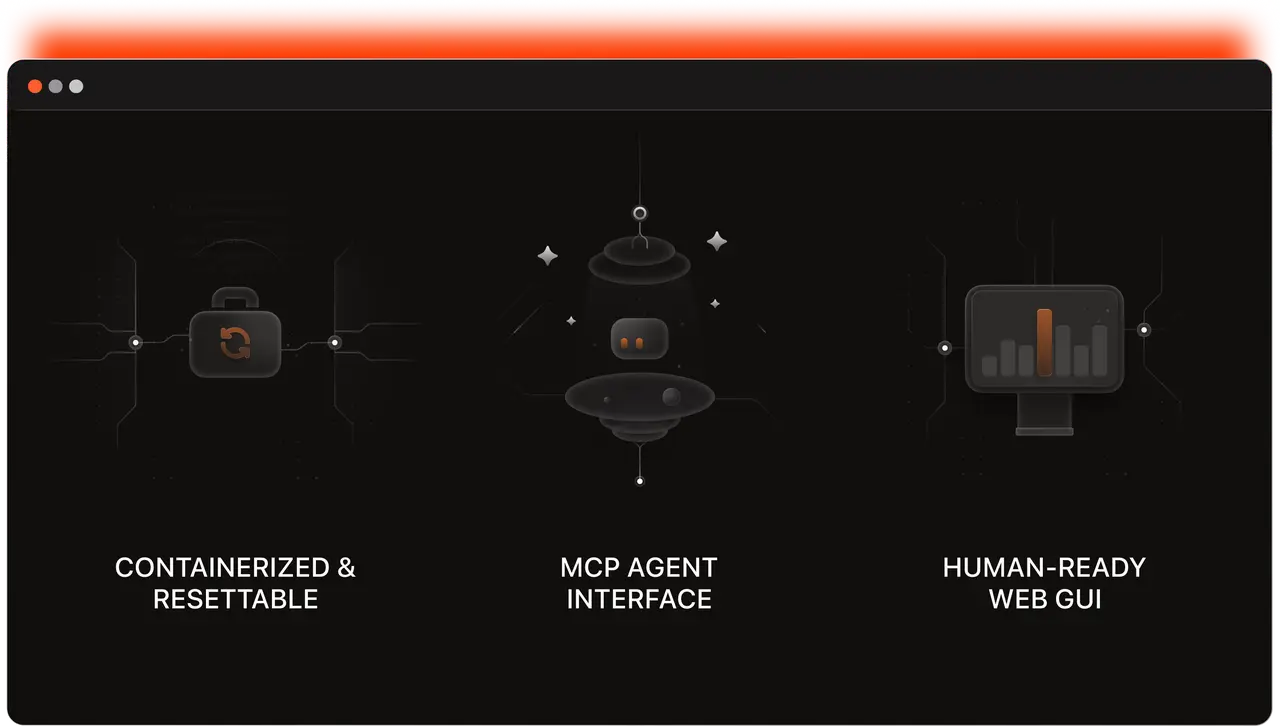
Each environment is fully sandboxed, deterministically resettable, and exposes both a web GUI and a complete API/tool interface compatible with MCP-based agent runtimes.
How We Evaluate AI Agents in RL Environments
Most benchmarks produce a single pass/fail score at the end. That is enough to rank models on a leaderboard, but insufficient for RL training, where you need signal at every step — what went right, what went wrong, and where the agent's reasoning diverged from a sound strategy.
We solve this with dual-lens evaluation :
Hard rubrics areautomated checks that query the environment's database to verify the final state is correct
Soft rubrics involvinghuman annotators review the agent's trajectory to assess process quality — did it search before guessing, take an efficient path, and handle ambiguity responsibly?
This hybrid approach avoids the false precision of purely automated metrics while maintaining reproducibility where it matters.
The foundation of this pipeline is dense structured logging, which also produces the RL training signal. Every session captures a complete trace: each API call, tool invocation, state transition, and intermediate result. This is what hard rubrics query, what soft rubrics annotate, and what training loops consume for step-level reward shaping. When an agent fails, the logs show exactly where in the reasoning chain it diverged, not just that it produced the wrong answer.
Because the environments are containerized, they are infrastructure-friendly by design — the entire evaluation pipeline scales horizontally: spin up N parallel instances, run episodes, collect structured traces, reset, repeat. The result is engineering infrastructure designed for production training loops.
Scaling Up: Our Automated Task Factory
However, dense reward signals are not effective if every task is a trivial lookup — we need controlled difficulty, grounded scenarios, and guaranteed solvability.
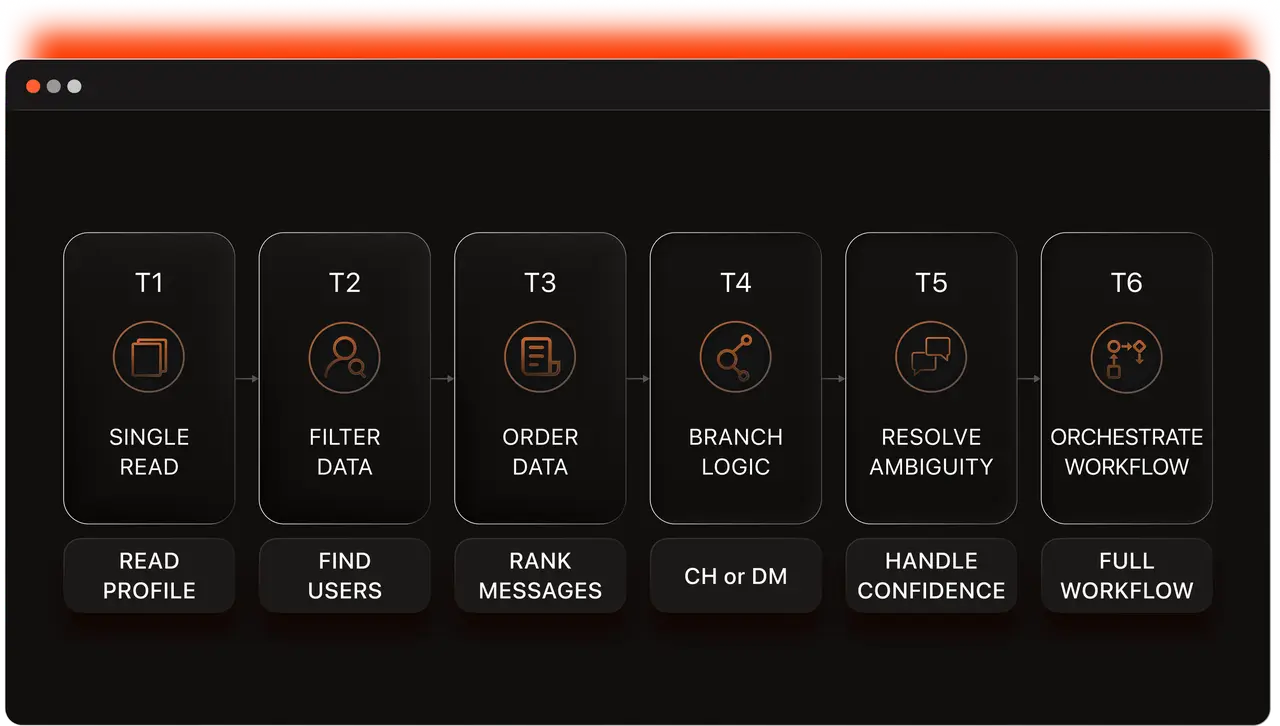
Six-Tier Complexity Framework
We designed a six-tier task complexity framework that serves as the structural backbone of our task distribution. Each tier maps to distinct cognitive demands an agent must exhibit, from simple retrieval to long-horizon orchestration under ambiguity.
At the simple end, a T1 task tests a single API call — reading a user profile. At the complex end, a T6 task chains dozens of steps across multiple tools, requiring the agent to plan, branch, and recover from errors along the way. The framework ensures uniform difficulty distribution: coverage across tiers, environments, and API surfaces is specified upfront.
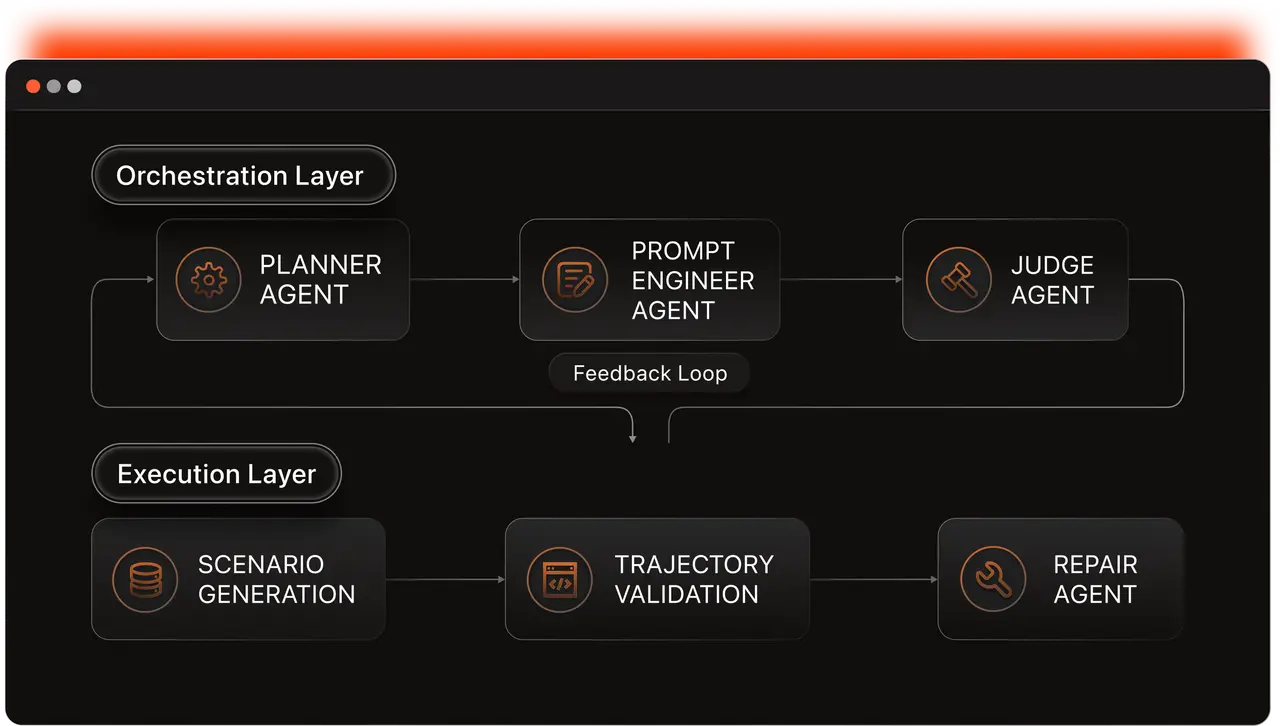
Multi-Agent Generation Pipeline
This is not just naïve prompt templating. We built a multi-agent pipeline that enforces quality, diversity, and correctness at every stage.
A Planner maps coverage gaps across tiers, environments, and API surfaces — ensuring no clustering around easy tasks or familiar patterns. A Prompt Engineer generates task specifications constrained by the Planner's targets. A Judge reviews each output for quality, consistency, and solvability. Together they enforce six properties that make the pipeline produce tasks suitable for RL training:
Uniform distribution. The Planner enforces coverage across all six tiers, all environments, and all API surfaces. Every batch has controlled difficulty ratios — no accidental clustering.
Data-driven scenario design. Tasks are grounded in actual environment data — real product catalogs, real message threads, real candidate pipelines. The scenario context comes from the data itself rather than synthetic toy examples.
Cross-application tasks. The system generates tasks that span multiple environments — "find a message about a product, then check its price on the e-commerce platform" — that tests the kind of tool-switching workflows that enterprise agents actually face.
Closed solution space. Every generated task is validated to have a deterministic answer within the environment's current state. The Judge and a downstream trajectory validator ensure no task asks for something the environment cannot resolve. This is what makes RL reward signals reliable — there is always a ground truth.
Controllable difficulty. Difficulty is an input parameter, not an emergent property. Tier definitions constrain the Prompt Engineer's output — specifying reasoning steps, operation types, and degree of ambiguity.
Fuzzy user instructions. Tasks are generated with varying levels of instruction specificity, from precise API-like commands to vague natural-language requests ("find that thing my colleague mentioned last week"). This tests the agent's ability to disambiguate and plan under uncertainty — a core capability gap in current agent systems.
The pipeline is also self-improving: each generation batch trains the next. Failed tasks feed back to the Judge with diagnostics, and the Judge's improved criteria propagate to subsequent batches. The result is a system that gets better at generating tasks the more it runs.
Looking Forward
We are actively expanding into e-commerce, CRM, cloud services, and additional enterprise categories. Each new environment follows the same principle: realistic data, structured state, complete API coverage, and rigorous evaluation.
The shift from static benchmarks to structured RL environments changes what agents can learn and how reliably we can measure them. For teams building agents that operate in real enterprise software, the environment layer is no longer optional. It is foundational.
If you are building AI agents for enterprise workflows, tool-use training, or agent evaluation, Abaka AI provides the environments and evaluation frameworks to move from demo to deployment.
FAQs
Why are benchmarks not enough for AI agents?
Benchmarks test static answers, while real AI agents must complete multi-step workflows using tools and evolving data. RL environments capture this complexity, benchmarks do not.
How do RL environments improve AI agent training?
RL environments provide step-level feedback and realistic workflows, enabling agents to learn planning, tool use, and decision-making beyond single-turn responses.
What makes a good RL environment for enterprise AI agents?
A good RL environment for enterprise AI agents includes realistic data, full API or tool access, deterministic evaluation, and scalable infrastructure. It should simulate real workflows, support multi-step reasoning, and provide reliable feedback signals for training and evaluation.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.



'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)