Training an AI model is not just about algorithms but about building the right data pipeline, from collection and labeling to evaluation, that ultimately determines whether an AI system performs reliably in the real world.

Training an AI model is not just about algorithms but about building the right data pipeline, from collection and labeling to evaluation, that ultimately determines whether an AI system performs reliably in the real world.
“Nobody phrases it this way, but I think that artificial intelligence is almost a humanities discipline. It’s really an attempt to understand human intelligence and human cognition.”
—Sebastian Thrun
AI and humanity have already entered a symbiotic relationship, where as much as we learn from it in order to enhance our knowledge, it also learns from us to improve. As Sebastian Thrun said, A is less about pure engineering and more an attempt to reverse-engineer human cognition. By trying to replicate our intelligence, it forces a deeper understanding of human empathy, creativity, and what it means to be human.
Yet, artificial intelligence systems are only as powerful as the data they learn from. Behind every high-performing model, there is a structured pipeline of training data services that makes it possible. This is true whether we are talking about computer vision, natural language processing, robotics, or multimodal AI. In recent years, the AI community has shifted toward a data-centric perspective, clearly emphasizing improvements to datasets rather than solely refining models (Zha et al., 2025). This shift reflects a simple reality: even the most sophisticated models cannot overcome poor or biased training data.
Yet many teams still underestimate what “AI training data services” actually include.
As much as the following are crucial, It’s not just labeling images or tagging text. Rather it’s a multi-stage lifecycle that spans data collection, curation, annotation, validation, augmentation, and model evaluation. Each stage directly impacts model performance, generalization, fairness, and reliability.
In this guide, we break down what AI training data services really involve in 2026.
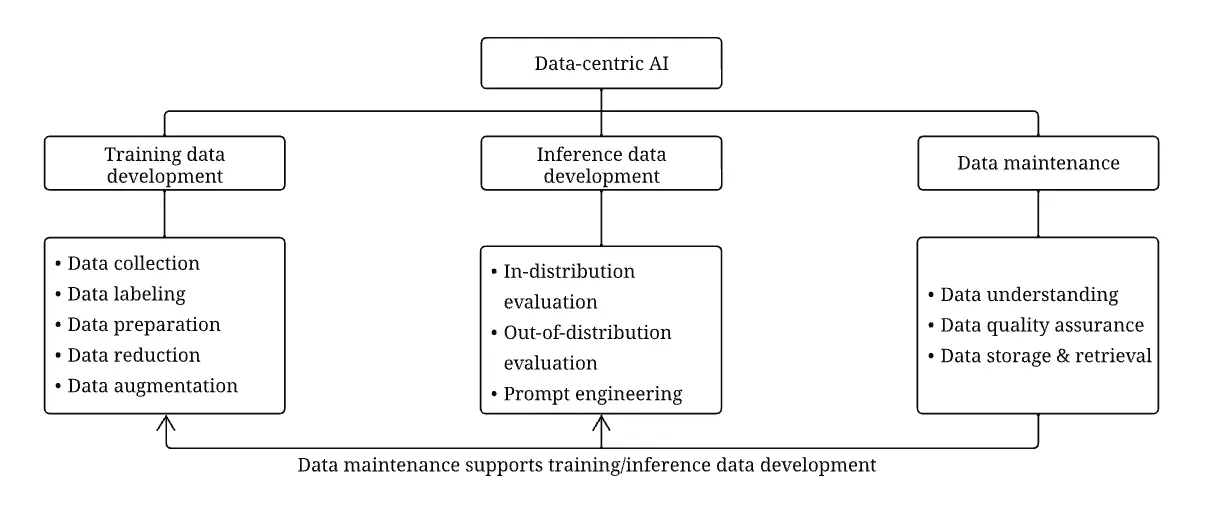
Building a production-ready AI system requires far more than collecting a dataset and training a model. Modern AI pipelines include multiple structured stages that ensure data quality, reliability, and scalability.
These stages typically include:
Data collection
Data cleaning and preparation
Data labeling and annotation
Data augmentation and synthetic data
Data quality assurance
Model evaluation and validation
Each stage plays a distinct role in ensuring that models learn meaningful patterns rather than noise.
The first step in building AI systems is gathering relevant data from real-world environments.
Data may come from many sources, including:
Sensors and IoT devices
Web data and APIs
enterprise databases
public datasets
user interactions and behavioral logs
For example, autonomous vehicle systems collect large volumes of sensor data, while recommendation systems rely on user interaction logs.
However, collecting data also raises issues of bias, representation, and ethical data use. Poorly designed collection practices can lead to datasets that fail to represent real-world conditions or user populations.
Research has shown that AI datasets are often collected once and reused for different applications, which can introduce bias or limit generalization across domains (Inel, Draws, & Aroyo, 2023). Because of this, modern AI teams increasingly treat data collection as an iterative process, continuously measuring reliability and updating datasets.
Best practices for AI data collection include:
defining clear modeling objectives before collecting data
ensuring diversity across populations and environments
automating data acquisition where possible
validating and cleaning data continuously
maintaining strong privacy and ethical standards (AWS Builder, 2024)
Structured data collection processes allow organizations to create datasets that are both scalable and representative of real-world conditions.
Raw datasets are rarely usable as-is. They often contain duplicates, corrupted files, irrelevant samples, inconsistent formats, or noisy inputs.
Data preparation pipelines address these problems through cleaning, transformation, and feature engineering.
According to IBM, preprocessing typically includes:
correcting missing or inconsistent values
transforming raw data into machine-readable formats
structuring features that algorithms can learn from effectively (IBM, 2024)
Data scientists also divide datasets into training, validation, and test sets to ensure models generalize to unseen data. This step is critical for preventing overfitting and accurately evaluating model performance.
Because preprocessing often consumes a large portion of machine learning development time, many organizations rely on specialized training data services to manage these pipelines efficiently.
Data annotation is the process of attaching meaningful labels to raw data so machine learning models can learn patterns.
Examples include:
labeling objects in images for computer vision
annotating speech transcripts for voice recognition
tagging sentiment in text data
labeling actions in robotics datasets
This process is one of the most labor-intensive steps in AI development. It often requires human annotators who provide contextual understanding that machines cannot replicate.
Research highlights that labeling is essential for aligning machine learning models with human expectations. Without labeled data, models may struggle to produce meaningful predictions or align with real-world tasks (Zha et al., 2025).
To improve labeling efficiency, modern AI pipelines use a variety of strategies, including:
crowdsourced annotation
semi-supervised labeling
active learning workflows
weak supervision techniques
reinforcement learning from human feedback (RLHF)
These hybrid approaches combine human expertise with algorithmic assistance, enabling large datasets to be labeled at scale while maintaining quality.
Even large datasets may lack sufficient examples of rare or edge-case scenarios.
To address this challenge, organizations use data augmentation and synthetic data generation.
Augmentation techniques include:
rotating or modifying images
adding noise to audio samples
generating paraphrases for text datasets
More advanced approaches involve generative models such as GANs and diffusion models, which can create entirely new synthetic training examples (Zha et al., 2025).
Synthetic data helps solve several key problems:
data scarcity
privacy restrictions
expensive real-world data collection
As generative AI technologies improve, synthetic datasets are becoming an increasingly important component of AI training pipelines.
High-quality data is the foundation of reliable AI systems.
If datasets contain errors or biases, those issues propagate directly into model predictions. Researchers refer to these cascading problems as “data cascades,” where early data issues cause downstream failures across AI systems (Zha et al., 2025).
Quality assurance processes therefore include:
annotation consistency checks
inter-annotator agreement metrics
bias detection and mitigation
dataset documentation and versioning
Responsible AI practices also require detailed documentation of dataset provenance. Recording how data was collected, annotated, and modified helps teams identify factors that may influence model outcomes (Inel, Draws, & Aroyo, 2023).
This type of documentation improves transparency and enables better auditing of AI systems.
The final stage connects data directly to model performance.
Model evaluation services test trained models against validation datasets to measure accuracy, recall, precision, robustness, and bias. More advanced evaluations may include stress testing for adversarial conditions, out-of-distribution analysis, or fairness audits.
Crucially, evaluation feeds back into earlier stages. If models underperform in certain scenarios, new data must be collected, annotated, or rebalanced.
In mature AI organizations, training data services and model evaluation are tightly integrated into a closed loop.
Many AI projects fail not because of model architecture, but because of weak data infrastructure.
Fragmented workflows—where one vendor collects data, another annotates it, and internal teams evaluate it—often lead to misalignment, unclear accountability, and quality gaps.
End-to-end AI training data services create consistency across the lifecycle. They enable traceability, faster iteration, and stronger alignment between data strategy and model objectives.
For organizations building AI products rather than prototypes, this integration becomes a competitive advantage.
Building reliable AI systems requires expertise across the entire data pipeline.
Abaka AI provides end-to-end AI training data services, including:
large-scale data collection pipelines
expert data annotation across modalities
dataset curation and quality assurance
model evaluation and benchmarking
By combining human expertise with scalable infrastructure, Abaka helps AI teams build datasets that are accurate, diverse, and production-ready.
If you’re building or scaling AI systems and need high-quality training data services, Abaka AI can help.
Contact us to learn how we can support your AI development with scalable, expert-driven data pipelines.
AI training data services include the processes used to collect, curate, annotate, validate, and evaluate data for machine learning models. These services transform raw information into structured datasets that improve model performance.
Data collection defines the foundation of an AI system. If the collected data is biased, incomplete, or unrepresentative, model performance will suffer regardless of training techniques.
Data curation involves cleaning and organizing raw data before labeling, while annotation assigns structured labels or meaning to curated data for model training.
Yes. As models encounter new scenarios, data pipelines must evolve. Continuous data collection, re-annotation, and evaluation are necessary to maintain performance in dynamic environments.
Inel, O., Draws, T., & Aroyo, L. (2023). Collect, measure, repeat: Reliability factors for responsible AI data collection. Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, 11.
Hind, M., et al. (2020). Experiences with improving the transparency of AI models and services. Extended Abstracts of the CHI Conference on Human Factors in Computing Systems.
Zha, D., et al. (2025). Data-centric artificial intelligence: A survey. ACM Computing Surveys, 57(5), 1–42.
IBM. (2024). Training data preparation. IBM Think.https://www.ibm.com/think/topics/training-data
AWS Builder. (2024). The role of data collection in training AI and machine learning models. https://builder.aws.com/content/3513R9ayyVDGLGpPWGQNu9XDvs7/the-role-of-data-collection-in-training-ai-and-machine-learning-models
👉 AI-Powered Data Annotation Technologies: Improving Efficiency and Accuracy at Scale
👉 Is Your Data Annotation Contact Information Truly Secure?
👉 How AI Cleans Training Data: From Raw Inputs to Model-Ready Datasets
👉 AI-powered data Annotation technologies:efficiency and accuracy
👉 Auto Data labels in Machine Learning: Benefits, Limits, and Use Cases
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.
