How AI Cleans Training Data: From Raw Inputs to Model-Ready Datasets
Iskra Kondi,Growth Specialist
The quality of data plays a crucial role in the success of AI and machine learning models, often being as important as the algorithms themselves. Ensuring clean, reliable data is essential for accurate, consistent, and efficient model performance. Key techniques in data cleaning, such as handling missing data, removing duplicates, and ensuring data privacy, are explored in relation to their impact on AI outcomes. Research highlights that improving data quality leads to more effective and sustainable AI systems, holding the same importance as scaling models. The article also emphasizes the significance of maintaining data integrity and privacy, especially in regulated industries like finance, healthcare, and e-commerce.
How AI Cleans Training Data: From Raw Inputs to Model-Ready Datasets
Whether you’re an independent detective like Sherlock, an evil mastermind, or a mad scientist straight out of Back to the Future, there’s one thing you’ll always rely on: data—ideally, reliable and comprehensive data. In a world that might seem less thrilling at first glance, AI and data are quietly learning to coexist as the cornerstones of our daily reality. In the world of AI and machine learning, the quality of training data is just as critical as the algorithms themselves. Cleaning raw data and preparing it to be "model-ready" is crucial for ensuring machine learning models can deliver accurate, consistent, and reliable predictions.
This idea echoes a powerful finding in AI research: improving the data, not just scaling up the models, is the key to real-world success. Models perform more reliably, generalize better, and are more explainable when they are built on high-quality, trustworthy data. When organizations focus on making their data cleaner and more consistent, their models not only run more efficiently, but they also consume less computational power and experience fewer errors (Abbas, 2025).
This is especially true for large language models (LLMs) and generative AI (GAI), which significantly benefit from effective data cleaning techniques to prevent issues like hallucinations and to improve overall performance. Let’s take a closer look at how AI transforms raw data into usable training sets.
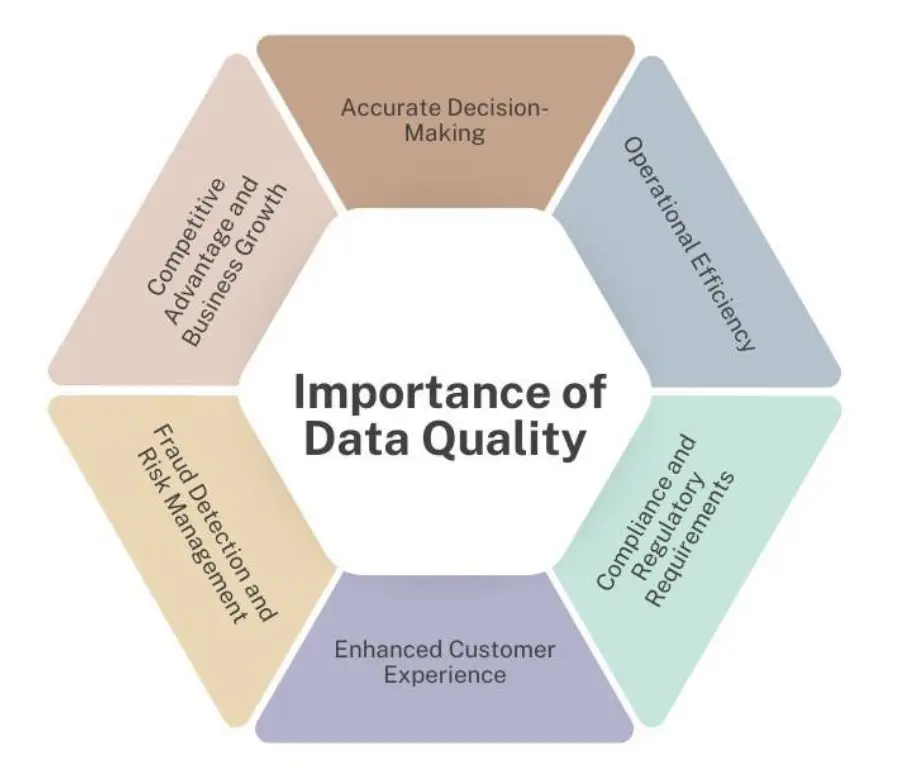
Importance of Data Quality Source: Cherekar, 2024
1. Understanding Raw Input Data
Raw data, often unstructured or semi-structured, can come from multiple sources such as databases, sensors, APIs, or manual entry. It can be noisy, inconsistent, or incomplete, like the modern version of a treasure map with half the clues missing, making it a real puzzle for machine learning models to decode. For example, images might be blurry, or text could contain typos and irrelevant symbols.
Key challenges include:
Inconsistencies: Variations in format, units, or measurement systems.
Noise: Unwanted symbols, emojis, or incorrect characters, especially in text and social media data.
Missing Values: Gaps in data that need to be addressed for the model to function properly.
2. Data Collection and Preprocessing
The first step is collecting data and transforming it into a consistent format. This often involves standardizing units and resolving format discrepancies. Preprocessing might include:
Tokenization: Breaking down text into smaller chunks, like words or sentences.
Noise Removal: Eliminating symbols like emojis, hashtags, or irrelevant Unicode characters.
Normalization: Converting everything into a consistent format (e.g., converting text to lowercase for uniformity).
3. Data Cleaning Techniques
Data cleaning is the core step in preparing data for use in training AI models. Various techniques are used to address common issues:
Handling Missing Data: This involves strategies like imputation (filling gaps based on existing data), removal (discarding missing rows), or prediction models.
Dealing with Duplicates: Identifying and removing duplicate entries ensures that the model doesn’t overfit on repeated data points.
Error Correction: Fixing typos or formatting inconsistencies to avoid misleading information.
Data Normalization/Standardization: Ensures all features are on a similar scale, especially important for models sensitive to feature magnitude (e.g., deep learning models).
Outlier Detection: Removing outliers that could disproportionately affect model predictions.
AI-powered data cleaning techniques, especially those that use unsupervised and semi-supervised learning, have been found to outperform traditional manual methods, improving efficiency and accuracy by over 50%. For example, machine learning models have shown a 20% increase in accuracy when detecting duplicate entries compared to rule-based systems (Panwar, 2024).
4. Feature Engineering
Once the data is cleaned, it’s essential to transform it in ways that enhance the model’s predictive power:
Selecting Relevant Features: Through techniques like feature selection, only the most important features are retained, reducing noise and dimensionality.
Creating New Features: New features might be created by combining existing data (e.g., combining day and month to create a "season" feature).
Feature Scaling: This ensures that all features are on the same scale, which is vital for many machine learning algorithms.
5. Labeling and Annotation
For supervised learning models, accurate labeling is crucial. Whether it's for an image classification task or a sentiment analysis project, tasks Sherlock himself would likely take on with a magnifying glass and sharp wit, labeled data serves as the foundation for training. However, labeling can be error-prone and labor-intensive. Automated tools can help scale this process, but just as good detective work would never settle for half a clue, accuracy remains paramount.
In the context of retrieval-augmented generation (RAG) for LLMs, the labeling and annotation process involves carefully crafting the context that will guide the model. Incorrect labeling or noisy annotations (like emojis or misspelled words) can negatively affect the LLM’s understanding and lead to hallucinations or confusion (Intel, 2024).
6. Data Augmentation
Data augmentation is an effective way to generate more data from existing samples, especially when training datasets are small. Techniques include:
Visual Data: Rotating, flipping, or zooming into images.
Text Data: Paraphrasing, back-translation (translating text into another language and back to the original language), or adding synthetic noise to text.
For LLMs, this could involve generating new text samples by adjusting sentence structures or adding variations while maintaining the original meaning.
7. Splitting Data into Training, Validation, and Test Sets
Once data has been cleaned and augmented, it must be split into:
Training Set: Used to train the model.
Validation Set: Used for hyperparameter tuning.
Test Set: Used to evaluate the model's performance on unseen data.
The goal is to ensure the model generalizes well and doesn’t overfit the training data. A common practice is k-fold cross-validation, where the data is divided into "k" subsets to ensure that every data point is used for both training and testing.
8. AI in Data Cleaning for Efficiency and Scalability
AI-powered data cleaning methods not only offer improvements in accuracy but also significantly boost efficiency. Machine learning models, especially unsupervised learning algorithms, can scale to handle massive datasets without compromising performance. This is particularly important for industries like healthcare and retail, where datasets are continually growing.
AI-based data cleaning also provides adaptability to different types of data and inconsistencies, ensuring that organizations can maintain high-quality data even as the volume grows.
In sectors like healthcare, AI-powered natural language processing (NLP) techniques have been used to clean patient records, reducing medication errors by 30%. Similarly, in retail, machine learning algorithms have cleansed customer data, eliminating duplicate records and improving customer insights by 15% (Cherekar, 2024).
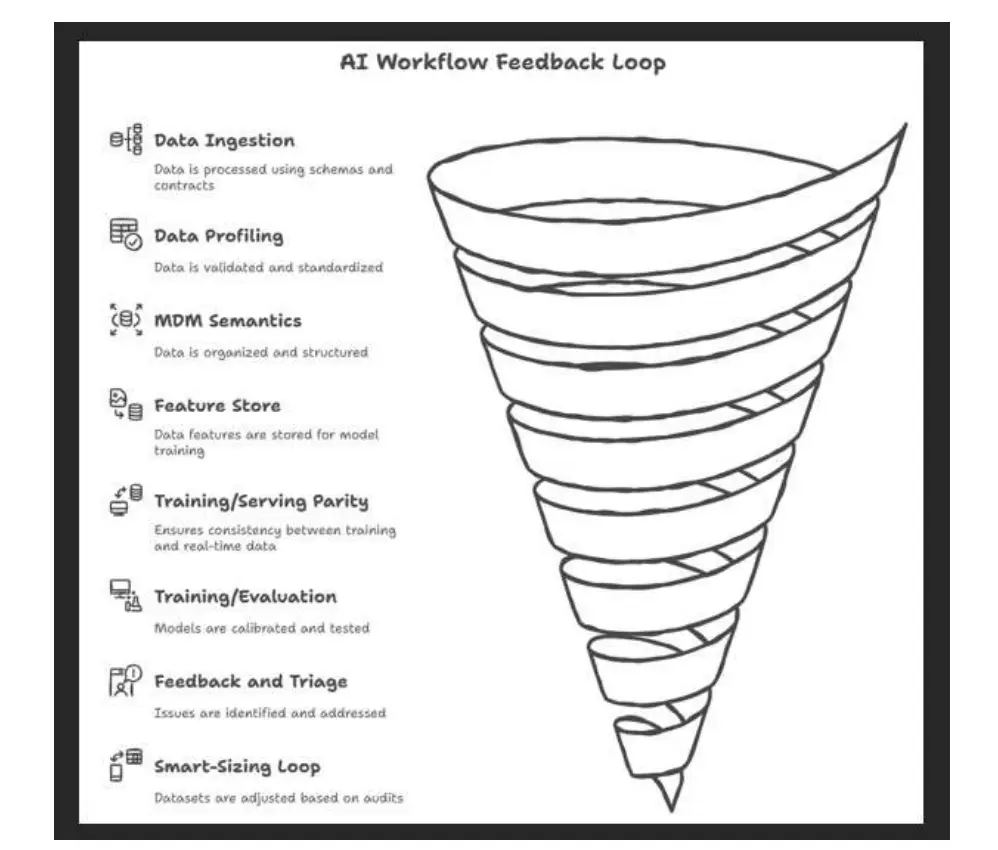
AI Workflow Feedback Loop Source: Abbas (2025)
9. Final Checks and Model Integration
We have now almost reached the end of the tunnel. Before the cleaned data is fed into a machine learning model, it must undergo final checks. These checks ensure there are no data leaks (unintended sharing of validation/test data), that the data is free of errors, and that the features are properly scaled and ready for model consumption. The goal is to ensure the model can process the data in its cleanest, most efficient form, ready for training.
10. Compliance and Security Considerations
Another important point that researchers always emphasize (unlike our questionable detectives or mad scientists) is that in this world, data integrity and privacy is critical and non-negotiable. This rings true, especially in regulated industries like finance, healthcare, and e-commerce. AI-powered data cleaning must comply with standards like GDPR and HIPAA to ensure customer data privacy and regulatory compliance. Moreover, AI models must be able to handle sensitive information securely, potentially using techniques like federated learning and differential privacy to prevent data breaches (Cherekar, 2024).
Conclusion
Clean, reliable data is the underappreciated hero that ensures your models don’t go off the rails. It’d make for a great sequel to a sci-fi adventure, but in the real, albeit not-so-boring world, it's just a bit of a headache.While scaling up models is tempting, it’s the quality of your data that really makes the magic happen. As we've seen, data cleaning is more than just removing noise or fixing errors. A better description would be transforming raw data into something the AI can learn from. With AI-powered techniques for data cleaning, organizations can achieve higher accuracy, efficiency, and scalability. As AI models continue to grow in size and complexity, maintaining clean, reliable data will remain one of the most critical factors in achieving high-performing AI systems. Whether you’re looking for clean datasets, precise data annotation, or thorough model evaluation, feel free to check out Abaka AI's offered solutions that help ensure your AI projects are built on reliable, high-quality data.
Panwar, V. (2024). AI-Powered Data Cleansing: Innovative Approaches for Ensuring Database Integrity and Accuracy. International Journal of Computer Trends and Technology, 72(4), 116-122.
Cherekar, R. (2024). Automated Data Cleaning: AI Methods for Enhancing Data Quality and Consistency. International Journal of Emerging Trends in Computer Science and Information Technology, 5(1), 31-40.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.