
The rise of computer-use agents (CUAs) represents a crucial leap forward in the evolution of AI, shifting from simple chatbots to autonomous systems capable of handling full digital workflows. With advancements from major AI models like OpenAI’s ChatGPT Agent, Anthropic’s Claude, and others, CUAs now possess the ability to interact directly with software environments, executing tasks such as navigating user interfaces, updating systems, and generating reports, doing this all without human involvement. Despite this, the road to fully reliable agents is still challenging, as small errors, unpredictable feedback, and environmental noise can cause performance instability. This article delves into the potential of CUAs, the challenges they face, and the future they are shaping.
Scaling Computer-Use Agents: From Chatbots to Digital Coworkers

What Makes Computer-Use Agents So Hard to Scale?
What Makes Computer-Use Agents So Hard to Scale?
The topic of Agentic AI is so new that we often find ourselves having to give a digestible explanation to our parents when they ask about it. Yet, despite its novelty, the web is almost oversaturated with posts and articles on the subject. Everyone would agree that the future of AI will make this topic a regular feature in the news—perhaps too often—especially as we shift from chatbots to the rise of computer-use agents (CUAs)—AI systems designed to interact directly with software environments.
Recent progress in CUAs has shown promising strides toward creating true autonomous systems, as opposed to the robotic process automation (RPA) tools of the past. AI models such as OpenAI's ChatGPT Agent, Anthropic’s Claude, Google’s Project Mariner, and startups like Manus and Context are slowly redefining the limits of AI. These agents not only handle specific tasks but now have the ability to manage full, end-to-end workflows across digital environments (Zhou et al., 2025). This breakthrough is a necessary step toward creating "agentic coworkers", which are AI systems capable of operating both with APIs and through direct interaction with desktop and browser software. These capabilities allow them to perform tasks like navigating user interfaces, updating CRM systems, and generating compliance reports, all without human intervention.
Despite these impressive advancements, computer-use agents are far from perfect. The same agent may succeed on one attempt but fail catastrophically on another.
The Complexity of Human-Like Computer Interactions
The heart of the challenge behind why these agents don't achieve perfect success rates lies in the complexity of the tasks that computer-use agents must handle. Unlike traditional systems that simply execute pre-programmed actions, CUAs must navigate through diverse software environments, adapt to different user interfaces, and handle unexpected scenarios like UI changes, pop-ups, and latency. This leads to high variance in task outcomes. We can expect that what works once may fail the next time, as small mistakes accumulate and feedback is delayed (Yang et al., 2025a). These challenges make achieving reliability across different environments a monumental task.
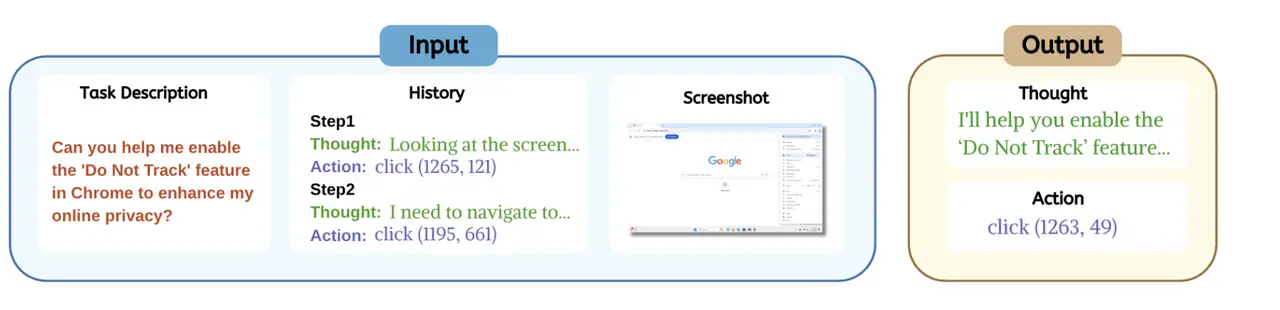
UI Diversity and Unpredictable Context
Another major hurdle are the user interfaces. Each application or platform has its own UI structure, which can vary significantly across different software. We are talking about buttons, input fields, navigation menues, from web browsers to mobile apps. This creates an environment where agents must constantly adjust and recalibrate their behavior. Moreover, even the most reliable agents struggle with unpredictable user inputs or changes in the software environment. Unlike humans, who can adapt intuitively, CUAs need specific instructions to manage errors or unexpected behavior (Gonzalez-Pumariega et al., 2025).
As discussed in a study by Gonzalez-Pumariega and colleagues, one approach to mitigate this fragility is "wide scaling"—in which multiple agents work in parallel, each handling a subset of the task and offering a range of potential solutions. This approach has been shown to improve task success rates, yet it still faces several limitations in real-world use. For example, evaluating the correctness of an agent's actions is non-trivial, as many tasks have multiple valid solutions (Gonzalez-Pumariega et al., 2025).
Multi-Step Workflows: A Real-World Challenge
Now lets discuss an entirely different challenge. Scaling an agent capable of handling multi-step workflows across multiple applications is a new mountain to climb. Real-world tasks are rarely isolated; they often involve interacting with different tools, switching between software platforms, and handling complex, branching scenarios. For instance, automating data entry from emails into a CRM system requires the agent to read, extract relevant data, search for the appropriate CRM entry, and input the information correctly. Each step needs to be flawless for the overall process to succeed. For a human with basic computer literacy? Dead easy. However, as shown in many real-world applications, even small errors at any stage can cause the entire workflow to fail when the agent is responsible for it (Runtime News, 2026).
This complexity is compounded when agents must function in unpredictable environments. For example, APIs and software interfaces are constantly updated, requiring agents to continuously adapt. In the case of travel booking agents, for example, APIs for airlines and hotels can change frequently, creating new obstacles that weren't accounted for in the initial deployment (Medium, 2026). These scenarios show how the complexity of real-world systems makes agents vulnerable to failure when they operate in dynamic, unpredictable environments.
Memory and Long-Term Context: Keeping Track of Actions
For an AI chatbot to be properly useful to us for a long time, it needs to remember the previous information we have shared. Similarly, for computer-use agents to operate over extended periods, they need to remember previous actions and decisions. This memory allows them to keep track of long-running tasks, making decisions based on context that was established earlier in the workflow. Recent advancements in AI, like GPT-5.4’s longer context windows (up to one million tokens), help alleviate some of these issues, but agents still struggle with maintaining context across long-running tasks, particularly when they must interact with complex, multi-step processes.
This gets complicated further when we encounter issues related to agent "hallucinations," where AI models make incorrect assumptions about data or environments. For example, a MongoDB query agent might generate invalid queries or hallucinate nonexistent fields, leading to errors that can jeopardize the success of a task (Medium, 2026).
The Economic and Technical Costs of Scaling
As the scale of agent deployment grows, so do the technical and economic costs. Hosting AI models and running complex agents require significant computational resources, especially as agents get to work with more complex workflows. This leads to higher operational costs, including server infrastructure, API fees, and licensing. Additionally, the need for continuous monitoring, retraining, and maintenance complicates the deployment process further (Medium, 2026).
Moreover, the costs of failure increase exponentially as agents are deployed at scale. A single error in a multi-step process, such as booking a flight or completing a data entry task, can result in cascading failures across the entire system. As a result, enterprises must invest heavily in error-handling mechanisms and fail-safes, which substantially increase the cost and complexity of scaling these agents.
Scaling the Performance of CUAs: The Role of Wide Scaling
A natural way to mitigate this fragility is by applying a wide scaling approach. Instead of simply relying on a single rollout from one agent, this method generates multiple rollouts in parallel and selects the most successful one. Wide scaling takes advantage of the fact that agents, although suboptimal individually, often succeed on complementary subsets of tasks. Research has shown that this approach leads to a substantial improvement in performance, with recent tests pushing the success rate to 69.9% at 100 steps, surpassing prior work and approaching human-level performance (Gonzalez-Pumariega et al., 2025).
However, scaling computer-use agents introduces its own set of challenges. Long-horizon tasks often involve a dense flow of information, with most details being irrelevant to task success. This makes it difficult to represent, interpret, and compare the action sequences. Additionally, evaluating the success of these tasks is not straightforward. Many computer-use tasks admit multiple valid solutions, making it hard to automatically determine whether a task has been completed successfully.
The Need for Broader Tool Accessibility and Reasoning Capabilities
Computer-use agents operate more effectively when they have access to a wide range of tools and the ability to reason across them. The effectiveness of these agents depends heavily on two factors: tool accessibility and reasoning capability (Zhou et al., 2025). Tool accessibility provides agents with the ability to interact with any software that humans use, bypassing the need for APIs or manually programmed tools. The reasoning capability, on the other hand, allows agents to execute complex action sequences and produce the right outputs.
The Challenges of Real-World Use
Even with these improvements, robustness and reliability remains a significant challenge. As everyone knows, real-world environments are messy, and tasks often require agents to work across multiple systems that involve inconsistent formats, legacy software, and external data sources. These complexities contribute to the brittleness of current agents. For example, in tasks like travel booking or data cleaning, simple proof-of-concept (POC) agents often work well in controlled settings but fail to scale when applied in production environments (Medium, 2026). APIs change frequently, systems introduce new bugs, and unexpected user inputs add layers of complexity that can overwhelm even the most sophisticated agents (Runtime News, 2026).
To overcome these challenges, researchers have turned to innovations like Behavior Best-of-N (bBoN), a wide scaling paradigm for computer-use agents that generates multiple trajectories in parallel and selects the best one. This method has shown considerable promise in improving robustness, leading to higher success rates and fewer failures (Gonzalez-Pumariega et al., 2025).
The Future of Computer-Use Agents: Progress, Potential, and Pitfalls
Despite the visible progress, we are still far from achieving fully reliable and autonomous agents. As we discussed, scaling computer-use agents is hard because they must deal with an ever-changing, unpredictable environment and continuously learn from past failures to improve future performance. However, the potential benefits of successful scaling are undeniable. With the ability to automate workflows across multiple applications and software environments, computer-use agents can reduce human involvement in routine tasks and free up time for more strategic or creative work.
As these agents continue to evolve, it will be essential to focus on the foundational issues of reliability, scalability, and adaptability. There is also the ongoing need for human oversight to mitigate errors and ensure that agents continue to function as intended.
Are you ready to explore how advanced AI solutions like computer-use agents can streamline your workflow? Reach out to Abaka AI today to learn more about our data annotation, dataset curation, and AI-powered automation services that are tailored to meet the needs of modern businesses.
References
Gonzalez-Pumariega, G., Tu, V., Lee, C.-L., Yang, J., & Li, A. (2025). The Unreasonable Effectiveness of Scaling Agents for Computer Use.
Medium. (2026). Why It’s So Hard to Build Real AI Agents. Link
Runtime News. (2026). Why Clicking is Hard for AI Agents: Challenges in Real-World Use. Link
Yan Yang, Dongxu Li, Yutong Dai, Yuhao Yang, Ziyang Luo, Zirui Zhao, Zhiyuan Hu, Junzhe Huang, Amrita Saha, Zeyuan Chen, Ran Xu, Liyuan Pan, Silvio Savarese, Caiming Xiong, and Junnan Li.Gta1: Gui test-time scaling agent, 2025b.
Zhou, E., Li, Y., Amble, S., & Li, J. (2025). The Rise of Computer Use and Agentic Coworkers. Andreessen Horowitz. Link
FAQ
1. What are computer-use agents (CUAs)? CUAs are AI systems designed to interact directly with software environments and perform tasks like navigating applications, typing commands, and managing multi-step workflows autonomously.
2. Why are computer-use agents hard to scale? Scaling CUAs is difficult due to several factors, including UI diversity, unpredictable user input, and the need for long-term memory across multi-step tasks. Additionally, technical challenges like managing failures and maintaining reliability in real-world environments make scaling complex.
3. What role does "wide scaling" play in improving CUAs? Wide scaling involves deploying multiple agents in parallel, each handling a subset of tasks and offering a range of potential solutions. This approach has been shown to improve robustness and task success rates, but it still faces challenges in evaluating the correctness of agent actions.
4. Can CUAs be used in real-world enterprise environments? While CUAs hold significant potential for automating tasks in enterprise environments, their complexity and the need for continuous adaptation to evolving software systems make them difficult to implement reliably at scale.
5. How can companies overcome the challenges of scaling CUAs? Companies can overcome these challenges by focusing on improving reasoning capabilities, increasing context memory, and investing in error-handling mechanisms to ensure agents can operate effectively in dynamic and unpredictable environments.
Further Readings:
👉 AI Can Now Use Your Computer: Why FDM-1 Signals the Next Agent Breakthrough
👉 The AI Agent Evaluation Crisis: Bridging the 37% Production Gap
👉 Why Agents Need Real RL Environments That Push Back
👉 From Chatbots to Operators: The Rise of AI Agents, FDM-1, and the OpenClaw Ecosystem
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.