
Most AI coding benchmarks claim to measure progress, but what if they’re measuring the wrong thing? This article cuts through the noise to reveal which benchmarks actually reflect real engineering capability and which ones don’t.
Blogs
2026-04-03/General
HumanEval vs SWE-bench vs LiveCodeBench

Natalia Mendez,Director of Growth Marketing
HumanEval vs SWE-bench vs LiveCodeBench: Which AI Coding Benchmark Actually Matters?
Why benchmark choice matters in the first place
A coding benchmark can be thought of as a measurement instrument. It takes a broad, messy capability like software engineering and compresses it into a limited set of tasks and metrics. That compression is useful and gives us a shared basis for comparison. But it is also where problems begin, because there is always a temptation to optimize for what is easy to score rather than for what is actually valuable in practice.
Many experts argue that countless existing benchmarks have become “too saturated” and no longer capture the current frontier of model capability. Their conclusion is that harder, more realistic evaluations are needed; or even more, benchmark design has become stagnant and many widely used evaluations may present a “skewed or misleading picture” because they capture only a narrow slice of what coding actually involves.
So before asking which benchmark matters, it helps to ask a more basic question: for what purpose? A benchmark matters differently depending on whether you are choosing a model for a product, tracking research progress, or estimating real-world developer ROI. In simple steps, it is wise to increasingly ask oneself the following questions: Can the model write a function? Can it work inside a repository?, and more importantly: Can it operate over fresh tasks and across multiple coding skills? (Wall, 2025).
HumanEval: clean signal, narrow scope
In Evaluating Large Language Models Trained on Code, Chen et al. (2021) introduce HumanEval as a benchmark for docstring-to-function synthesis. The setup is straightforward: the model reads an English docstring and must generate a standalone Python function that passes unit tests. The dataset contains 164 handwritten problems, each with several unit tests, averaging 7.7 tests per problem.
HumanEval’s main contribution is methodological. It moves code evaluation away from string matching metrics such as BLEU and toward functional correctness. That shift was important. The authors explicitly contrast “match-based metrics” with actual execution-based evaluation, and they introduce the now-standard pass@k family of metrics. In their reported setup, Codex solves 28.8% of the problems with a single sample, and performance rises substantially with repeated sampling and selection strategies, reaching 77.5% when selecting a sample that passes unit tests among 100 samples.
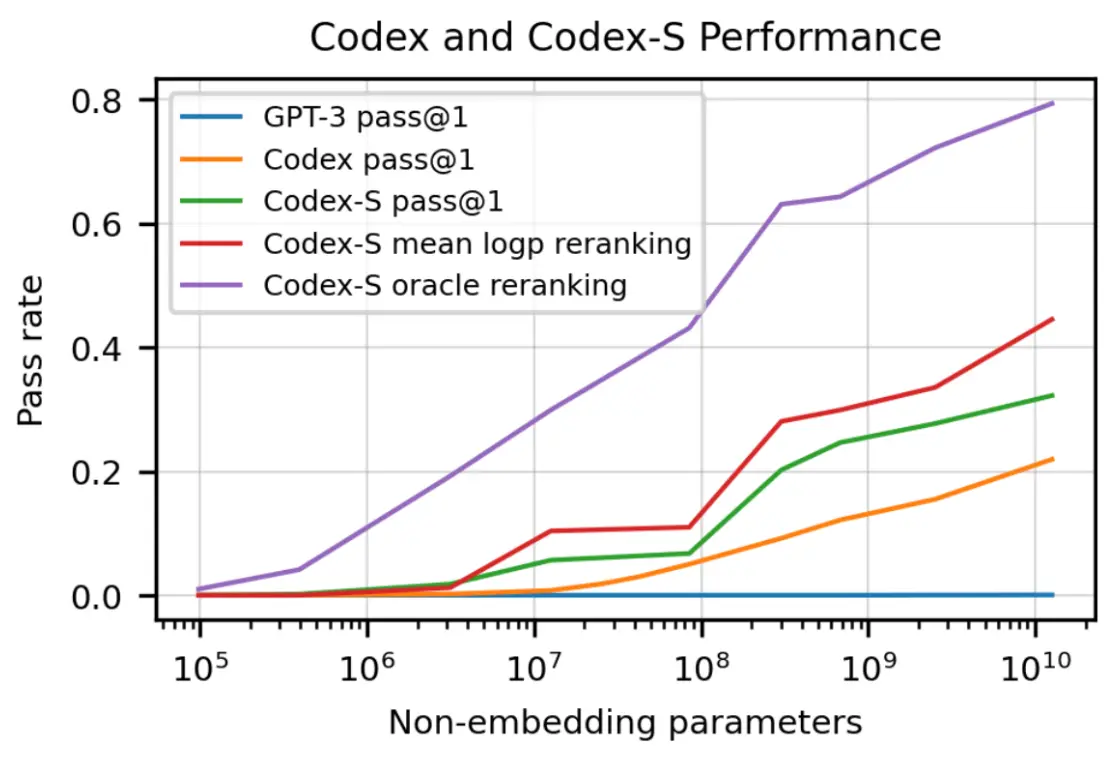
That said, HumanEval is intentionally narrow, and that narrowness matters, and mostly involve self-contained problems that can be solved in a few lines of code. That is not a trivial limitation. It changes what the score is actually telling you. A model may be very good at completing a function from a clear specification and still perform poorly when asked to navigate a codebase, make safe edits, or debug behavior spread across multiple files.
LiveCodeBench gives quantitative support to this concern. Jain et al. (2024), show that when HumanEval-style results are compared against LiveCodeBench, models often split into two groups: some perform well on both, while others perform well on HumanEval-style tasks but fall off sharply on LiveCodeBench. That pattern suggests benchmark-specific overfitting rather than broad coding competence.
In short: HumanEval is used when you want a clean, fast measure of isolated functional correctness. It fails when the target is software engineering work: searching, editing, testing, and iterating inside a repository.
SWE-bench: When coding means working in a real Codebase
In SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Jimenez et al. (2024) push the evaluation target much closer to actual repository work. Each task includes an issue description and a full codebase snapshot. The model must generate a patch, the system applies it, and the resulting code is evaluated by running tests. Success is measured as the percentage of tasks resolved.
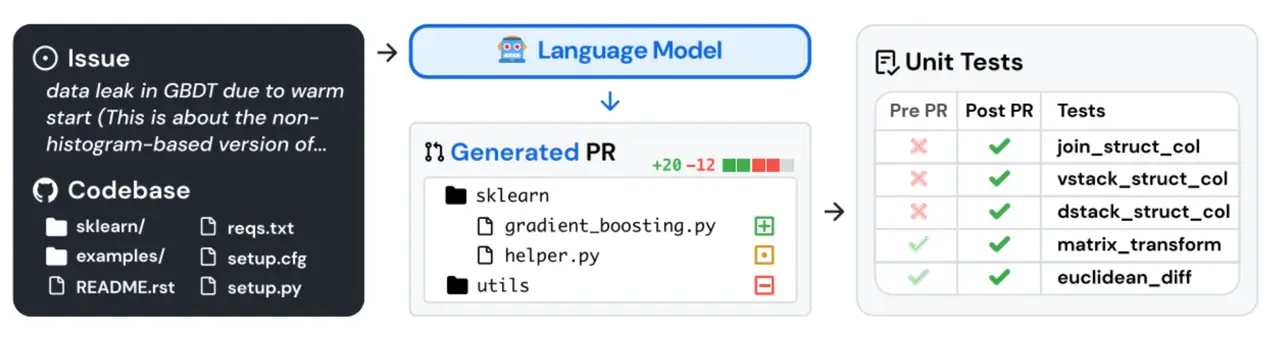
The scale of the benchmark makes its ambition clear. SWE-bench includes 2,294 software engineering problems drawn from real issues and pull requests across 12 popular Python repositories. These are not small, synthetic exercises. Repository-level statistics show an average of roughly 3,010 non-test files and 438K non-test lines. Issues average 195.1 words, and reference solutions modify about 1.7 files, 3 functions, and 32.8 lines on average.
Just as important is the evaluation design. Compared with HumanEval, SWE-bench is much closer to the structure of real engineering work, and each task includes at least one fail-to-pass test linked to the actual fix, that 40% of instances include at least two such tests, and that a median of 51 additional tests are run to protect existing functionality. In other words, the benchmark is not just asking whether a model can write something plausible. It is asking whether it can change a living codebase without breaking it.
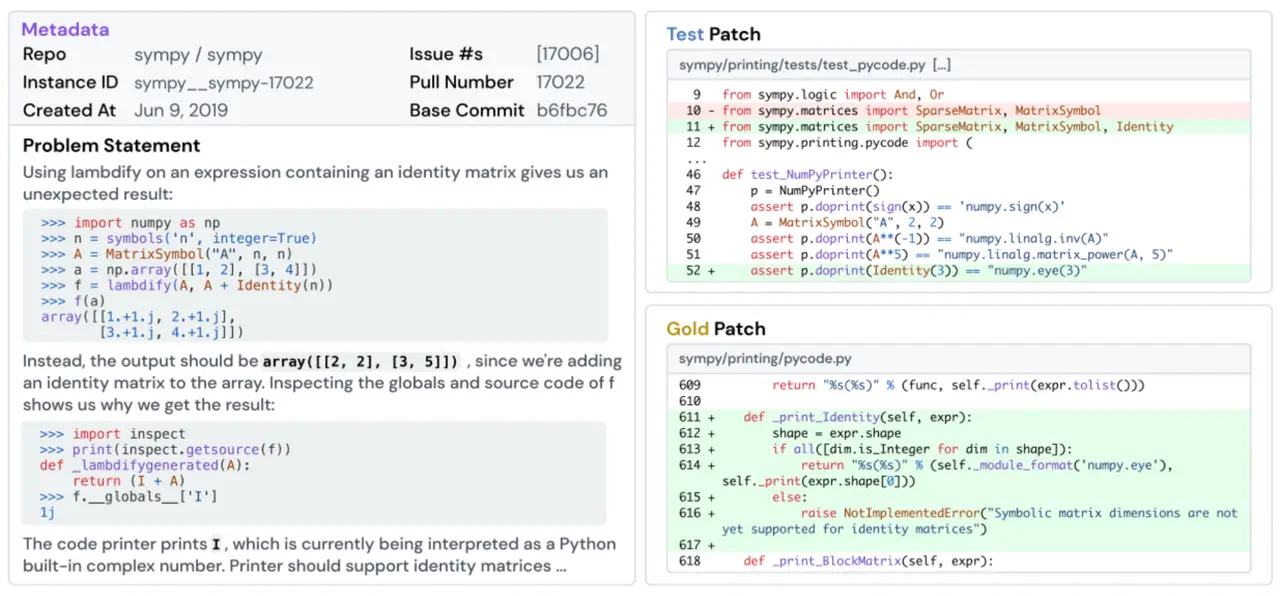
The difficulty of that shift shows up immediately in the results. In the original baseline setting, Claude 2, the best-performing evaluated model, resolves only 1.96% of issues under a BM25 retrieval setup. That number is striking, but it also highlights another important point: in repository-scale evaluation, performance is no longer just about the model. It is also about the scaffolding around it. Because full codebases exceed normal context windows, the system must retrieve relevant files before the model can even attempt a fix. Jimenez et al. (2024) report that with a 27k-token budget, BM25 retrieves a superset of the “oracle” edited files in about 40% of instances, but retrieves none of the oracle files in nearly half of them. So the final score partly reflects reasoning quality and partly reflects context-selection quality.
In short: SWE-bench is used when you care about repository-level bug fixing and multi-file edits under test-based verification. The key difference from HumanEval is not “harder puzzles,” but the requirement to operate inside a large codebase with realistic constraints.
LiveCodeBench as “fresh,” multi-skill code evaluation with contamination controls
In LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code, Jain et al. (2024) responds to two major concerns in benchmark design: staleness and contamination. Their benchmark continuously collects new problems from coding platforms such as LeetCode, AtCoder, and Codeforces, and tags each one by release date.
Two design choices make LiveCodeBench especially important.
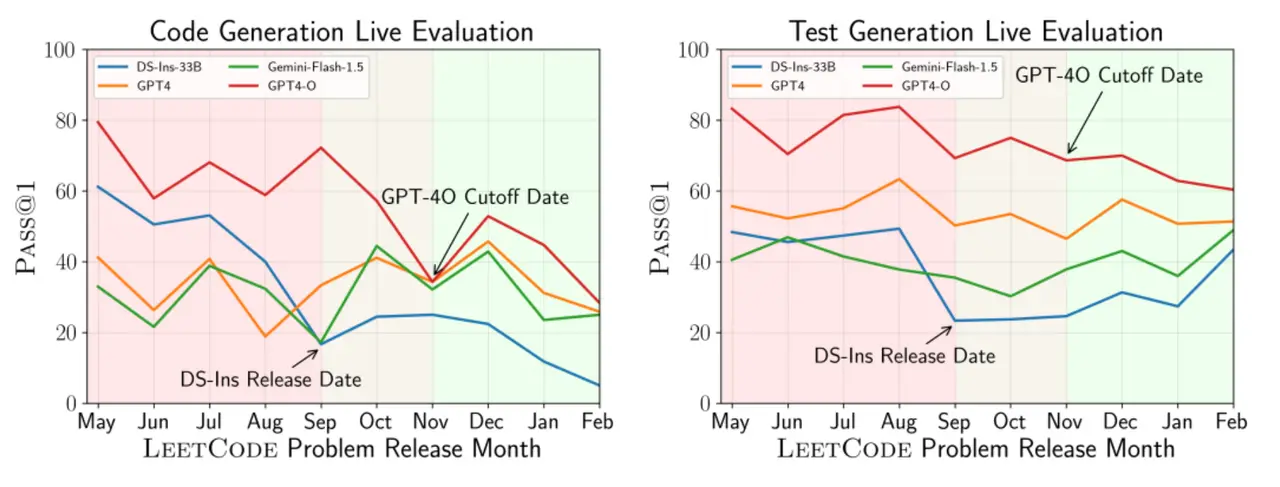
The first is that it is explicitly time-aware. To begin with, decontamination is difficult and can often be bypassed through simple rewording, so instead of relying only on static decontamination methods, they build “live updates” into the benchmark itself. Models are evaluated on problems released after the model’s cutoff date. This is not a cosmetic change. It creates a much cleaner separation between training exposure and evaluation. The authors report a “stark drop” in performance for some models on newer problems, consistent with the idea that earlier tasks may have been contaminated. They show this, for example, in performance drops for DeepSeek and GPT-4-O on LeetCode problems released after certain cutoff dates.
The second design choice is that LiveCodeBench treats coding as a multi-skill activity. Beyond standard code generation, it evaluates self-repair, code execution, and test output prediction. That matters because coding assistants are not only asked to generate code. They are also asked to read code, interpret behavior, debug failures, and reason for expected outputs. LiveCodeBench reflects broader reality more directly than earlier benchmarks.
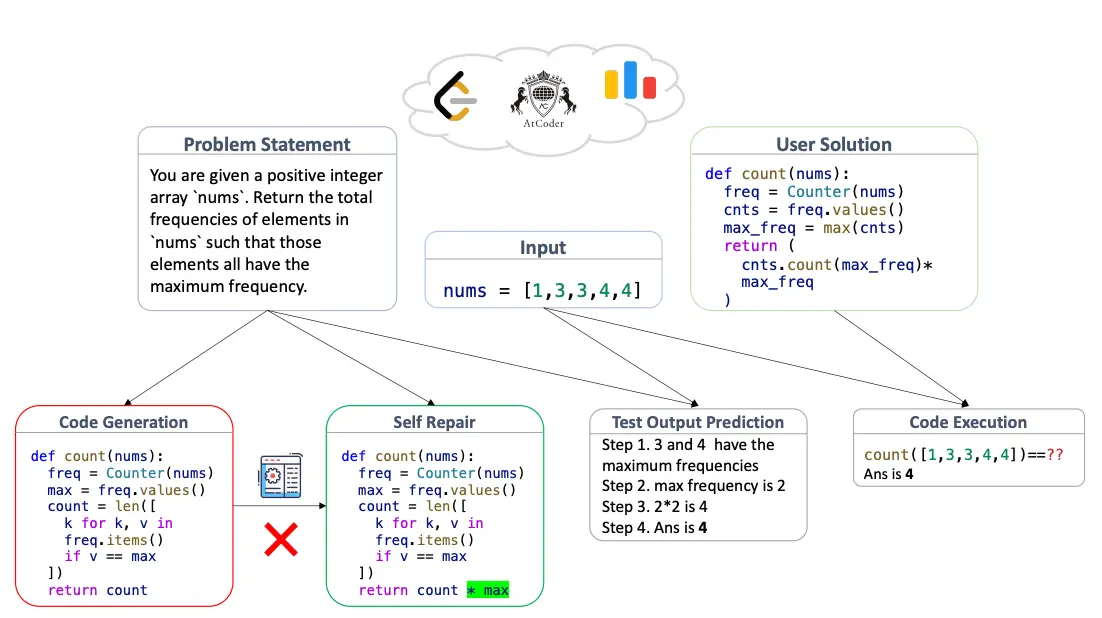
The benchmark’s scale is also substantial. Jain et al. (2024) report that it includes more than 500 problems published between May 2023 and May 2024, and that they evaluate 18 base models and 34 instruction-tuned models. They also note that each problem contains about 17 tests on average, which helps make evaluation more robust.
Perhaps the most revealing result in the paper is the HumanEval overfitting analysis, showing that models again divide into two groups: those that perform well on both LiveCodeBench and HumanEval-like tasks, and those that do well on HumanEval but much worse on LiveCodeBench. That pattern strongly suggests overfitting to simpler, more isolated evaluation regimes. One of their examples is especially telling: a model scores around 60 pass@1 on HumanEval+ but only around 26 on an easier subset of LiveCodeBench. That is not a small gap. It is a clear sign that benchmark success does not automatically generalize.
In short: LiveCodeBench is used when you want time-sensitive, contamination-resistant evaluation and when you believe “coding” includes debugging and comprehension, not only generation.
Why none of these benchmarks fully capture real engineering work
The problem with these benchmarks is not that they are wrong. The problem is that each one simplifies reality in a different way, and every simplification introduces a blind spot.
One major blind spot is that passing tests is not the same as being correct. Martinez and Franch (2026) define “patch overfitting” as a fix that passes the available tests while still being incorrect because the test suite is incomplete, and argue that current benchmark ecosystems often lack validation mechanisms beyond test passing. The better the leaderboard results look, the more urgent it becomes to ask whether we are measuring genuine issue resolution or simply clever test-satisfying behavior.
Wang et al. (2026), in Are “Solved Issues” in SWE-bench Really Solved Correctly? An Empirical Study provides quantitative evidence of this problem. When they run more complete developer tests, they find that 7.8% of “plausible patches” are incorrect on average, producing an absolute drop of 4.5% in issue resolution rate.
A second blind spot is memorization and leakage. In The SWE-Bench Illusion, Liang et al. (2025) show that state-of-the-art models can identify buggy file paths from issue descriptions alone with up to 76% accuracy, but that this drops to 53% on repositories not included in SWE-bench. That result is consistent with benchmark-specific memorization or contamination effects rather than general reasoning ability.
A third issue is conceptual: coding is a multi-dimensional activity, but many benchmarks remain largely one-dimensional. LiveCodeBench makes this point explicit. Traditional code benchmarks often focus only on natural-language-to-code generation and ignore other important capabilities, and models can overfit easier isolated problems, with scores that do not transfer well to harder or fresher tasks.
Taken together, the pattern is clear. HumanEval can overestimate “real coding” because it isolates the task too aggressively. SWE-bench can overestimate “real fixing” because passing tests does not guarantee semantic correctness and because patches can overfit to incomplete validation. LiveCodeBench improves contamination control and broadens the skill set being measured, but it still abstracts away many parts of real engineering work.
What actually matters now: evaluating the workflow, not just the output
If the goal is to predict whether a model will actually be useful in development, the direction is increasingly clear: evaluation must move from “write code” to “do the work.” This means measuring performance across full workflows, including realistic bottlenecks such as locating relevant files, understanding constraints, making minimal edits, running tests, interpreting failures, iterating on fixes, and avoiding regressions. This shift aligns more closely with how engineers actually operate, and with how coding agents are now being deployed in practice.
At the same time, rising benchmark performance (driven by leaderboard dynamics and strong industry participation) has exposed a deeper issue: higher scores do not necessarily reflect better real-world capability. Test-based validation can miss incorrect or incomplete solutions, and some gains may stem from memorization or benchmark-specific optimization rather than true generalization. As a result, evaluation is moving beyond isolated code generation toward assessing whether models can handle end-to-end engineering tasks under real constraints.
In short: the benchmark that “matters” is the one that best predicts workflow performance, not the one that maximizes a single static metric. HumanEval remains useful for quick baseline functional synthesis; SWE-bench captures repository-level issue resolution; and LiveCodeBench adds time-aware, contamination-conscious, multi-skill evaluation.
FAQ
Why do models sometimes score very high on one benchmark but perform poorly on another?
This usually happens because each benchmark measures a different layer of coding ability. For example, HumanEval focuses on small, self-contained functions, while SWE-bench requires navigating large codebases and resolving real issues across files. A model can excel at generating isolated code snippets but struggle when coordination, context, and debugging are required. This gap is not accidental, it reflects how benchmarks isolate skills rather than test them together. As shown in SWE-bench, even strong models solve only a very small percentage of real issues (around 1.96% in early evaluations), highlighting how performance does not transfer cleanly across environments .
How does “data contamination” affect benchmark results, and should we worry about it?
Data contamination occurs when benchmark problems are unintentionally included in a model’s training data. This can inflate performance because the model is not solving the task, it is recalling it. LiveCodeBench was designed specifically to address this by using newly released problems and time-based evaluation windows. Interestingly, performance drops significantly when models are tested on problems published after their training cutoff, suggesting that some earlier results were partially influenced by prior exposure . This means benchmark scores should always be interpreted with caution, especially for widely known datasets.
What does a “good” evaluation of coding AI actually look like today?
A strong evaluation increasingly combines multiple layers: simple benchmarks (like HumanEval), realistic issue-based tasks (like SWE-bench), and dynamic or evolving datasets (like LiveCodeBench). However, even this combination is still incomplete. The most meaningful evaluations today are shifting toward workflow-based setups, where models must plan, write, debug, and iterate over time. These resemble how developers actually work, rather than how benchmarks are structured. The field is gradually moving from measuring isolated outputs to measuring full problem-solving processes.
Related Topics
Claude Code x Figma: How to Turn AI-Generated UI into Editable Designs
Decoding "Nano Banana": Key to Next-Gen Image Editing—Fine-Grained Instruction Data
SuperGPQA First Test: GPT-5 is Powerful, but Unrelated to ChatGPT
MiniMax M2 Drops: Tops Coding Benchmark, Rivals GPT/Claude!
Sources
Swe-Bench: Can language models resolve real-world Github issues? https://arxiv.org/pdf/2310.06770
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code https://arxiv.org/pdf/2403.07974
From HumanEval to SWE-bench https://runloop.ai/blog/understanding-llm-code-benchmarks-from-humaneval-to-swe-bench?
Evaluating Large Language Models Trained on Code https://arxiv.org/pdf/2107.03374
What are popular AI coding benchmarks actually measuring? https://blog.nilenso.com/blog/2025/09/25/swe-benchmarks/?
What's in a Benchmark? The Case of SWE-Bench in Automated Program Repair https://arxiv.org/pdf/2602.04449
15 LLM coding benchmarks https://www.evidentlyai.com/blog/llm-coding-benchmarks?
Are "Solved Issues" in SWE-bench Really Solved Correctly? An Empirical Study https://arxiv.org/pdf/2503.15223
The SWE-Bench Illusion: When State-of-the-Art LLMs https://arxiv.org/html/2506.12286v3?
More on Abaka AI
Contact Us– Learn more about how world models and interactive systems are evaluated.
Explore Our Blog – Read research and articles on embodied AI datasets, multimodal alignment, simulation grounded data, and evaluation beyond appearance alone.
Follow Our Updates – Get insights from Abaka AI on real-world robotics research, agent evaluation workflows, and emerging standards for interactive AI systems.
Read Our FAQs – See how teams design datasets and evaluation frameworks for systems that must act, adapt, and remain consistent over time.
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.