SuperGPQA First Test: GPT-5 is Powerful, but Unrelated to ChatGPT
Our tests confirm that the GPT-5 base model is indeed the most powerful AI in history. The catch? The version you use in ChatGPT has been significantly weakened, even falling behind some competitors. This report uses data to reveal the huge gap between its technical peak and the reality.
GPT-5 is Highly Capable, Yet Most People Have No Access
SuperGPQA Rigorous Test Review (zero-shot, unified decoding)
You might think you're using GPT-5, but the reality is more complex. Our comprehensive testing reveals a significant performance gap between the groundbreaking base model and the version integrated into ChatGPT.
The much-anticipated GPT-5 has finally lifted a corner of its mysterious veil. To objectively gauge its capabilities, we utilized SuperGPQA, a new-generation benchmark for large models. This benchmark was constructed by 2077AI Open Source Foundation, with Abaka AI serving as a core contributor.
Unlike traditional benchmarks, SuperGPQA focuses on graduate-level qualifying exam questions across nearly 300 disciplines, rigorously testing a model's deep professional knowledge and complex reasoning abilities. We are pleased to announce that this benchmark is fully open-source. For teams interested in using SuperGPQA to evaluate their own models, more information can be found on the 2077AI official website: https://www.2077ai.com/blog/2077AI-SuperGPQA.
According to the comprehensive test results from SuperGPQA, GPT-5's original (zero-shot) model has demonstrated astonishing performance, truly worthy of its title as "the strongest ever".
This leads to a clear conclusion: the powerful GPT-5 that is setting records and the product you use in daily life are two entities with vastly different capabilities.
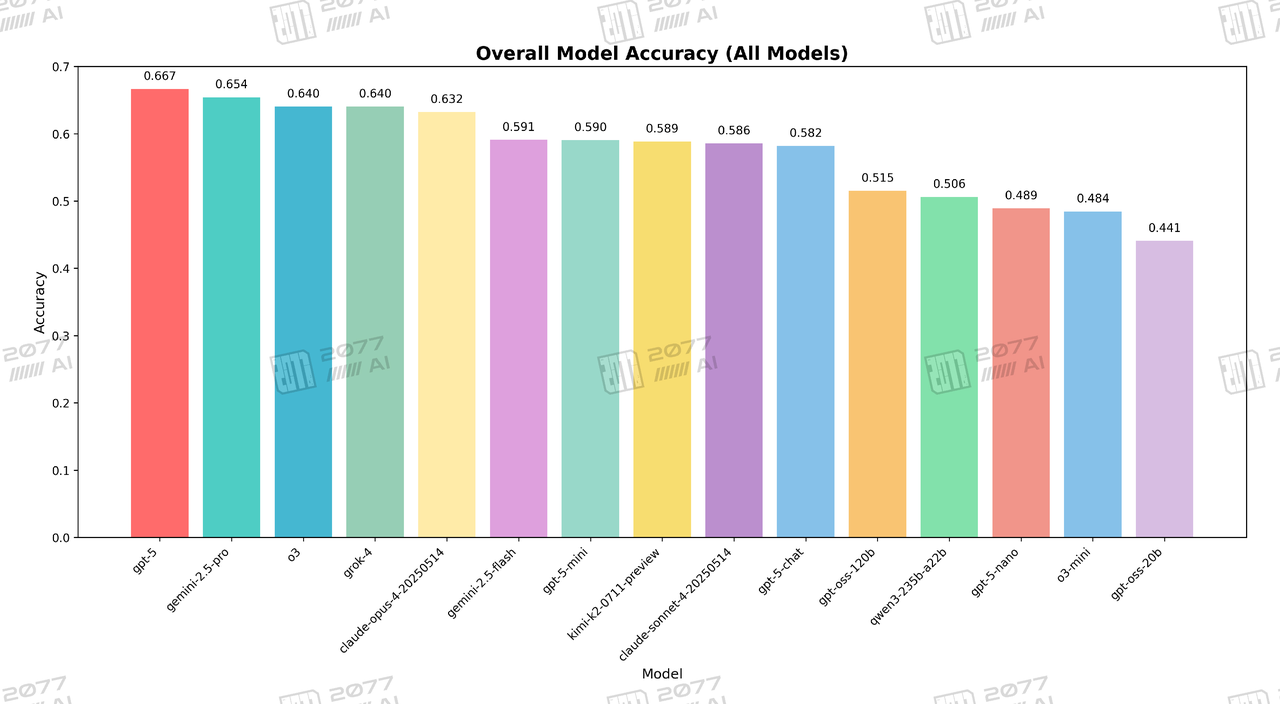
Overall Model Accuracy (All Models)
This chart provides a clear ranking of all models based on their average accuracy. It shows gpt-5 leading the entire field with an overall accuracy of 66.7%. In stark contrast, gpt-5-chat is found much further down the list with an accuracy of only 58.2%, placing it behind several competing models and its smaller sibling, gpt-5-mini. This data visually confirms the significant performance drop between the base model and its chat-integrated version.
Overall Performance: The Gap Between the Champion and an "Average Student"
Judging from the overall accuracy rate, GPT-5's strength is beyond doubt. In the comprehensive tests covering dozens of disciplinary fields from agriculture to social sciences, gpt-5\_zero-shot took a dominant lead with an average accuracy rate of 66.1%, securely claiming the top spot.
However, when we turn our attention to the more familiar chatbot version, gpt-5-chat\_zero-shot, the results are eye-opening. Its average accuracy rate is only 57.3%, with its ranking dropping to around 10th place. It is not only far inferior to GPT-5's original model but even surpassed by models such as o3, claude-opus-4, gemini-2.5-pro, and its own gpt-5-mini. This nearly 8-percentage-point performance gap can be described as a chasm in the competition among top models.
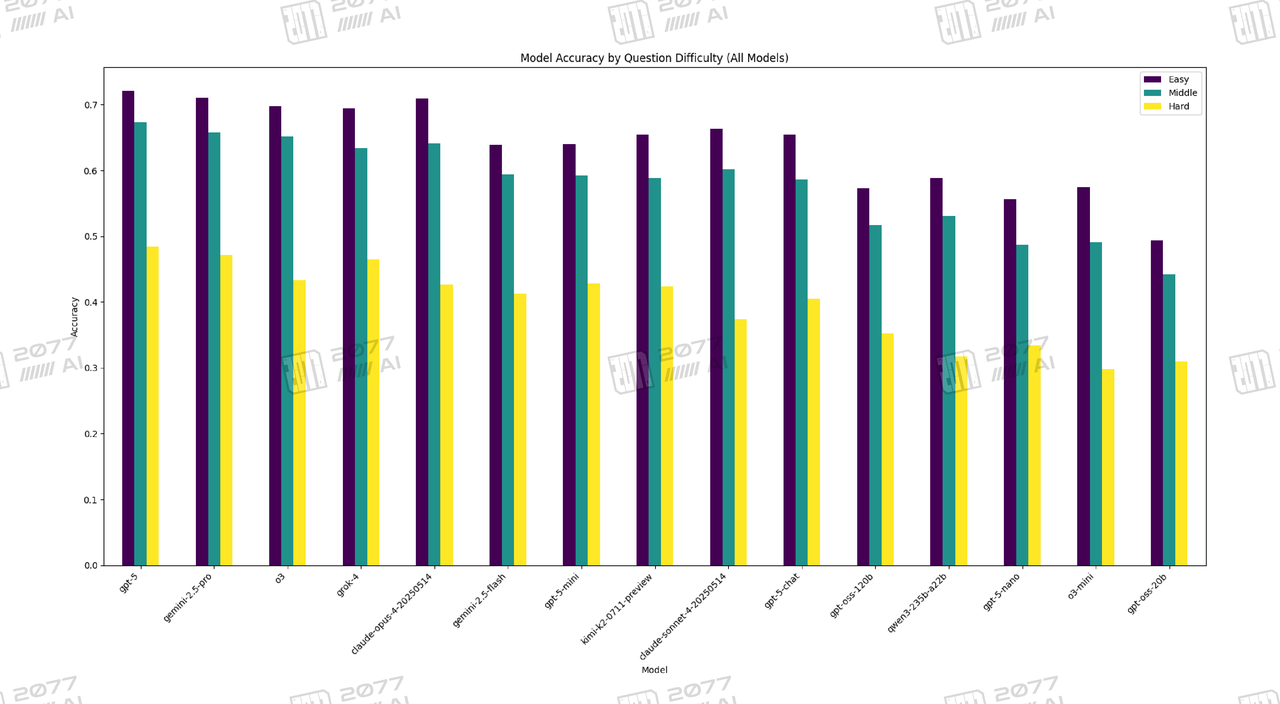
Model Accuracy by Question Difficulty (All Models)
The performance gap between gpt-5 and gpt-5-chat is most evident in the "Hard" questions (yellow bars). Here, gpt-5 maintains a high accuracy of around 48%, while gpt-5-chat's accuracy plummets to about 37%. This widening gap on difficult tasks suggests that the chat version's optimization may have come at the cost of its deep reasoning capabilities.
Difficulty Breakdown: The greater the challenge, the more pronounced the gap
This performance discrepancy is particularly striking across questions of varying difficulty levels.
Hard-level questions: In the most challenging questions, GPT-5's original model demonstrates its exceptional reasoning and knowledge capabilities, standing as a well-deserved leader. In contrast, GPT-5-chat's performance drops sharply in this range, further widening the gap with the first tier of models.
Middle & Easy-level questions: Even in relatively simple questions, GPT-5-chat fails to reverse its decline, with its accuracy rate still significantly lower than that of GPT-5's original model.
This indicates that the "optimization" process from the original model to the chat product seems to have weakened the model's core capability to handle complex and professional issues.
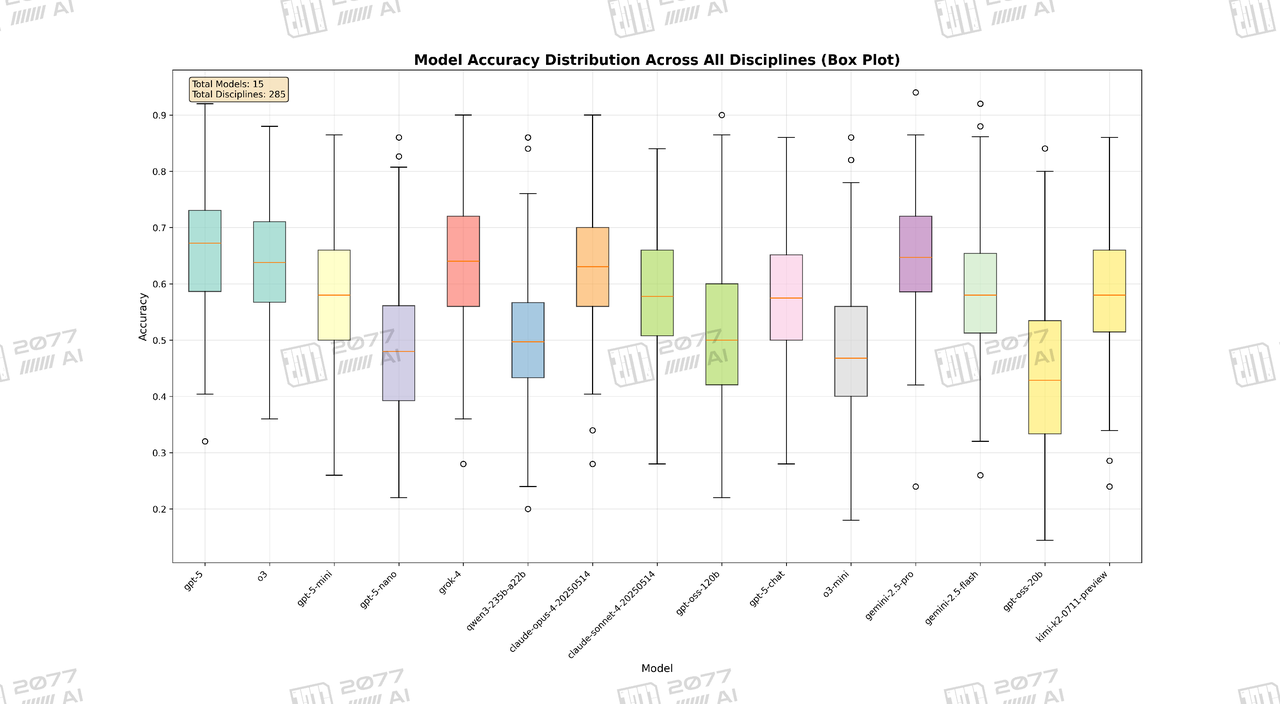
Disciplinary performance: All-round leadership vs. the "uneven performance across disciplines" phenomenon.
Model Accuracy Distribution Across All Disciplines (Box Plot)
Through the box plot of disciplinary performance, we can more intuitively observe the performance distribution of the two models. The accuracy box of gpt-5\_zero-shot (representing the distribution of 50% of disciplinary performance) is overall higher than that of all other models, demonstrating its strength and stability in most fields. In contrast, the box of gpt-5-chat\_zero-shot lies in a relatively mediocre position, with its performance median and upper and lower quartiles all comprehensively lagging behind.
Unexpected Surprise: The standout GPT-5 Mini
In this test, the "medium-sized" member of the GPT-5 family – gpt-5-mini – emerged as an unexpected highlight. With an average accuracy rate of 59%, it ranked 7th on the list, outperforming gpt-5-chat, with overall performance comparable to Gemini 2.5 Flash, and even approaching the original GPT-5 model in some disciplines.
The "medium-sized" member - gpt-5-mini stands out
This suggests that gpt-5-mini may be a more finely balanced and optimized version. While retaining strong core capabilities, it likely boasts higher efficiency and cost-effectiveness. For many developers and enterprises, this "mini" version may be a more appealing option. In contrast, gpt-5-nano is more positioned for lightweight and end-user applications. Although its 49% accuracy rate cannot compete with top models, it remains competitive in its corresponding niche.
Significant Gap in User Experience: This aligns perfectly with our test results
Recently, many users who have accessed GPT-5 have reported a significant gap in experience when using the publicly released ChatGPT-5. Users generally feel that the model's "intelligence" seems to have been weakened, with the accuracy and depth of its answers far inferior to expectations. Their initial excitement and amazement have gradually turned into confusion and disappointment.
This subjective user experience is completely consistent with the objective data we obtained through large-scale, standardized tests. Our test results explain from a data perspective why users feel this "gap": the ChatGPT-5 they use is indeed not the GPT-5 that leads the pack in the rankings.
Conclusion: A rational view of AI's "capability" and "performance"
Model Performance in Top 5 Disciplines
In the disciplines where models generally perform best, such as Engineering and Science, gpt-5 consistently achieves top-tier accuracy. While gpt-5-chat also performs relatively well here, it still visibly trails its base model. This demonstrates that the performance gap between the two remains significant even on what could be considered more favorable ground.
Model Performance in Bottom 5 Disciplines
This chart focuses on the five disciplines with the lowest average scores, representing the most challenging subjects for the models (e.g., Law, Military Science). In these difficult areas, gpt-5's superior capability allows it to maintain a clear lead over the other models. The performance of gpt-5-chat, however, sees a more substantial decline, highlighting a significant weakness in handling specialized and complex knowledge areas compared to the original gpt-5.
We clearly see that there is a huge gap between AI's "technical ceiling" and "product floor". The capability of the GPT-5 base model is stunning, but what users get on ChatGPT is a "domesticated" version.
So, don't get it wrong. GPT-5 is highly capable, but that may be two different things from your ChatGPT.
From Technical Ceiling to Product Floor: How Abaka AI Bridges the Gap
This article's deep dive into GPT-5 and its chat version vividly illustrates a core industry challenge: the most powerful technical capabilities do not always translate into superior user experience. The "last mile" from a base model to a final product is fraught with performance degradation, capability gaps, and optimization pitfalls.
This is precisely where Abaka AI provides value. Whether you are building, fine-tuning, or deploying a large model, we invite you to connect with us. Let's work together to seamlessly convert your model's "technical potential" into solid "market performance."
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
.png)
.png)

