The AI landscape has a new heavyweight. MiniMax M2, the latest open-source LLM from MiniMax, isn’t just another model release—it’s a top-performing contender taking on proprietary giants like GPT and Claude in coding, reasoning, and agentic workflows. Its composite score ranks at the top among open-source models globally. For developers, data scientists, and researchers, M2 offers fast, low-latency inference, multi-file code edits, and robust interactive agent capabilities, making it a practical choice for real-world tasks.
Visualizing MiniMax M2 as a futuristic AI powerhouse
What Is MiniMax M2?
MiniMax M2 is designed to combine scale, efficiency, and developer-centric features:
Parameters & Activations: 230 billion total parameters, with \~10 billion active per inference, ensuring responsive agent loops and cost-effective execution.
Interleaved Thinking: Uses \…\ tags to maintain reasoning across multi-step tasks.
Agentic Workflows: Executes complex, long-horizon toolchains across shell, browser, retrieval, and code runners while keeping evidence traceable.
Open Deployment: Compatible with SGLang, vLLM, and MLX-LM for cloud or local setups.
This combination makes MiniMax M2 ideal for developers seeking low-latency AI inference in complex coding and agentic applications.
Artificial Analysis Intelligence Index: Ranked top among open-source LLMs for mathematics, science, coding, instruction following, and agentic tasks.
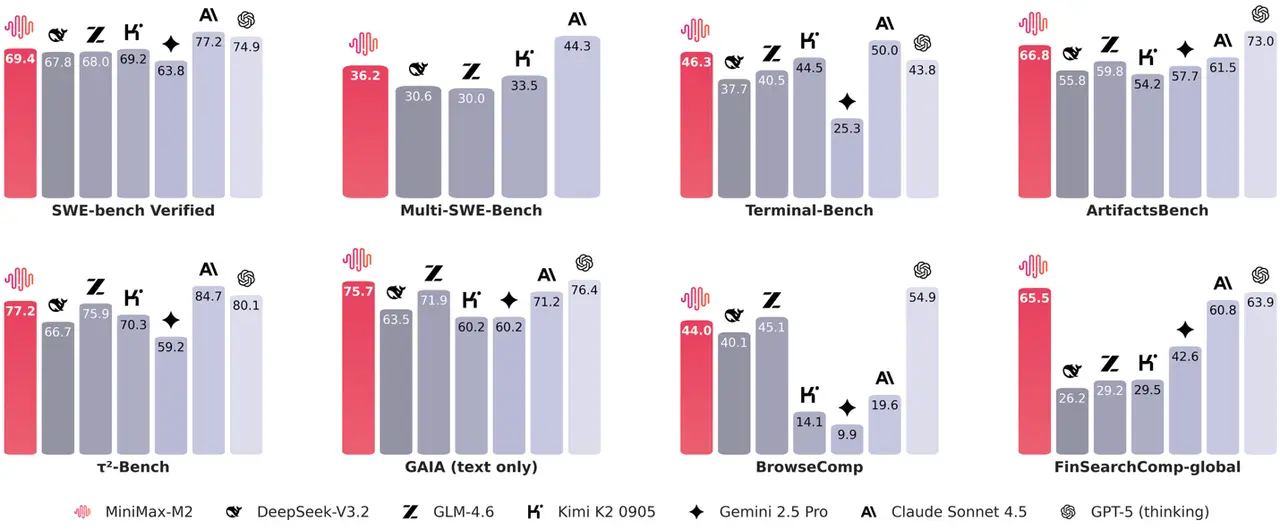
Coding Benchmarks: Excels on Terminal-Bench and (Multi-)SWE-Bench tasks with multi-file edits, compile-run-fix loops, and test-validated repairs.
Agentic Benchmarks: Strong performance in BrowseComp-style evaluations, locating hard-to-surface sources and handling flaky steps gracefully.
Competitive Edge vs GPT & Claude: Despite activating only 10 B of 230 B parameters, MiniMax M2 outperforms GPT-5 and Claude 4.5 in key agentic benchmarks such as BrowseComp (44 vs Claude 4.5: 19.6) and Terminal-Bench (46.3 vs GPT-5: 43.8), demonstrating high efficiency and strong task-specific performance.
MiniMax M2 performance highlights, as shown in MiniMax M2’s official benchmark results.
MiniMax-M2 demonstrates how carefully engineered architecture can deliver top open-source performance while remaining practical for real-world coding and agentic applications, combining speed, efficiency, and scalability.
Why MiniMax M2 Matters
MiniMax M2 proves that open-source LLMs can achieve top-performing levels while remaining practical:
Efficiency: 10 billion activations streamline compile-run-test and browse-retrieve-cite chains.
Accessibility: Open weights and APIs enable developers to deploy high-performance coding AI without top-tier infrastructure.
Developer-Centric: Optimized for terminals, IDEs, and CI pipelines, allowing rapid multi-file edits and agentic task execution.
MiniMax M2 vs GPT-5 and Claude 4.5
Different models shine in different workflows:
Key Points:
MiniMax‑M2 shows strong coding/edge-case handling and competitive performance in GAIA and τ²-Bench, but does not top SWE-bench or BrowseComp.
GPT‑5 leads in BrowseComp (54.9) and maintains high scores across benchmarks, reflecting versatility.
Claude 4.5 has the highest SWE-bench (77.2) and τ²-Bench (84.7), indicating strength in coding reasoning and long-context understanding.
Overall, MiniMax‑M2 is competitive with GPT‑5 and Claude 4.5 in several benchmarks, especially in coding-focused tasks, but each model has distinct strengths depending on the evaluation metric.
Deployment and Practical Use
MiniMax M2 can be deployed both locally and in the cloud:
Model weights: HuggingFace repository.
API: MiniMax Open Platform for rapid experimentation (free for a limited time)
Inference Tips: Use temperature=1.0, top\_p=0.95, top\_k=40; retain \ tags for interleaved reasoning.
Looking Forward
MiniMax M2 reflects a broader 2025 trend: open-source models approaching top-performing capabilities. With coding intelligence, agentic reasoning, and deployment efficiency, it sets a new standard for accessible, high-performance AI and redefines how developers tackle multi-step coding and interactive workflows.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.