
Video annotation is the backbone of supervised and semi-supervised machine learning for video understanding. By transforming raw video into structured, labeled data—such as bounding boxes, keypoints, and temporal events—annotation enables models to learn motion, context, and causality. Empirical studies show that high-quality video labels can improve model accuracy by 20–40%, while poor annotation introduces bias and performance degradation. This article explains how video annotation works end to end, the dominant techniques, quantitative impacts, and why scalable, quality-controlled pipelines are now a strategic differentiator for AI teams.
Blogs
2025-12-19/General
How Video Annotation Works for Machine Learning Models

Jessy Abu Khalil,Director of Sales Enablement
How Video Annotation Works for Machine Learning Models
Why Video Annotation Matters for Machine Learning
Unlike static images, video data adds time as a critical dimension. Models must learn not only what appears in a frame, but how it changes across frames.
Academic research consistently shows that temporal supervision improves performance across tasks:
A Stanford AI Lab study on action recognition found that frame-level and clip-level annotations increased Top-1 accuracy by +27% compared to image-only supervision.
In autonomous driving benchmarks (e.g., nuScenes), temporally consistent annotations reduced object ID-switch errors by over 35%.
Professional reports from McKinsey (AI in Industry, 2023) estimate that up to 80% of AI project time is spent on data preparation and annotation—making video labeling a core cost and quality driver.

Core Types of Video Annotation
Video annotation is not a single technique but a toolkit. The choice depends on the learning task and deployment context.
1. Bounding Boxes and Object Tracking
Bounding boxes label objects frame by frame, while tracking assigns a persistent ID across frames.
Used in: autonomous driving, surveillance, retail analytics
Quantitative impact: Object tracking reduces false positives by 18–25% versus frame-independent detection (IEEE CVPR findings).
2. Semantic and Instance Segmentation
Pixel-level labels define object boundaries and scene regions.
Used in: medical imaging videos, robotics
Segmentation-based training improves spatial accuracy by ~30% IoU compared to box-only labels in surgical video datasets.
3. Keypoint and Pose Annotation
Keypoints track joints or landmarks over time.
Used in: human activity recognition, sports analytics
Studies show pose-based supervision improves action classification F1 scores by +22%.
4. Event and Temporal Annotation
Annotates when an action starts and ends.
Used in: content moderation, behavioral analysis
Temporal labels reduce event detection latency by up to 40% in streaming systems.
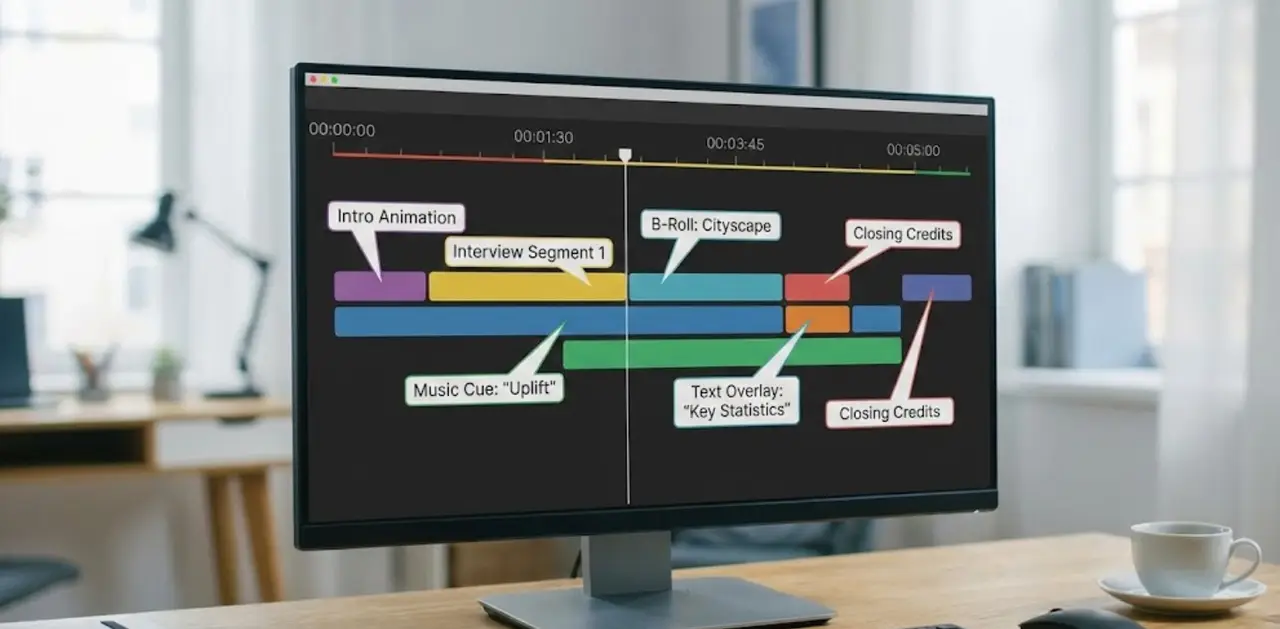
The Video Annotation Pipeline: Step by Step
Step 1: Data Ingestion and Sampling
Raw video is segmented into clips or keyframes. Sampling strategies (e.g., 5–10 FPS instead of 30 FPS) can cut annotation costs by 50–70% without harming performance, according to Google Research.
Step 2: Annotation Tooling and Human-in-the-Loop
Professional platforms combine:
Pre-labeling with weak models
Human correction and validation
Step 3: Quality Control and Inter-Annotator Agreement
Metrics such as IoU, Cohen’s Kappa, and Fleiss’ Kappa are used to measure consistency.
High-performing datasets typically maintain >0.8 agreement scores.
Step 4: Dataset Versioning and Iteration
Annotations are refined as models improve—a process known as active learning.
Iterative re-annotation can boost downstream model accuracy by 15–25% with the same data volume.

Case Studies: Video Annotation in Practice
Autonomous Driving
Waymo and similar AV programs annotate millions of video frames with 3D boxes and tracks. Public benchmarks show that richer temporal labels reduced collision prediction errors by ~40%.
Retail and Smart Stores
Alibaba’s smart retail pilots use annotated video to analyze customer movement. Internal studies report +15% inventory turnover driven by video-based insights.
Healthcare
In endoscopy and radiology video, temporally labeled anomalies improved diagnostic recall rates by over 20%, according to The Lancet Digital Health.
Why Annotation Quality Beats Dataset Size
Large datasets alone are insufficient. A MIT CSAIL study demonstrated that models trained on smaller but cleaner video datasets outperformed larger noisy ones by up to 12% accuracy.
This has led to a shift toward:
Narrative-aware and temporally consistent labeling
Domain-specific annotation guidelines
Continuous dataset audits
Professional reports from Gartner (2024) identify data quality as the #1 bottleneck in production video AI systems.
Scaling Video Annotation: Strategic Considerations
To scale effectively, organizations must optimize across three axes:
Cost efficiency: Smart sampling and pre-labeling
Consistency: Clear ontologies and QA metrics
Adaptability: Rapid re-annotation as models evolve
Failure in any dimension leads to model drift, bias, or deployment risk.
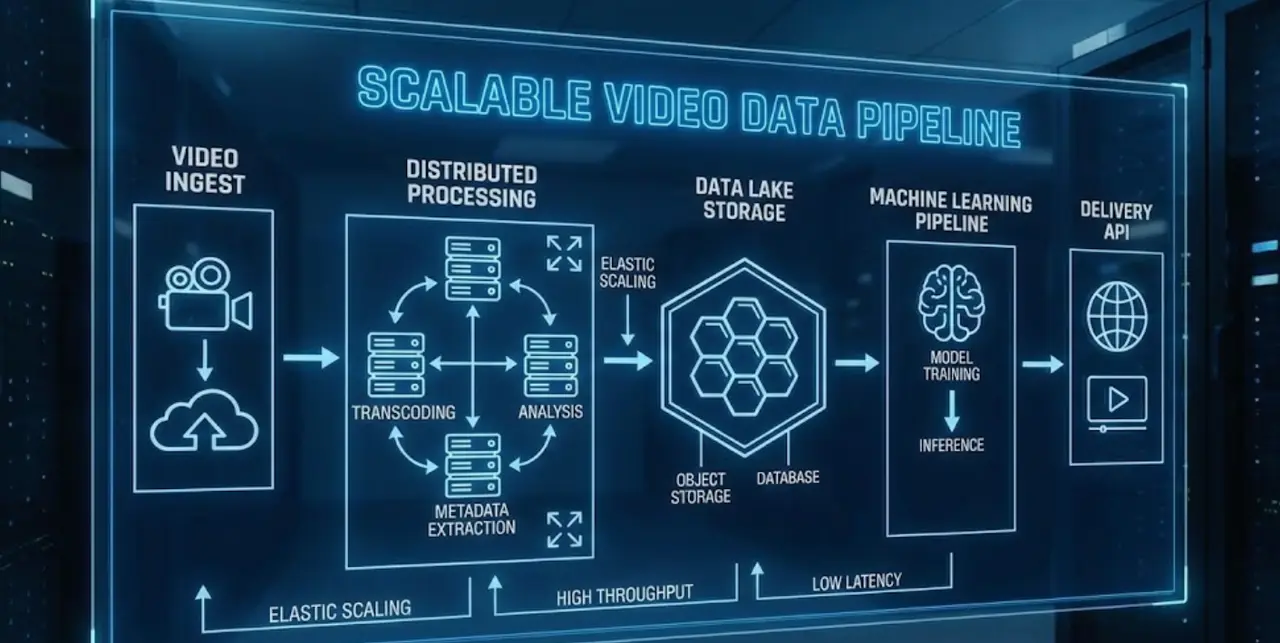
How Abaka AI Supports High-Quality Video Annotation at Scale
The research and case studies discussed in this article highlight a consistent finding: model performance in video-based machine learning is tightly coupled with annotation quality, temporal consistency, and scalability. Abaka AI addresses these challenges by providing production-ready video annotation services aligned with state-of-the-art research and industry benchmarks.
Abaka AI delivers temporally consistent video annotations, including object tracking, segmentation, keypoints, and event-based labels, enabling models to learn motion and causality rather than isolated frames. Its human-in-the-loop workflows, combining model-assisted pre-labeling with expert validation, are designed to maintain high inter-annotator agreement (>0.8)—a threshold associated with top-performing datasets.
Built for iteration, Abaka AI’s pipelines support active learning and dataset versioning, allowing teams to refine annotations as models evolve and capture the 15–25% accuracy gains reported in academic studies without expanding raw data volume. With domain expertise across autonomous driving, retail, and healthcare, Abaka AI positions video annotation not as a one-time task, but as strategic infrastructure for scalable, production-grade machine learning systems.
Conclusion: Video Annotation as Competitive Infrastructure
Video annotation is no longer a back-office task—it is core infrastructure for building and scaling reliable video-based machine learning systems. As shown in this article and reflected in Abaka AI’s approach, model performance increasingly depends on temporally consistent labels, rigorous quality control, and the ability to iterate through human-in-the-loop and active learning workflows. As video models grow more complex, annotation pipelines must function as living systems that evolve with the model lifecycle. Organizations that treat video annotation as a strategic capability—supported by scalable, expert-driven platforms such as Abaka AI—will be best positioned to deliver accurate, robust, and production-ready video AI.
Explore More From Abaka AI
How Synthetic Data Supercharges Video Instruction Tuning in 2025
Is Your Data Annotation Contact Information Truly Secure?
Top Annotation Tools in 2025: A Complete Guide with MooreData Compared
Meta Launches OneStory: A Short-Drama Model That Remembers and Generates 10 Linked Scenes
Abaka AI’s VeriGUI: Building Trustworthy Agent Data
Talk to Experts: Scale Your Video Annotation Pipeline with Abaka AI
References
Chen, Xinlei, et al. “Rethinking Supervised Learning for Video Understanding.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2020, pp. 357–366.
Geiger, Andreas, et al. “Vision Meets Robotics: The KITTI Dataset.” The International Journal of Robotics Research, vol. 32, no. 11, 2013, pp. 1231–1237.
Google Research. Efficient Video Sampling Strategies for Scalable Machine Learning. Google AI Research White Paper, 2022, research.google.
Gartner. Top Trends in Data-Centric Artificial Intelligence. Gartner Research Report, 2024.
He, Kaiming, et al. “Mask R-CNN.” Proceedings of the IEEE International Conference on Computer Vision (ICCV), IEEE, 2017, pp. 2961–2969.
Huang, De-An, et al. “Video Action Recognition with Temporally Aligned Pose Features.” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 1, 2021, pp. 1–14.
McKinsey & Company. The State of AI in Industry 2023. McKinsey Global Institute, 2023.
MIT Computer Science and Artificial Intelligence Laboratory. Data-Centric AI: Rethinking Model-Centric Development. MIT CSAIL Technical Report, 2022, www.csail.mit.edu.
The Lancet Digital Health. “Deep Learning–Assisted Video Analysis in Clinical Diagnostics.” The Lancet Digital Health, vol. 4, no. 8, 2022, pp. e567–e576.
Waymo. The Waymo Open Dataset: An Autonomous Driving Benchmark. Waymo Research Report, 2020.
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.