
Meta AI has introduced OneStory, a breakthrough framework that solves the "amnesia" problem in generative video by enabling consistent, multi-shot storytelling. Unlike current models (e.g., Sora, Gen-3) that struggle with continuity, OneStory uses a "Frame Selection" brain and "Adaptive Conditioner" to maintain character and background identity across distinct scenes. Powered by a curated dataset of 60,000 narrative-rich videos, this architecture outperforms existing benchmarks, effectively functioning as an automated director for coherent long-form video content.
Blogs
2025-12-16/General
Meta Launches OneStory: A Short-Drama Model That Remembers and Generates 10 Linked Scenes

Yuna Huang,Marketing Curator
Meta Launches OneStory: A Short-Drama Model That Remembers and Generates 10 Linked Scenes
The "3-second clip" era of AI video is ending. While models like Sora, Kling, and Gen-3 have mastered visual fidelity, they struggle with the filmmaker's most fundamental tool: narrative consistency over time.
Current Image-to-Video (I2V) models usually produce a single continuous scene. Ask them to generate a second shot of the same character from a different angle, and the face changes, the clothes morph, and the background glitches. This is the "amnesia" problem of generative video.
Meta AI has just addressed this bottleneck with OneStory, a new framework that generates coherent, multi-shot videos. It doesn't just generate pixels; it "remembers" context across 10+ linked scenes, effectively acting as an automated director for short dramas.
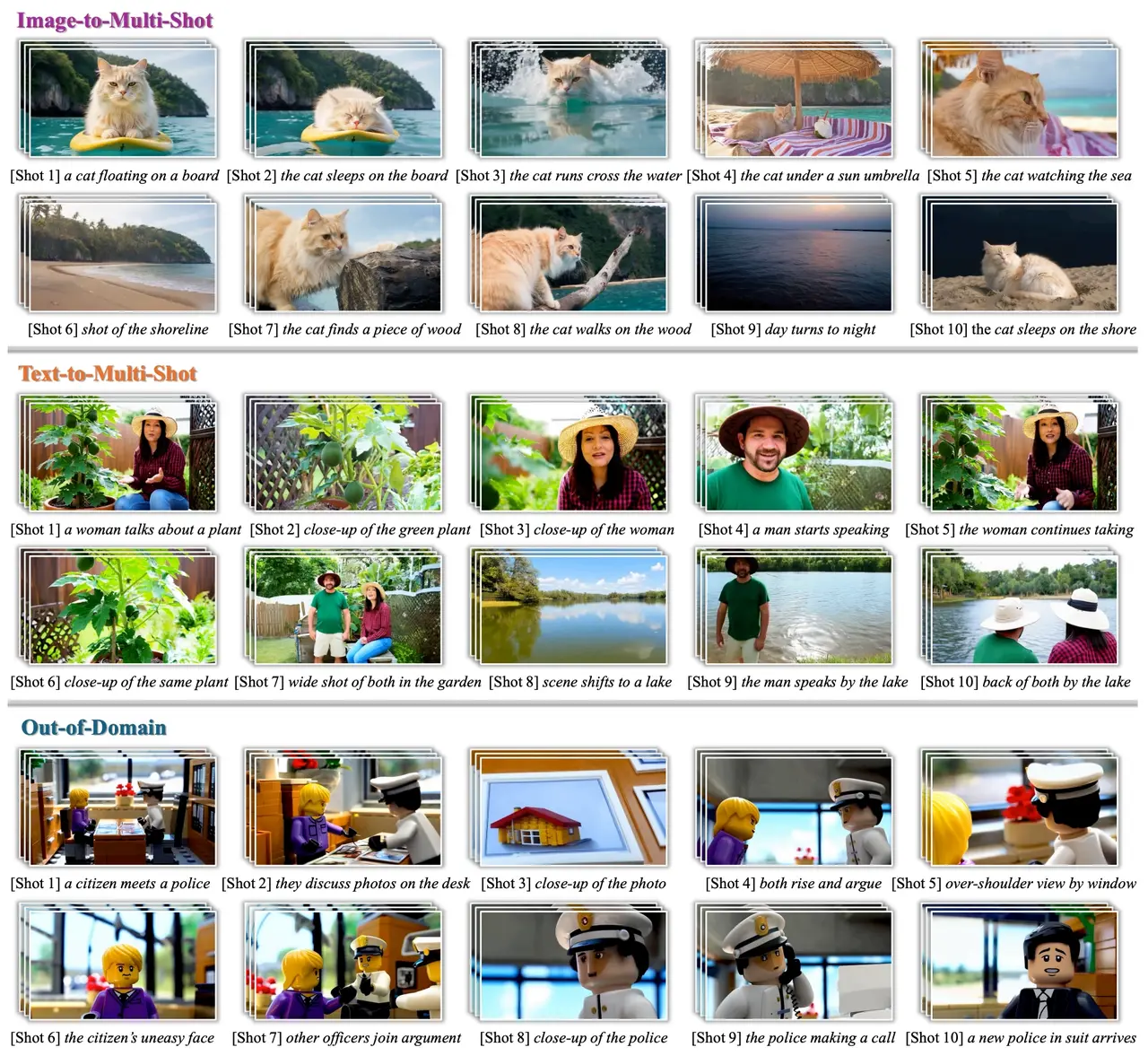
Here is the technical breakdown of how OneStory works, why its "Adaptive Memory" is a game-changer, and why data curation was the hidden engine behind this breakthrough.
The Problem: Why AI Directors Have "Amnesia"
To understand OneStory, we must look at why previous Multi-Shot Video (MSV) attempts failed. Existing methods generally fall into two traps:
Fixed-Window Attention: The model looks at a specific window of previous frames (e.g., the last 3 seconds). As the video progresses, the window slides forward, causing the model to "forget" what the protagonist looked like in Shot 1 by the time it reaches Shot 5.
Keyframe Conditioning: The model generates a single image (keyframe) for the next shot and animates it. This limits context to a single static image, losing the complex motion and narrative cues from the previous video sequence.
OneStory reformulates the problem entirely. Instead of treating video as a block, it treats it as a "Next-Shot Generation Task"—similar to how LLMs predict the next token, OneStory predicts the next shot.
The Solution: An Autoregressive "Brain" for Video
To achieve consistent storytelling without exploding computational costs, Meta introduced a novel architecture that mimics human memory.
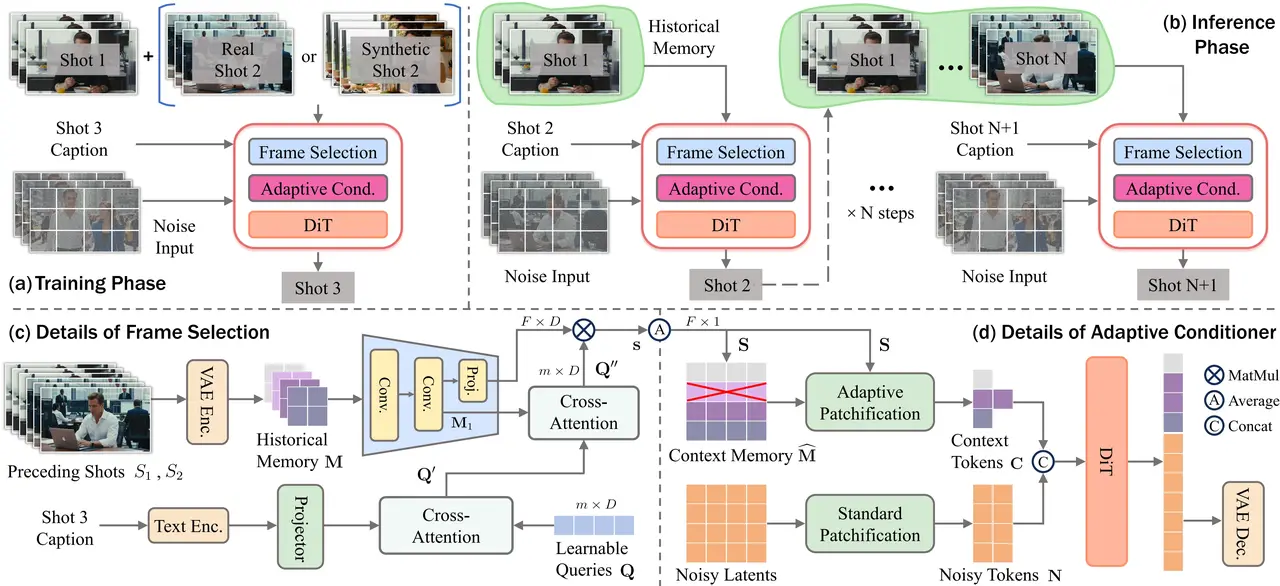
The "Brain": Frame Selection Module
In a movie, Shot 10 might reference Shot 1 (the protagonist's face) rather than Shot 9 (a landscape). OneStory acknowledges that adjacent shots aren't always the most relevant.
The Frame Selection module builds a "global memory" by selecting a sparse set of informative frames from all prior shots. It scores frames based on semantic relevance to the current caption. This allows the model to recall specific details—like a shirt color from minute one—even if the character hasn't been on screen for thirty seconds.
The "Compressor": Adaptive Conditioner
Feeding raw frames into a diffusion model is computationally expensive. The Adaptive Conditioner dynamically compresses the selected frames. Instead of treating all history equally, it assigns "finer patchifiers" (less compression) to high-importance frames and higher compression to less relevant background details. This allows OneStory to inject a global context directly into the generator efficiently.
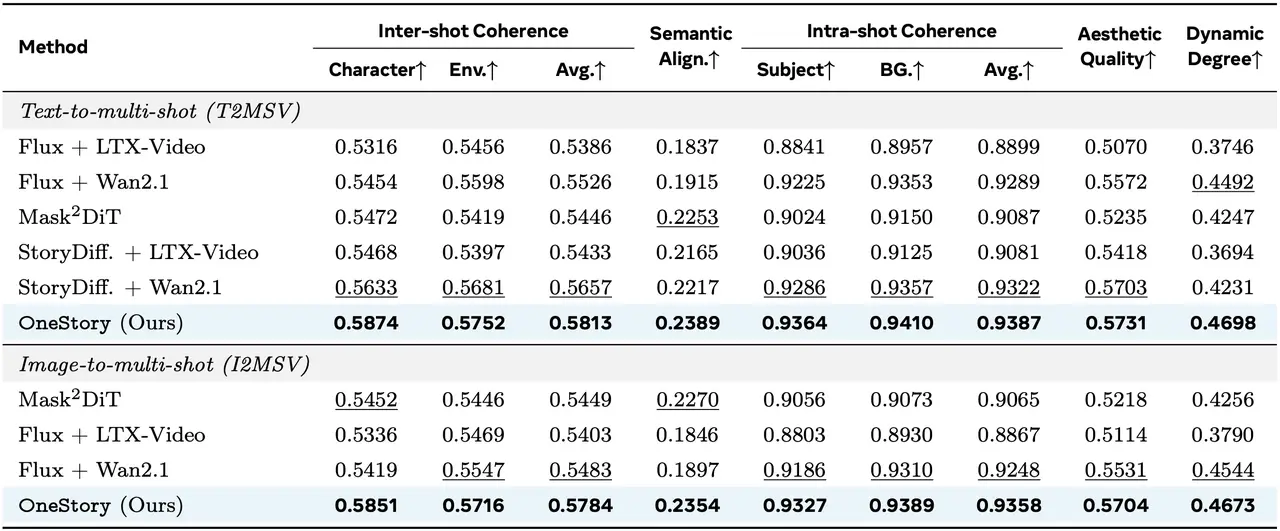
The Evidence: Beating the Benchmarks
Theory is good, but performance is better. How does OneStory stack up against current state-of-the-art pipelines like Flux combined with Wan2.1 or LTX-Video?
The Hidden Engine: Why Data Quality Was Key
We often say that algorithms are the car, but data is the fuel. OneStory is the perfect proof of this.
The architecture alone wasn't enough. To make OneStory work, Meta had to curate a brand new, high-quality dataset of 60,000 multi-shot videos. They couldn't use standard stock footage; they needed videos with "referential narrative flow", which teaches the model that entities (people, objects) are persistent, solving the identity consistency problem at the data level.
The leap from single-shot to multi-shot video generation requires a massive upgrade in data strategy. As the OneStory paper demonstrates, generic metadata is no longer sufficient. Models now require narrative-aware annotation and interlinked datasets.
If you are building the next generation of video models, don't let your data break the story.
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.