
Synthetic data is now the engine behind modern video-language models. As real-world footage becomes too costly, collection too slow, and inconsistent to meet rising training demands, synthetic video pipelines deliver the scale, diversity, and temporal reasoning models need. In 2025, they shifted from optional improvement to foundational infrastructure for video instruction tuning.
Blogs
2025-12-12/General
How Synthetic Data Supercharges Video Instruction Tuning in 2025

Nadya Widjaja,Director of Growth Marketing
How Synthetic Data Supercharges Video Instruction Tuning in 2025
Video models are evolving faster than the infrastructure that supports them. Real-world footage is scarce, expensive, slow to annotate, and often restricted by privacy or licensing. At the same time, video language models now demand longer sequences, richer temporal structure, and denser supervision to reach performance benchmarks.
Synthetic data has emerged as a scalable solution, not only as a temporary fix, but as the new backbone of video instruction tuning in 2025.
Before we dive deeper, Abaka AI had previously introduced Video Instruction Tuning with Synthetic Dataand the LLaVA-Video-178K dataset. This article expands the conversation, highlighting how synthetic pipelines have changed since then, including NVIDIA's simulation ecosystem and more mature synthetic pipelines that now supercharge video model performance across video-language tasks.
As McKinsey's State of AI in 2025 highlights, many organizations struggle to scale AI initiatives because their data foundations aren't ready. Synthetic video data changes that equation, offering consistency, scale, controllability, and instruction richness that real-world footage cannot match.
What Makes Synthetic Data Essential for Video Models in 2025?
The demand for video-instruction training far outweighs the supply of real, annotated video datasets. According to the McKinsey Global AI Report (2024), multimodal model development now consumes 5-10x more data per parameter than text-only models. Gartner forecasts that by 2026, 60% of enterprise AI teams will rely on synthetic video data for training or fine-tuning (Gartner Emerging Technology Radar, 2024).
Real video rarely contains frame-level temporal annotations, is noisy and includes irrelevant scenes, introduces licensing or privacy risks, and almost never captures rare or safety critical scenarios that matter for real-world agents.
Synthetic data solves these limitations, with platforms such as NVIDIA Isaac Sim & Replicator now automating domain randomization, lighting and material variation, programmatic camera paths, multi-sensor outputs including RGB, depth, and segmentation, and perfect ground truth labels for every frame.
This isn't a "fake video" production. This is video engineered for learning, characterized as consistent, controllable, and instruction-aligned.
How Does Synthetic Data Improve Temporal Reasoning?
Most video models struggle not with identifying objects, but with when, why, and how events occur. Temporal reasoning is the weakest point of modern video models, and synthetic data provides the structure needed to overcome it. Insights from the NVIDIA workshop (covered in the next section) further demonstrate how synthetic pipelines strengthen temporal reasoning at scale.
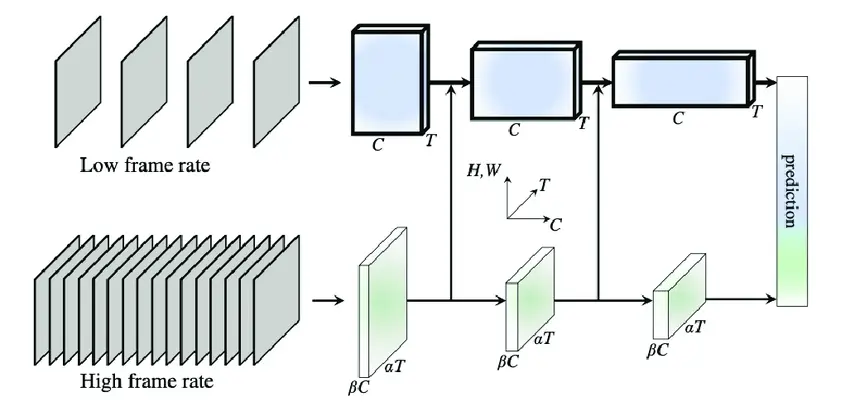
Frame-level descriptions = capture object states, motion, and context at each moment
Segment-level summaries = condense meaningful transitions and event boundaries
Full-video narratives = explain causality, intention, and sequence coherence.
This structure gives models a built-in instruction guide, moving from perception to interpretation to reasoning. Their model outperformed several real-data-trained systems on major video benchmarks.
Carefully designed synthetic data isn't just an alternative. It is a performance accelerator.
How Does NVIDIA's Synthetic Pipeline Supercharge Data Diversity?
NVIDIA's Isaac Sim and Replicator workshop revealed how teams now generate at scale:
Domain Randomization at Scale, generalizing models by varying:
Object position, rotation, material, color
Lighting temperature & intensity
Camera viewpoint & trajectory
Scene distractors (barrels, boxes, signs, tools)
Automatic Perfect Labels, making manual annotation errors drop down to 0%.
Replicator produces:
RGB, Depth, Camera parameters
Instance, semantic segmentation
3D bounding boxes
Physics-consistent movement
Complex Physical Environments, extremely rare in real-world video datasets.
Synthetic scenes support:
Multi-agent interactions
Motion chains
Realistic occlusions
Scene perturbations
Evidence of Real-World Transfer. In NVIDIA's pallet jack demonstration, a model trained on synthetic data combined with minimal real footage outperformed real data-only baselines. Introducing distractors reduced false positives and improved spatial grounding.

What Should AI Teams Prioritize Before Scaling Video Instruction Tuning?
A few recommendations for you and your team:
Define your taxonomy instruction first. Models trained on clean instructional hierarchies consistently show better coherence and reasoning quality across video-language tasks.
Use dense-frame sampling before upscaling. More frames means better temporal grounding, which consequently means fewer hallucinations.
Add distractors intentionally. NVIDIA's findings show that diversity reduces false positives and improves scene robustness.
Blend synthetic and real data. A hybrid dataset is almost always better than either source alone.
Expand beyond RGB. Depth, segmentation, and 3D cues strengthen spatial reasoning and model robustness.
Key Takeaways
Synthetic data is no longer secondary but foundational for video models.
NVIDIA's Replicator pipeline shows that large scale variation closes the synthetic to real world gap.
Studies show that synthetic video improves benchmark accuracy by 20-30% when carefully constructed.
The future of multimodal AI depends not just on larger models, but smarter video data pipelines.
Want to Learn More About How Abaka AI Supports High-Quality Video Training Data?
Contact Us - Speak with our specialists about synthetic data generation, video annotation workflows, or how to scale multimodal training pipelines with enterprise-grade QA.
Explore Our Blog - Read more on multimodal annotation, synthetic data, LLM evaluation, and best practices for building reliable AI systems.
See Our Latest Updates - Discover new releases, product enhancements, and partnerships shaping the future of video AI at Abaka AI.
Read Our FAQs - Find answers to project workflows, data generation standards, and synthetic video requests.
How Synthetic Data Supercharges Video Instruction Tuning in 2025
Explore More From Abaka AI
Privacy-First Marketing: Why Synthetic Data Replaces Real Customer Data
Video Datasets: Powering Embodied AI for Real-World Interaction
Synthetic Data for LLM Training and Fine-Tuning: The Complete Guide
Some Further Reading
👉Lessons from Scaling Synthetic Data for Trillion-scale Pretraining
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.