AI systems are only as good as the data they learn from. This guide explains what AI training data services are, how they work, and why modern AI development depends on high-quality datasets, human feedback, and well-governed data pipelines.
AI systems are only as good as the data they learn from. This guide explains what AI training data services are, how they work, and why modern AI development depends on high-quality datasets, human feedback, and well-governed data pipelines.
AI training data services are the set of processes used to turn raw data into data that a machine learning model can reliably learn from. In simple terms, that includes preparing training examples, supporting fine-tuning, building evaluation sets, incorporating human feedback (Ouyang et al., 2022), and documenting how the data was collected, labeled, and managed over time. For that reason, these services are not limited to annotation alone.

At a business level, companies pay for the people, workflows, and infrastructure needed to make data usable for model development. Amazon SageMaker Ground Truth (Amazon Web Services, n.d.). For example, it describes building high-quality labeled datasets by combining human workers, task design, and optional automation. Training data services go way beyond adding labels, as they actually encompass a structured part of the model-development pipeline.
Even the most capable models depend on data quality. A model can only learn from the examples it is given, so the way a dataset is collected, structured, and labeled directly affects performance. Nowadays, the phrase ‘AI training data services’ does not only ring a bell in annotation related tasks; but it also refers to metadata, evaluation design, and compliance-related documentation.
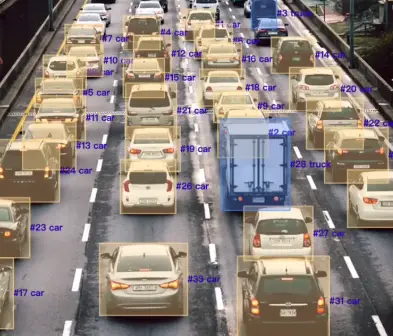
A common source of confusion is that people often mix up data formats with data functions. A provider may work with image, video, audio, or text files, but those files can each play different roles in the machine learning process. The most useful distinction for beginners is to focus on the role the data plays.
Pretraining data: the large-scale dataset used to train a foundation model on broad patterns in language, images, code, e.g, before task-specific adaptation.
Fine-tuning data: a smaller, more targeted dataset used to adapt a model to a particular task, domain, or style.
Evaluation data: the data used to test how well the model performs. In current AI systems, this often includes not only accuracy checks but also safety, quality, and consistency checks (Google for Developers, n.d.).
Human feedback data: feedback data mainly refers to interventions (rankings, comparisons, demonstrations and judgements) provided by humans that exemplify human preferences to improve model behavior (Ouyang et al., 2022).
Synthetic data, as IBM defines it (IBM, n.d.) is artificial data designed to mimic real-world data generated through statistical methods or by using artificial intelligence techniques like deep learning and generative AI.
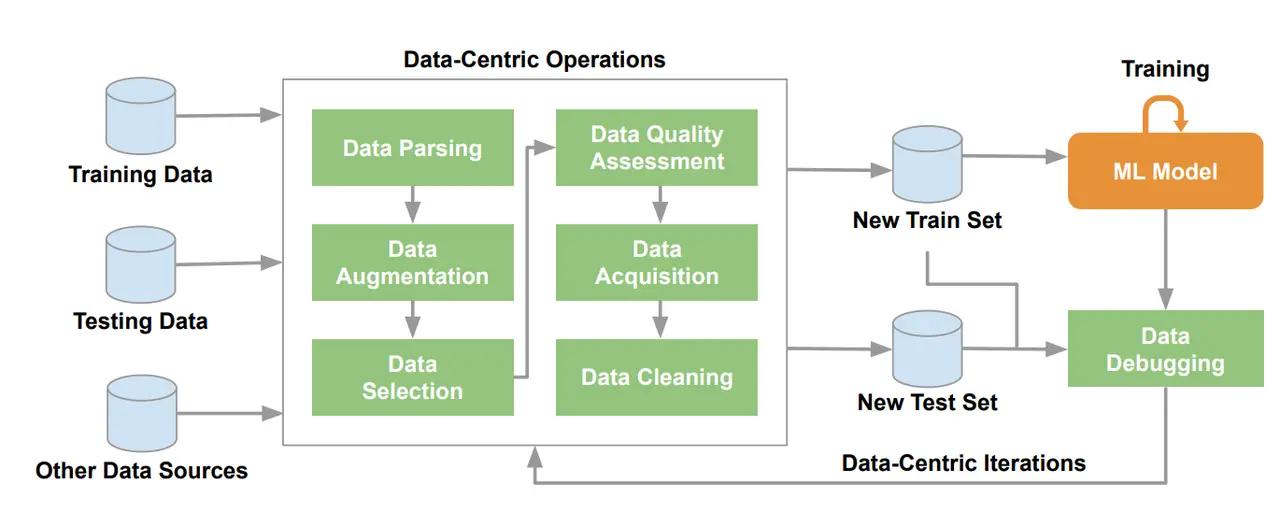
Guaranteeing high quality data is not a simple task, but when we break it down to its core five steps, it looks something like this.
First, they collect or organize data from the sources a model will need. Second, they clean and prepare it by removing noise, splitting datasets, and structuring files and metadata. Third, they label or annotate raw data (images, text files, videos, etc.) so the model can learn from it. Fourth, they check quality through its level of accuracy and consistency. Fifth, they document provenance, constraints, transformations, and compliance requirements so the data can be reused and audited.
This practical sequence matters because AI development is no longer just a matter of sending files to labels and receiving them back with tags attached, hence, even the human workers and the workflow templates are part of a larger data-labeling system. Businesses have quickly adapted from being annotation vendors and have become specialized in data operations, evaluation, and governance; demonstrating seriousness in a rapidly advancing industry.
As we concluded in the last section, annotation has become part of a much larger system. Where and how do we see this exemplified?
First, a shift to higher-quality and more refined data pipelines. For instance, DataPerf (Mazumder et al., 2023), argues that machine learning research has historically focused more on models than on datasets, and that better data quality is increasingly necessary for generalization, safety, and bias reduction.
Second, the proliferation and adoption of multimodal AI. Modern systems increasingly work across text, image, audio, video, or combinations of them. As a result, a more holistic understanding of complex relationships and operation systems has arisen (TileDB, 2026).
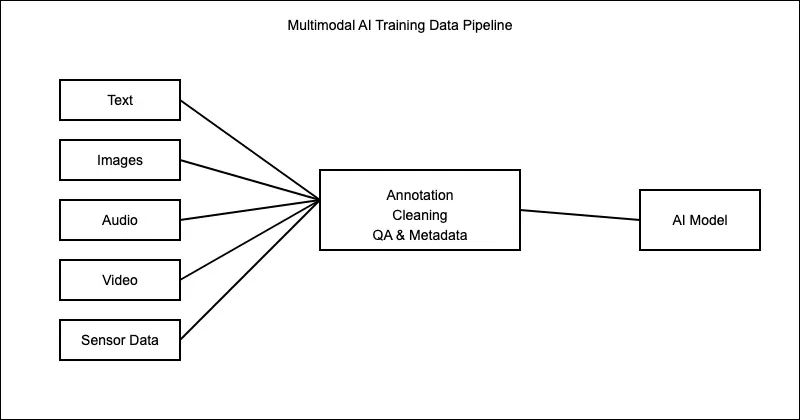
Third, there is much greater emphasis on traceability, privacy, copyright, and risk. NIST states that maintaining the provenance of training data supports transparency and accountability, and also notes that training data may be subject to copyright law. Likewise, the European Commission’s guidance on general-purpose AI models highlights requirements related to technical documentation, copyright policy, and training content summaries (European Commission, n.d.; NIST, 2023).
Fourth, enterprises increasingly need repeatable workflows, not one-off annotation projects. Teams increasingly need systems that can be maintained, audited, updated, and integrated into broader development processes such as workforce design, automation and quality review.
Fifth, data-centric AI has become easier to explain and easier to defend. This means that instead of assuming that the model architecture is always the main bottleneck, data-centric AI asks whether better results may come from improving the dataset. In plain language, this means that cleaner labels, better edge cases, more representative coverage, and more faithful examples can materially improve performance (Mazumder et al., 2023).
Finally, countries and standards bodies have responded with regional governance frameworks. In Europe, the AI Act takes a risk-based approach and includes obligations for providers of general-purpose AI models, including technical documentation, copyright policy, and training content summaries (European Commission, n.d). In the U.S., NIST’s AI Risk Management Framework provides a voluntary structure for governing, mapping, measuring, and managing AI risks across the lifecycle (NIST, 2023).
In practical terms, good training data in 2026 is not just large. It is relevant to the task, accurate enough to survive review, diverse enough to reflect real-world variation, documented well enough to be audited, and compliant with current legal and governance expectations.
To put it simply, before we labeled boxes and tags, we now built reliable, compliant and reusable data pipelines for training, fine tuning and evaluating modern AI systems.
The short answer is that they often try, but the work expands quickly. High-quality training data requires not just people, but project design, detailed instructions, quality review, tooling, storage, metadata, and ongoing iteration. Many companies want to keep all their data and workflow within their system, but that requires building their own IP and creating a platform, which is possible with enough money and resources (Welo Data, 2024). Additionally, quality-control implies the need for gold standards, agreement scoring, and correction loops; which is why vendor platforms emphasize benchmark labels, consensus scoring, and performance monitoring rather than simple task completion. (Labelbox, 2023).
Oftentimes, this takes up to several weeks of building labeling workflows and managing a labeling workforce, and several companies lack the skills or eventually cannot take up the operational load.
AI training data services are best understood as the operational layer that makes modern AI possible. They do not merely attach labels to files. The earlier image of the field focused on labor at scale: label the data, deliver the batch, move on.
The newer image is broader and more demanding: data collection, curation, multimodal preparation, evaluation, provenance, and governance all work together as one system. If AI models are the visible product, training data services are the disciplined process that helps make those products reliable enough for real-world use.
If AI models are so advanced today, why do they still need large amounts of training data?
Even the most sophisticated AI models learn patterns from examples. A model does not “understand” the world in the way humans do; instead, it identifies statistical relationships between inputs and outputs. Training data provides those examples. The more relevant, diverse, and accurate the dataset is, the better the model can generalize to new situations. For this reason, improving datasets often leads to better performance than simply changing the model architecture.
How much training data does an AI model actually need?
There is no fixed amount. The quantity depends on the complexity of the task and the type of model being trained. Simple classification models may work with thousands of examples, while large language models or multimodal systems often require millions or billions of data points. In practice, the usefulness of the data matters more than the volume. A smaller dataset that is carefully curated and representative can sometimes outperform a much larger but poorly structured one.
How do companies know if their training data is good enough?
Teams usually evaluate training data indirectly through model performance and dataset audits. If a model consistently fails on certain inputs, that often signals gaps in the dataset such as missing examples, labeling inconsistencies, or insufficient diversity. Organizations may also run dataset evaluations, benchmark tests, and bias checks to identify weak areas before retraining the model with improved data.
What are the biggest risks associated with AI training data?
The most common risks involve bias, legal exposure, and poor data quality. If a dataset contains systematic biases, the model can reproduce them in its predictions. If data is collected without clear rights or documentation, companies may face copyright or privacy concerns. And if the dataset is noisy or inconsistent, the model may produce unreliable outputs. For this reason, modern AI development increasingly treats data governance, such as documentation, provenance tracking, and quality control; as part of the training pipeline itself.
How do AI systems keep improving after they are deployed?
Most modern AI systems are not trained once and left unchanged. Instead, they are updated through iterative cycles. Developers monitor performance, collect new data from real-world usage, identify errors or edge cases, and update training datasets accordingly. The model is then retrained or fine-tuned with the improved dataset. This feedback loop allows AI systems to gradually become more accurate and robust over time.
AI Training Data Services Explained: From Collection to Model Evaluation
Why Training Methods Matter More Than Model Size
Free vs Paid Training Datasets: Which is Better for AI Projects?
How Robotics Companies Build and Scale Training Data for Real-World Robots
LoopLLM: How Ouro Builds Reasoning Into Pre-training
2026’s Essential Multimodal Datasets for Embodied AI
Best Data Labeling Companies for AI in 2026: Who Can Actually Scale?
Best Multimodal Data Annotation Platforms in 2026: A Practical Comparison
Amazon Web Services. (n.d.). Training data labeling using humans with Amazon SageMaker Ground Truth. AWS Documentation.https://docs.aws.amazon.com/sagemaker/latest/dg/sms.html
European Commission. (n.d.). General-purpose AI models in the AI Act – Questions & answers. Shaping Europe’s Digital Future.https://digital-strategy.ec.europa.eu/en/faqs/general-purpose-ai-models-ai-act-questions-answers
Google for Developers. (n.d.). Fairness: Evaluating for bias. Machine Learning Crash Course.https://developers.google.com/machine-learning/crash-course/fairness/evaluating-for-bias
Labelbox. (n.d.). Quality analysis.https://docs.labelbox.com/docs/quality-analysis
Mazumder et al., DataPerf: Benchmarks for data-centric AI development. Advances in Neural Information Processing Systems, 36.https://proceedings.neurips.cc/paper_files/paper/2023/file/112db88215e25b3ae2750e9eefcded94-Paper-Datasets_and_Benchmarks.pdf
National Institute of Standards and Technology. (2023). Artificial intelligence risk management framework (AI RMF 1.0) (NIST AI 100-1). U.S. Department of Commerce.https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf
Ouyang et al., (2022). Training language models to follow instructions with human feedback. OpenAI.https://cdn.openai.com/papers/Training_language_models_to_follow_instructions_with_human_feedback.pdf
Google for Developers — Fairness: Evaluating for Bias https://developers.google.com/machine-learning/crash-course/fairness/evaluating-for-bias
What is multimodal AI: A complete 2026 guide https://www.tiledb.com/blog/multimodal-ai-guide
Contact Us– Learn more about how world models and interactive systems are evaluated.
Explore Our Blog – Read research and articles on embodied AI datasets, multimodal alignment, simulation grounded data, and evaluation beyond appearance alone.
Follow Our Updates – Get insights from Abaka AI on real-world robotics research, agent evaluation workflows, and emerging standards for interactive AI systems.
Read Our FAQs– See how teams design datasets and evaluation frameworks for systems that must act, adapt, and remain consistent over time.
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.
