LoopLLM: How Ouro Builds Reasoning Into Pre-training
Tatiana Zalikina,Director of Growth Marketing
LoopLM is a pre-training approach that enables large language models to reason during training by iterating over shared layers in latent space, rather than relying on post-hoc chain-of-thought prompting.
LoopLLM: How Ouro Builds Reasoning Into Pre-training
We are as shocked as you are. We used to think that reasoning in LLMs meant adding long “chain‑of‑thought” prompts and hoping for the best. Yeah, good old times. Because now there’s a new way to teach models to think: train them to reason during their core learning, not after. Enter Scaling Latent Reasoning via Looped Language Models (LoopLM) — the paper that flips the script on what “pre‑training” can mean.
What Is LoopLM? Ouro’s Looped Language Model Explained
In standard LLMs (https://www.abaka.ai/blog/llm-data-cost), reasoning often becomes a post‑script: the model generates text, then tries to “explain” or “reason” its answer via a chain‑of‑thought. But what if reasoning was baked into the pre‑training phase? That’s what LoopLM is about.
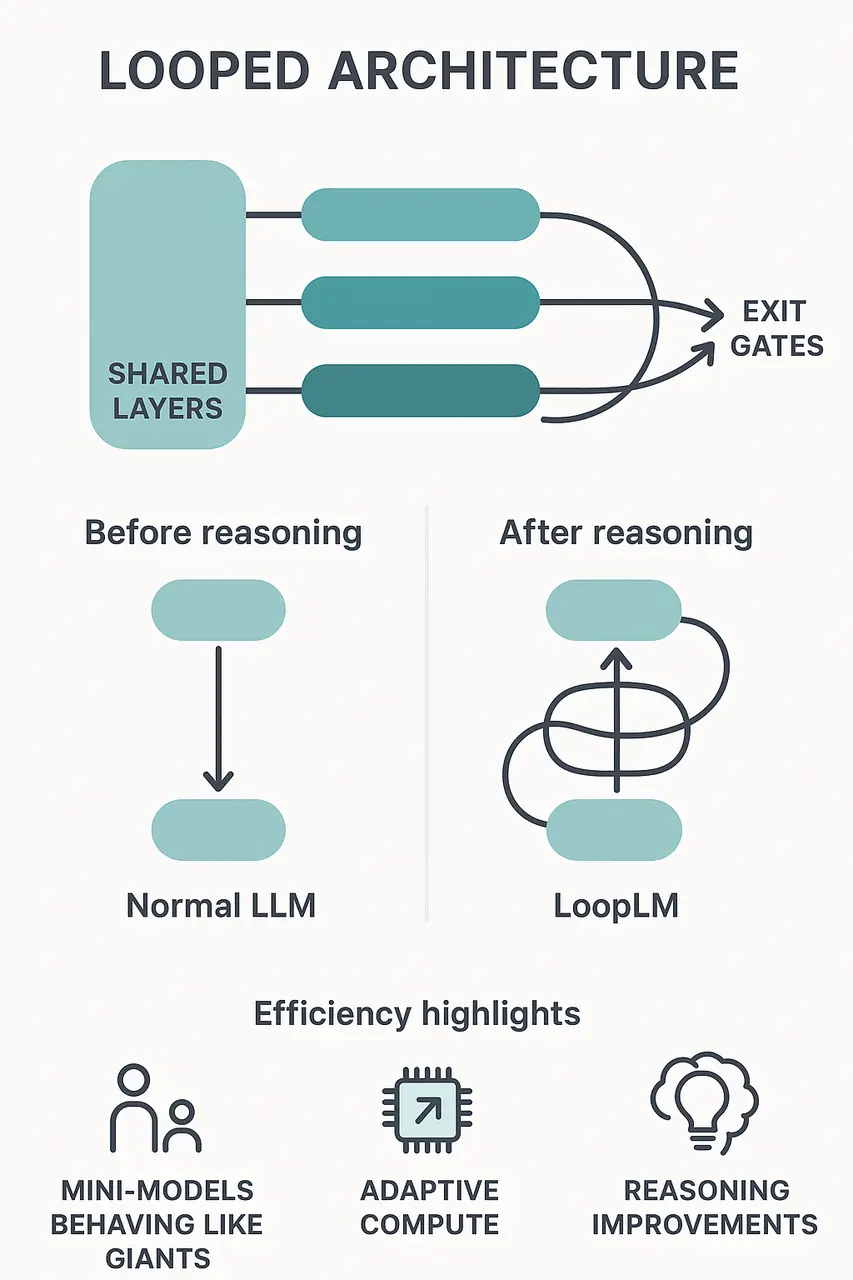
Iterate in latent space: the model loops over shared layers multiple times (rather than stacking ever more layers).
Adaptive depth through early exit gating: simple queries take fewer loops, hard ones take more, all dynamically learned.
Massive scaling: pre‑training on 7.7 trillion tokens, showing that smaller models (1.4B & 2.6B parameters) train to match larger ones (4B–12B) on reasoning tasks.
LoopLM visualisation, represents iteration and reasoning
How LoopLM Works: Looped Language Models and Latent Reasoning
As if a student who doesn’t write an answer once but rewrites it several times in their notebook, improving each draft. LoopLM does the same—internally:
Shared‑layer recurrence--Shared Layers in Looped Language Models:
Instead of unique layers for each depth, the same block is reused through “loops.”
Exit gate mechanism--Exit Gates and Adaptive Looping in LoopLM:
At each loop step, the model evaluates whether it has done enough and either stops or loops again, using fewer loops for simple questions and more for complex ones to learn the right balance of reasoning depth without stopping too early or looping excessively.
Fine‑grained reasoning capability--Why Latent Looping Improves Reasoning, Not Just Memory:
Because of looping, the model manipulates knowledge rather than just storing it—it gets better at using facts, not simply knowing them.
LoopLM visualisation, LoopLM refines its reasoning like a student iterating on drafts
Scaling Latent Reasoning via Looped Language Models (The Ouro Paper)
Why LoopLM Matters for Reasoning-Centric LLMs
Parameter‑efficiency: Mini‑models acting like giants. Ouro‑1.4B and 2.6B match or beat some 12B models on reasoning benchmarks.
Better reasoning traces: Not just long text reasoning, but internal loops that align with final answer more faithfully—less “I know but here’s me explaining weirdly.”
Adaptive compute: Faster on simple tasks, deeper on hard ones—efficiency and capability together.
A new “depth”: Beyond “more parameters” or “more data,” now “more loops” becomes a lever.
Limitations and Open Questions of LoopLM
This isn’t magic without caveats. Loop depth still needs calibration. Safety improves with more loops in some cases—but recall this doesn’t fix everything. And for deployment, supports like efficient inference stacks and adaptive gating must mature.
Looped architecture diagram, single-pass reasoning vs multi-pass refinement, and efficiency highlights
How Abaka AI Contributes
Abaka keeps the gears running behind the scenes—so your models don’t just function, they excel. They provide:
High‑accuracy annotation at scale, across 1 million+ specialist annotators, 50+ countries, for everything from simple labels to complex reasoning chains. If you have a custom task (reasoning chains, agent prompts, edge‑case scenarios), outsource it to our pipeline to save time and cost.
End‑to‑end model support: data collection → annotation → training support → model evaluation(https://www.abaka.ai/services/model_evaluation), so your loop from concept to deployment shrinks.
Strong ethics & compliance: GDPR/CCPA ready, full IP provenance, no copyright risk—your model’s foundation is legally solid.
If you’re exploring reasoning-first training or iterative model development, Abaka provides the data and evaluation backbone that makes these approaches practical at scale.
Contact us to learn more—and let’s build the future together.
FAQ
What is LoopLM in simple terms?
LoopLM is a pre-training method that allows language models to “think” multiple times internally by looping over shared layers during training, instead of generating a single-pass response.
How is LoopLM different from chain-of-thought prompting?
Chain-of-thought adds reasoning after training, at inference time. LoopLM embeds reasoning during pre-training, making multi-step reasoning a native capability rather than a prompting trick.
Does LoopLM require larger models or more parameters?
No. LoopLM reuses the same layers through loops, enabling smaller models to achieve reasoning performance comparable to much larger models without increasing parameter count.
What kinds of tasks benefit most from LoopLM?
LoopLM is especially effective for tasks requiring multi-step reasoning, planning, or iterative decision-making, such as math, logic, and agent-style workloads.
Is LoopLM ready for large-scale deployment today?
LoopLM is a promising research approach, but practical deployment still depends on efficient inference stacks, well-calibrated exit gates, and careful evaluation of safety and compute trade-offs.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.