Is RLHF Dead? Why AI Companies Are Moving Toward RLAIF
Natalia Mendez,Director of Growth Marketing
Is RLHF dead? Not entirely, but AI companies are rapidly adopting RLAIF for its scalability and cost-effectiveness. By using AI to generate feedback, RLAIF achieves equal or better results at a fraction of the cost. Humans remain essential but shift from volume labeling to high-level oversight and expert auditing.
Is RLHF Dead? Why AI Companies Are Moving Toward RLAIF
The many methods of Reinforcement Learning
As artificial intelligence technology rapidly advances, developers and researchers are in constant search for more effective methods to train sophisticated models. For years, Reinforcement Learning from Human Feedback (RLHF) has been the cornerstone technique for aligning AI behavior with human values and preferences.
However, the increasing demand for more scalable, cost-efficient, and streamlined training processes is now pushing the industry to explore its successor: Reinforcement Learning from AI Feedback (RLAIF).
While RLHF has undoubtedly driven significant improvements in model performance, it is not without its limitations. The primary challenges revolve around scalability and the substantial cost associated with collecting high-quality human preference data.
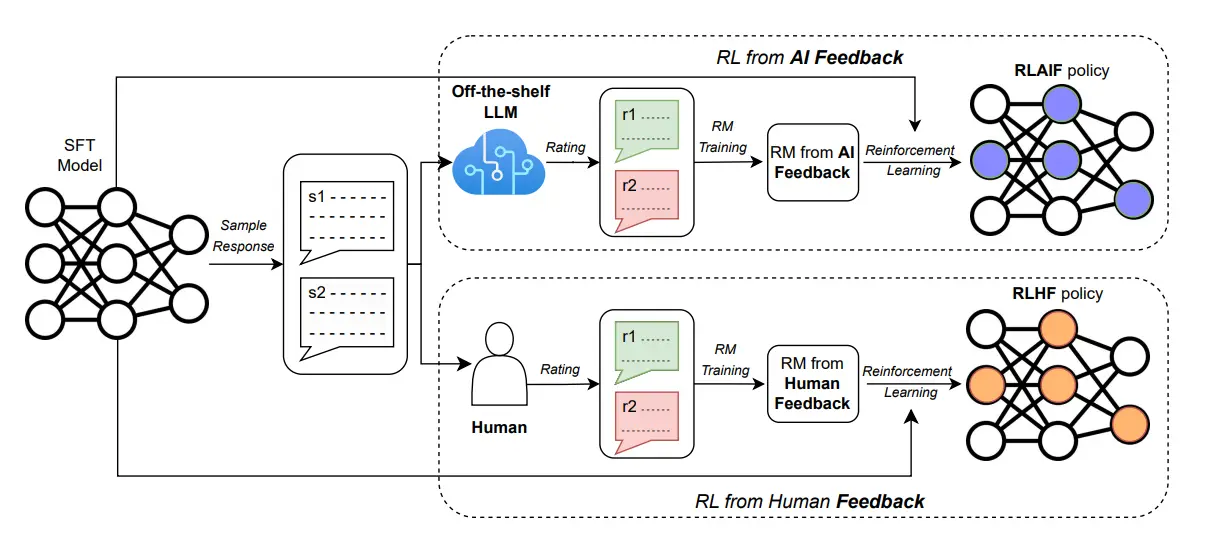
In response, RLAIF has emerged as a compelling alternative by training the reward model (RM) using preferences generated by a pre-existing large language model (LLM), rather than by humans (Lee et al., 2024).
In short, RLHF is used when human judgment is essential for nuanced tasks, but it fails when projects face budget constraints or require rapid scaling
The Rise and Challenges of RLHF
Reinforcement Learning from Human Feedback (RLHF) has been instrumental in the development of large AI systems, particularly in the field of natural language processing (NLP).
This technique uses human evaluations to guide a model's learning process, helping it refine its outputs—from generating more natural-sounding text to controlling robotic systems—based on direct human input.
Despite its successes, RLHF faces significant hurdles, both in terms of ethical alignment and practical business viability. Its core purpose is to meet human expectations, which inherently involves navigating complex and often conflicting cultural norms and moral values.
This required developers to design RLHF systems that could respect a diverse range of perspectives, a task that is incredibly difficult to scale.
Furthermore, RLHF systems are susceptible to risks associated with human bias and misinformation. If a malicious actor were to provide biased or false feedback, the model could be trained to generate and amplify misleading or harmful content.
For instance, OpenAI successfully utilized RLHF to align models like InstructGPT, GPT-3.5, and GPT-4. This process involved training a reward model on human preference comparisons and then fine-tuning the language model to maximize that reward.
However, the necessity of collecting extensive human feedback proved to be both costly and time-consuming, limiting the scalability of purely human-driven alignment. This bottleneck spurred research into alternatives, such as AI-generated feedback and constitutional training, to lessen the dependence on human annotators (Brown et al., 2020).
Similarly, in fields like autonomous driving, RLHF's human-in-the-loop approach creates a major bottleneck. It often requires expert human mentors to constantly monitor the AI agent and intervene when its behavior becomes unsafe.
This form of supervision is cognitively demanding, requiring sustained attention, rapid safety judgments, and repeated corrections across countless driving scenarios and rare edge cases (Hanson et al., 2024).
RLAIF: The New Paradigm for AI Training
As AI systems become more sophisticated, the limitations of RLHF have accelerated the development of Reinforcement Learning from AI Feedback (RLAIF). RLAIF directly addresses the challenges of human feedback by enabling AI systems to generate their own feedback.
In this paradigm, an AI model evaluates its own performance or that of other models, significantly speeding up the training loop and reducing the need for continuous human involvement.
What is RLAIF?
RLAIF, or reinforcement learning from AI feedback, has emerged as a powerful alternative to RLHF. In this approach, models are trained to critique performance, using feedback generated by another AI to automate the training process.
The key difference between RLHF and RLAIF is not the underlying reinforcement learning mechanism, but the source of the feedback—humans versus AI. This shift is estimated to be over ten times cheaper than relying on human annotation (Lee et al., 2024).
A diagram depicting RLAIF (top) vs. RLHF (bottom) From "RLAIF vs. RLHF," H. Lee et al., 2024.
The move toward RLAIF is driven by several key advantages:
Why the Shift Toward RLAIF?
Scalability: RLAIF excels when dealing with massive datasets or complex tasks. Automating the feedback loop makes processing vast amounts of data far more efficient and practical.
Cost-Effectiveness: RLAIF is a significant advantage for projects with budget constraints or limited resources, as it dramatically reduces the expense of collecting and annotating large datasets with human preferences.
Time Sensitivity: By eliminating the slow pace of extensive human involvement, RLAIF enables faster development cycles and more rapid model improvements (Toloka, n.d.).
Improved Alignment and Safety: AI feedback can be designed to be highly consistent and aligned with predefined goals. This consistency can help reduce the risks of introducing human biases and misalignments.
In short, RLAIF wins on speed and cost, while RLHF wins on nuanced human insight.
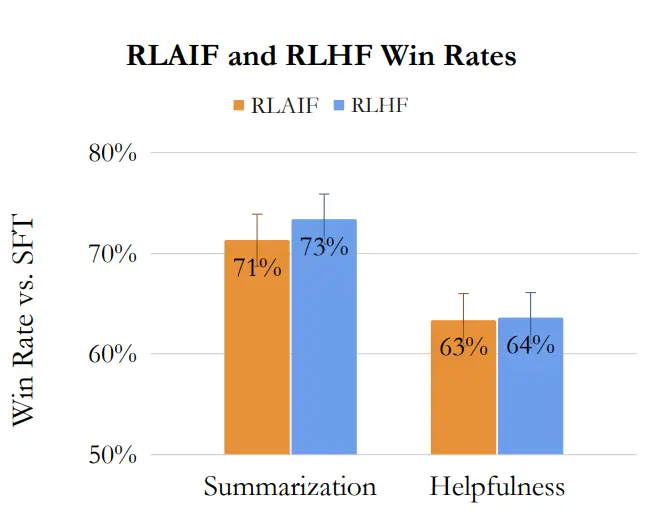
These advantages are supported by recent research. The paper "RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback", demonstrated that RLAIF achieves performance on par with, or even better than, RLHF across three distinct tasks (see Figure 1).
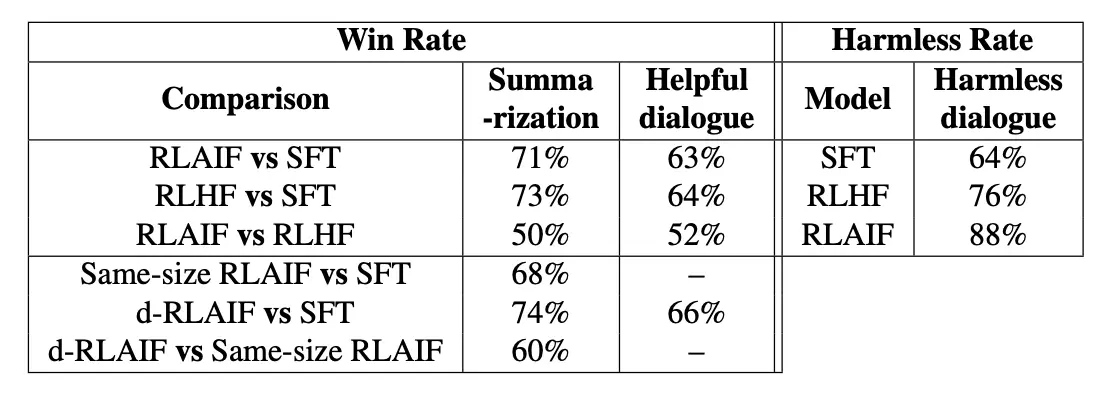
Furthermore, in human evaluations, outputs from RLAIF-trained models were preferred over the baseline Supervised Fine-Tuning (SFT) policy 71% and 73% of the time for summarization, and 63% and 64% of the time for helpful dialogue generation, respectively (see Table 1, Lee et al., 2024).
Figure 1. Comparison of performance across tasks
As detailed in the article, human evaluations further confirm these findings:
Table 1: Human results on summarization, dialogue, and harmlessness.
RLAIF can be found in action across several AI companies as well as modern LLM research methodologies. For example, Anthropic's Constitutional AI framework, trains conversational models using AI-generated critiques and preference rankings instead of human annotations. This allows reinforcement learning from AI feedback to align model behavior with a predefined set of principles (Bai et al., 2022).
Final Remarks
Looking ahead, hybrid approaches are also gaining traction. These methods combine the strengths of both worlds, with humans defining high-level principles or reviewing critical outputs while AI handles the bulk of feedback generation.
In short, the future of AI training likely isn't choosing between human or AI feedback, but strategically combining both. Such models are emerging as a promising path toward building both efficient and responsible AI systems.
As AI models grow increasingly powerful, RLAIF is poised to play a pivotal role in the future of AI development. Its ability to enable faster experimentation, facilitate scalable alignment, and drive more efficient development cycles makes it an indispensable tool.
However, as the technology matures, the industry must carefully navigate the associated challenges of AI alignment, ethical considerations, and safety to ensure these powerful systems are developed responsibly.
FAQ: Understanding RLHF, RLAIF, and the Future of AI Training Work
If companies are moving toward RLAIF (AI feedback), does that mean human data labeling jobs will disappear?
Not at all. While RLAIF automates the feedback loop, humans remain essential for setting the rules, defining principles, and auditing edge cases. The shift is toward hybrid models: humans act as managers, quality controllers, and experts for high-stakes decisions, while AI handles the bulk of repetitive ranking. In short, the demand for human expertise isn't disappearing, it's evolving toward higher-complexity work.
What kind of human work becomes more valuable in an RLAIF world?
Humans are needed to define the "constitution" or principles that guide the AI's feedback. This means tasks like: designing prompt templates, grading nuanced LLM outputs (e.g., creativity, harmlessness), auditing AI-generated feedback for bias, and providing domain-specific expertise (e.g., medical, legal, financial) that a general AI might lack.
The article mentions RLHF is expensive. How does that impact someone looking for work in this field?
It creates a two-tier market. Basic, high-volume labeling is being automated or sent offshore. However, the high cost of RLHF means companies are willing to pay a premium for expert humans who can deliver high-quality feedback efficiently—especially when that feedback is used to train the AI that will eventually replace the low-level work. You can check out REX.Zone to find more about how these experts are connected to premium projects.
What is the most important skill for thriving in this new AI training economy?
Adaptability and critical thinking. Since the tools and techniques (like the shift from RLHF to RLAIF) are evolving rapidly, workers who can quickly learn new guidelines, understand complex domain contexts, and spot errors in both human and AI outputs will be the most successful.
Contact Us– Learn more about how world models and interactive systems are evaluated.
Explore Our Blog – Read research and articles on embodied AI datasets, multimodal alignment, simulation grounded data, and evaluation beyond appearance alone.
Follow Our Updates – Get insights from Abaka AI on real-world robotics research, agent evaluation workflows, and emerging standards for interactive AI systems.
Read Our FAQs – See how teams design datasets and evaluation frameworks for systems that must act, adapt, and remain consistent over time.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.