
Gemma 4 isn’t just another smaller model, it may mark the point where AI finally becomes usable directly on your device. The real shift is not more power, but usable power in the places where it actually matters.
Blogs
2026-04-10/General
Can Gemma 4 Finally Make On-Device AI Work?

Natalia Mendez,Director of Growth Marketing
Why Gemma 4 Could Be the Open Model That Finally Makes On-Device AI Practical
What is Gemma 4?
Gemma 4 is best understood as a family of “open” (open-weights) multimodal language models released on April 2, 2026, positioned explicitly for running on your own hardware rather than exclusively in the cloud. This family spans four sizes, two “edge-first” models and two “workstation-class” models, so that developers can match capability to the memory, compute, and latency envelopes of real devices rather than treating “on-device” as a single uniform target.
A practical mental model is to split Gemma 4 into two tiers.
The “edge tier” (E2B and E4B) is framed around compute and memory efficiency while still providing multimodal inputs and long-context behavior, which are precisely the features that tend to break first when models are forced onto phones and small edge boards. The “workstation tier” (26B A4B and 31B) is framed around bringing higher-reasoning and coding competence into local-first workflows, including the ability to work with very long prompts (Farabet & Lacombe, 2026).
Two design details matter for understanding why Gemma 4 is being discussed as a turning point for on-device AI.
First, the model family is explicitly licensed under Apache 2.0, which shifts it from “interesting to test” to “legally straightforward to ship” in many commercial contexts (Hugging Face, 2026).
Second, the models are not merely “small LLMs.” They are positioned as multimodal and agentic by default, including long context windows (128K for E2B/E4B and 256K for the larger models), and native capabilities oriented toward tool use and structured interaction patterns. It’s not just about chatting with AI on your phone, but about apps that can understand the world, make decisions, and take actions, all while running within the limits of your computer device.
Finally, Gemma 4’s release is embedded in a measurable adoption ecosystem. The release announcement reports more than 400 million Gemma downloads since the first generation and a “Gemmaverse” of more than 100,000 variants, serving as evidence that the distribution channels and developer attention required for real deployment already exist.
In short, Gemma 4 is not a single model; it is an attempt to provide a deployable spectrum of open models whose licensing, modalities, and context lengths align with what on-device products actually need.
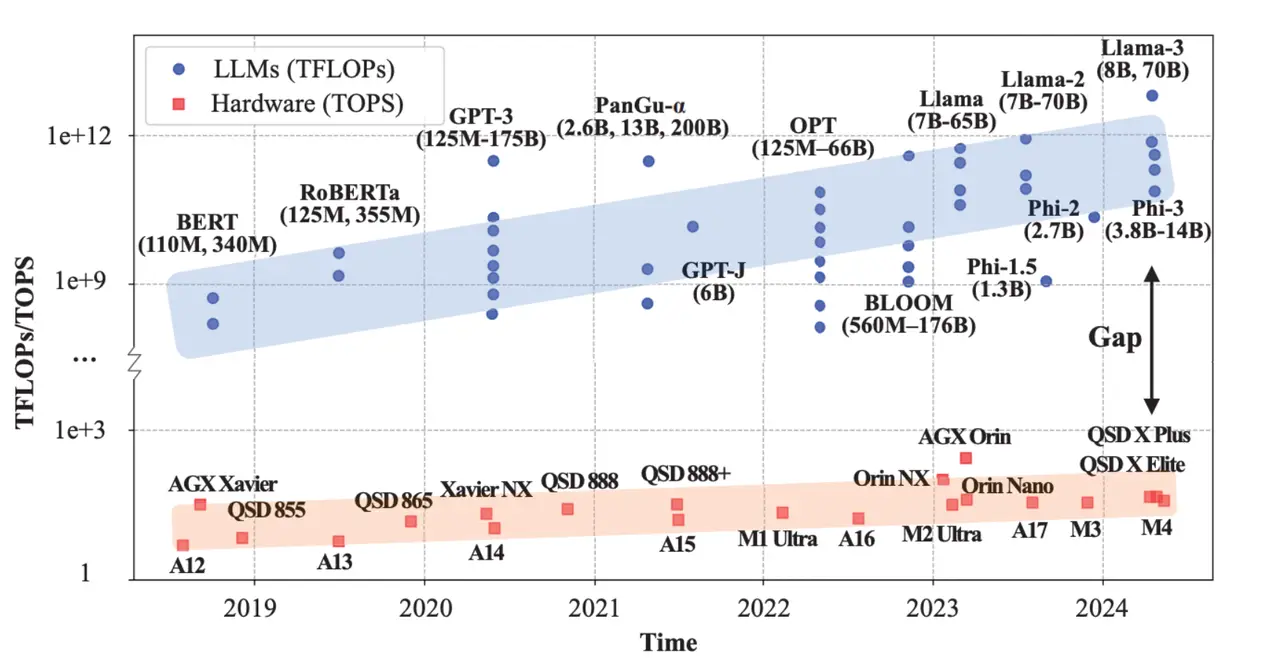
Why has on-device AI been hard?
The appeal of on-device models is straightforward: lower latency, data staying local, and more personalized experiences without constant dependence on network connectivity. Yet reliably delivering those benefits has been difficult because modern language models collide with the physical constraints of edge devices, especially memory capacity, compute throughput, and energy budgets (Xu et al., 2024).
To better understand this, we can frame it as on-device AI as a systems problem rather than a “model quality” problem:
Cloud-first LLM deployment inherits a set of practical weaknesses (latency, security/privacy concerns around sending personal data off-device, and recurring cost) issues that motivate local or hybrid (edge-cloud) deployment (Xu et al., 2024). But edge devices impose hard ceilings: the same review notes that executing extremely large frontier-scale models on smartphones is unfeasible without severe compromises, precisely because compute and energy efficiency collapse under the scale (Xu et al., 2024).
This is why research and production engineering converge on compression and hardware-aware optimizations. The review highlights quantization, pruning, and distillation as central strategies, but it also emphasizes the tradeoff: quantization can reduce memory requirements, yet can impose accuracy costs that may or may not be acceptable depending on the application (Xu et al., 2024). One way to express the tension is:
In short, compression is used when devices cannot hold or run the model as-is, but it fails when the accuracy loss undermines user trust or task success.
In a deployment-focused post, the Google AI Edge Team makes this explicit by defining concrete operating conditions. For example, they describe running the E2B edge model in under 1.5 GB of memory on some devices, using low-bit weights (2-bit and 4-bit) alongside memory-mapped per-layer embeddings (Google AI Edge Team, 2026).
Performance also varies significantly depending on the available hardware. On a CPU-only setup such as a Raspberry Pi 5, they report 133 tokens per second during prefill and 7.6 tokens per second during decoding. With specialized acceleration (such as an NPU on Qualcomm’s Dragonwing IQ8) throughput increases substantially, reaching 3,700 tokens per second for prefill and 31 tokens per second for decoding.
The conceptual lesson is that “on-device AI” is not a single performance regime. It is an interaction between:
Model size and architecture, Precision/quantization choices, Runtime stack quality, And the heterogeneous hardware available on the device.
The key difference between “a model that runs locally” and “practical on-device AI” is not merely whether inference is possible, but whether inference is fast enough, memory-stable enough, and energy-sane enough to be embedded into everyday workflows without the user noticing the cost.
Why Gemma 4 may change that
Gemma 4’s strongest “practicality” argument is that it aims to compress three historically conflicting requirements into one deployable package: a) multimodal perception, b) agentic/task-like behavior, and c) device-grade efficiency.
Start with the practical view. Google presents Gemma 4 as a model that can handle complex tasks such as planning steps, taking actions, generating code offline, and working with images or audio, without needing additional training. In other words, it is designed to be useful immediately after deployment. This matters because on-device applications often cannot afford heavy customization loops: they must ship robust behavior with minimal overhead.
One of the clearest signals in Google’s on-device Agent Skills examples is that Gemma 4 is not being positioned as a model for isolated prompts alone. The examples are concrete and product-oriented: querying Wikipedia through a skill, generating summaries, flashcards, and visualizations from user data such as sleep and mood trends derived from speech input, and powering end-to-end conversational experiences like an app that describes and plays animal vocalizations (Google AI Edge Team, 2026).
Taken together, these examples point to a broader shift in how on-device AI is being imagined. The model is no longer framed as a single-turn utility that produces a one-off answer, but as a workflow substrate that can call tools, structure outputs, and operate as part of a larger application.
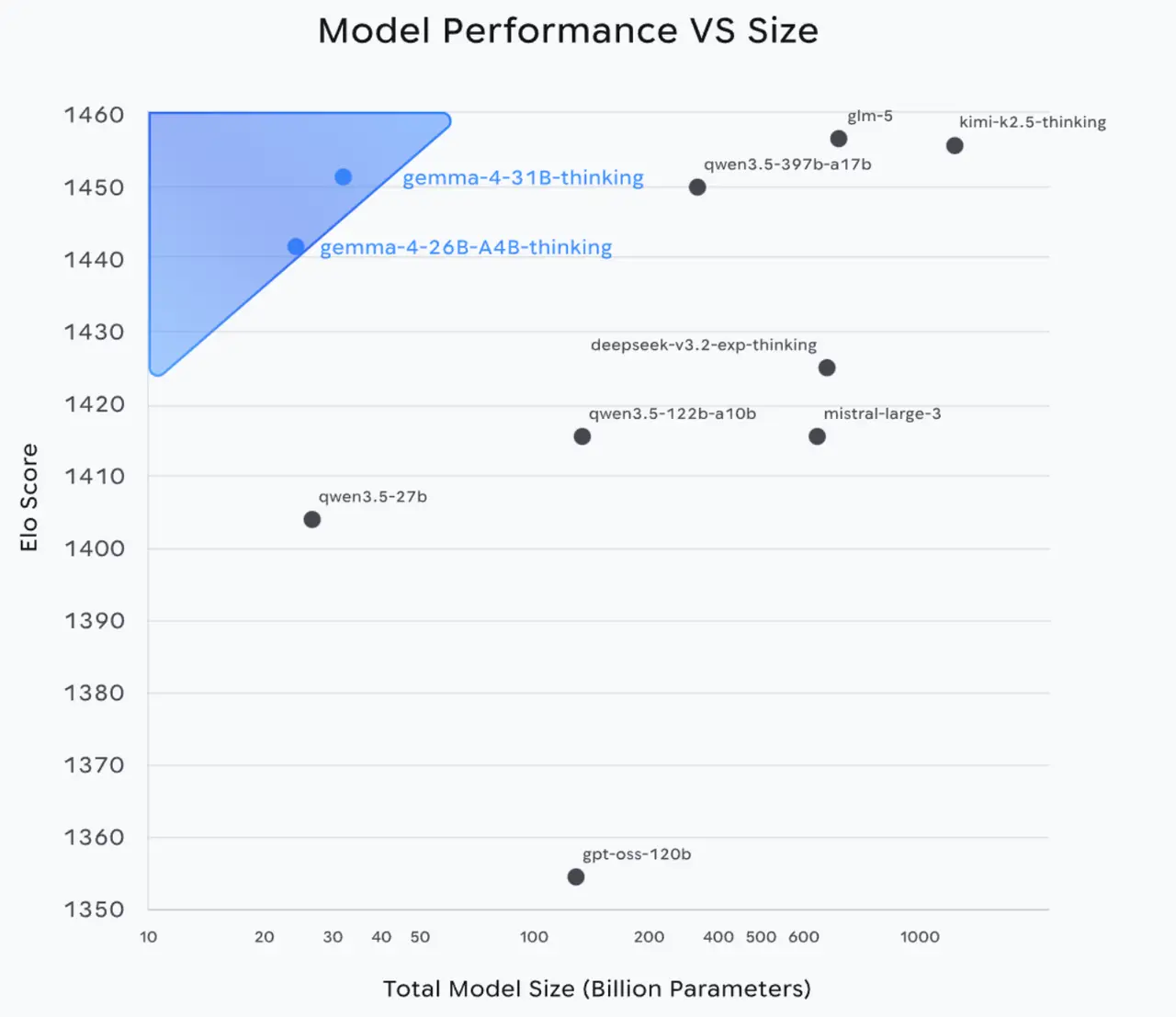
That practical story becomes more compelling when paired with the technical one. Here, the Hugging Face release note makes two important claims that help explain why Gemma 4 is being discussed as a meaningful step forward for on-device AI.
The first is architectural. Hugging Face describes Gemma 4 as compatible with long-context use while also being “ideal for quantization,” which, in edge deployment terms, is another way of saying that the model is designed with real engineering constraints in mind. This matters because long context is usually expensive: the more information a model needs to keep in play, the greater the burden on memory and computation. According to the release write-up, Gemma 4 addresses that tension through a series of efficiency-oriented design choices, including alternating local sliding-window attention with periodic global attention, dual RoPE configurations for long-context support, and a shared KV cache mechanism that reduces redundant computation and lowers memory use during inference (Hugging Face, 2026). The point is not simply that these mechanisms sound sophisticated. The point is that they aim to preserve long-range reasoning capacity without incurring the full computational cost of applying global attention everywhere.
The second claim is about deployment. Deployability is presented as a first-class feature rather than a downstream concern, noting that Gemma 4 launched with day-0 support across multiple open inference engines and with ONNX checkpoints that allow it to run across a range of hardware backends, including edge devices and browsers. This is more consequential than it may seem at first glance. In practice, the line between a strong research model and a usable product model is often determined less by raw capability than by how easily developers can integrate it into real systems. A model does not become practical simply because it performs well; it becomes practical when it can be deployed, adapted, and maintained with reasonable effort.
Once these two threads are considered together, the broader argument comes into focus. On one side, there is a deployment stack built around explicit memory and throughput targets, including configurations that can operate under 1.5 GB of memory and benchmarked token-per-second performance. On the other, there is an architecture explicitly described as both quantization-friendly and long-context capable. Seen together, these are not isolated advantages. They suggest a more coherent strategy for local AI.
In short, Gemma 4’s real wager is that on-device AI becomes practical not when a cloud-oriented model is compressed after the fact, but when the model, the runtime, and the surrounding ecosystem are designed in concert from the outset.
Challenges That Define the Opportunity
If Gemma 4 represents a meaningful step toward practical on-device AI, it also highlights the set of constraints that continue to shape the field. These are best understood not simply as limitations, but as the core engineering challenges that current model design is actively addressing: a) the physical and algorithmic constraints of edge deployment, and b) the ecosystem factors that determine whether open models can reliably reach production.
On the physical side, the on-device literature is clear: edge environments are inherently constrained by compute, memory, and energy budgets, which is why the field has consistently focused on compression and hardware-aware design (Xu et al., 2024). Techniques such as quantization play a central role in this effort. By reducing numerical precision, models can operate within tight memory limits, enabling deployment on devices that would otherwise be infeasible. At the same time, this introduces a well-known tradeoff. Lower precision can affect accuracy, meaning that a model may be “small enough to run,” yet not always “reliable enough to trust,” particularly in high-stakes applications.
However, this tension is precisely where recent progress becomes meaningful. The goal is no longer simply to shrink models, but to design architectures (like those in Gemma 4) that maintain useful performance under these constraints. In this sense, the accuracy-efficiency tradeoff is a central axis along which innovation is currently happening.
A similar reframing applies to deployment strategies. While fully local AI is often presented as the ideal, user demand increasingly points toward hybrid edge-cloud systems. Survey results cited in the literature show a preference for edge-cloud collaboration over purely cloud-based approaches, driven by concerns around latency, data privacy, and cost. This suggests that “practical” AI is not defined by strict locality, but by balance.
The key difference between “cloud-only” and “practical” is not where the model runs, but whether the system meets latency, privacy, and cost expectations in real-world conditions.
On the ecosystem side, the Interconnects analysis reinforces an equally important point: the success of open models is not determined by benchmark performance alone. Lambert (2026) argues that factors such as licensing, tooling readiness, and fine-tunability play a decisive role in adoption, and that these elements often take time to stabilize after a release. This is especially relevant for on-device AI, where deployment depends heavily on inference engines, quantization pipelines, and mobile runtimes working reliably together.
From this perspective, Gemma 4’s emphasis on deployability (its compatibility with multiple runtimes, its quantization-friendly design, and its early ecosystem support), can be seen as a direct response to these historical bottlenecks. The challenge is no longer just to build better models, but to ensure that they can be integrated into real systems with minimal friction.
Lambert (2026) also highlights a broader business reality: legal clarity and tooling stability are critical for adoption at scale. If a model is difficult to approve internally or cumbersome to deploy, even strong technical performance may not translate into usage. This reinforces a key insight for on-device AI: progress is measured not only in model capability, but in how smoothly that capability translates into products.
In short, Gemma 4 does not eliminate the challenges of on-device AI, it clarifies them and, in many cases, addresses them more directly than previous approaches. The remaining constraints are the same ones that have historically shaped edge deployment (accuracy versus efficiency, hardware-aware optimization, and ecosystem maturity), but they are increasingly being treated as design inputs rather than afterthoughts. That shift, more than any single benchmark, is what makes on-device AI feel closer to practical reality.
FAQ
Does Gemma 4 mean AI will run entirely on devices without the cloud?
Not necessarily. While Gemma 4 makes local execution more feasible, most real-world systems will likely remain hybrid. Devices can handle fast, private, or lightweight tasks locally, while more complex or large-scale processing may still rely on the cloud. The practical shift is not toward eliminating the cloud, but toward reducing dependence on it when it is unnecessary.
What kinds of applications benefit most from on-device AI like Gemma 4?
Applications that require low latency, privacy, or continuous interaction tend to benefit the most. This includes personal assistants, real-time translation, local search over private data, and multimodal interfaces that process voice or images directly on the device. The advantage is less about raw intelligence and more about responsiveness and control over data.
Why is “deployability” such a critical factor compared to model performance?
In practice, a model’s usefulness depends on how easily it can be integrated into real systems. Even a highly capable model can fail to gain adoption if it is difficult to run, optimize, or adapt across different hardware environments. Deployability determines whether developers can move from experimentation to production quickly, which is often more important than marginal improvements in benchmark performance.
What should developers think about the tradeoff between efficiency and accuracy on-device?
The key is to align model performance with the requirements of the task. Not all applications need maximum accuracy, but some (such as medical or financial use cases) cannot tolerate degradation. Developers must decide where reduced precision is acceptable in exchange for faster, cheaper, or more private execution, and where it is not.
Related topics
How AI Image Models Work: From Pixels to Intelligence
Why Training Methods Matter More Than Model Size
Beyond the Attention Bottleneck: How CAD Boosts Long-Context LLM Training Efficiency by 1.35x
LoopLLM: How Ouro Builds Reasoning Into Pre-training
LLM Data Cost Breakdown: All You Need to Know About Data Costs for Training an LLM
Is your LLM spouting nonsense? The RLHF tool which revives 100 AI is here!
Synthetic Data for LLM Training and Fine-Tuning: The Complete Guide
More about Abaka AI
Contact Us– Learn more about how world models and interactive systems are evaluated.
Explore Our Blog – Read research and articles on embodied AI datasets, multimodal alignment, simulation grounded data, and evaluation beyond appearance alone.
Follow Our Updates – Get insights from Abaka AI on real-world robotics research, agent evaluation workflows, and emerging standards for interactive AI systems.
Read Our FAQs – See how teams design datasets and evaluation frameworks for systems that must act, adapt, and remain consistent over time.
Sources
https://blog.google/innovation-and-ai/technology/developers-tools/gemma-4/
On-Device Language Models: A Comprehensive Review, https://arxiv.org/html/2409.00088v2
Bring state-of-the-art agentic skills to the edge with Gemma 4 - Google Developers Blog
https://developers.googleblog.com/bring-state-of-the-art-agentic-skills-to-the-edge-with-gemma-4/
Welcome Gemma 4: Frontier multimodal intelligence on device
https://huggingface.co/blog/gemma4
Gemma 4 and what makes an open model succeed
https://www.interconnects.ai/p/gemma-4-and-what-makes-an-open-model
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.