
This article explains what outsourcing data processing really means in AI, OCR, and multimodal workflows. It shows why companies outsource beyond cost, where things usually go wrong, and how better workflow design improves both quality and efficiency. It also gives a clear way to evaluate vendors based on how they actually produce and manage data, andnot just what they promise.
Blogs
2026-03-27/General
Outsourcing Data Processing Services: A Guide for AI, OCR, and Multimodal Workflows

Natalia Mendez,Director of Growth Marketing
Outsourcing Data Processing Services: A Guide for AI, OCR, and Multimodal Workflows

Outsourcing data processing is best understood as a production system for trustworthy data. The output is not simply “data” in the abstract. It is data that has been structured, verified, and made usable inside automated systems, whether those systems are classic business pipelines such as ETL, dashboards, and audit trails, or modern AI systems used for training, evaluation, retrieval, and decision support.
What does outsourcing data processing actually mean?
In business conversations, people often blur the line between data entry and data processing, but they are not the same thing.
Data entry is the conversion of information from one format into another. A paper form turned into a spreadsheet, or a scanned image turned into CRM fields, are basic examples. It is, in essence, the digitization of raw facts.
Data processing goes further. It takes those raw inputs and turns them into something usable by cleaning, organizing, validating, and sometimes analyzing them so they can support decisions.
When companies outsource “data processing services,” they are usually outsourcing a bundle of activities rather than a single task. That bundle may include digitization, normalization, deduplication, validation, exception handling, and, in some cases, annotation or labeling for machine learning.
An increasingly common model is hybrid data processing, where automation handles the first pass and humans intervene where uncertainty remains, understood as a “mix of human and AI-powered systems” (Hopestone, 2025), including OCR for scanned documents and AI-based validation paired with human oversight.
From the AI side, the same idea appears in more technical language. If data are “messy, uncategorized, biased, or incomplete” (Anolytics, 2026), downstream models will not learn reliably.
Why do companies outsource this work?
The most obvious reason is scale. As businesses grow, the volume of operational data, from forms and invoices to customer records and documents, becomes too time-consuming and resource-intensive to manage well in-house.
But serious outsourcing decisions are rarely explained by cost alone. A more realistic framing is that companies outsource when internal handling becomes a source of operational friction and governance risk. In practice, real pressures usually involve quality, speed, security, and accountability.
A vendor may increase speed, but it can also introduce risk if the workflow is poorly governed. iTech, for example, warns that hiring the wrong organization can create mistakes or security issues, especially when large amounts of client or company data are involved (iTech Data Services, n.d.).
The strongest evidence that outsourcing can reshape both cost and quality comes from controlled comparisons of annotation providers. In a large-scale study of outsourced image annotation, Rädsch et al. (2024) compared four annotation companies with Amazon Mechanical Turk using the same image tasks. Their findings are striking. MTurk produced around 20% “spam” annotations, while the annotation companies produced none. The annotation companies were also 61.1% cheaper in median cost, even though they used internal QA workers, with total costs ranging from 24.5% to 81.5% of MTurk costs. They additionally reported a twofold improvement in the proportion of images without severe errors.
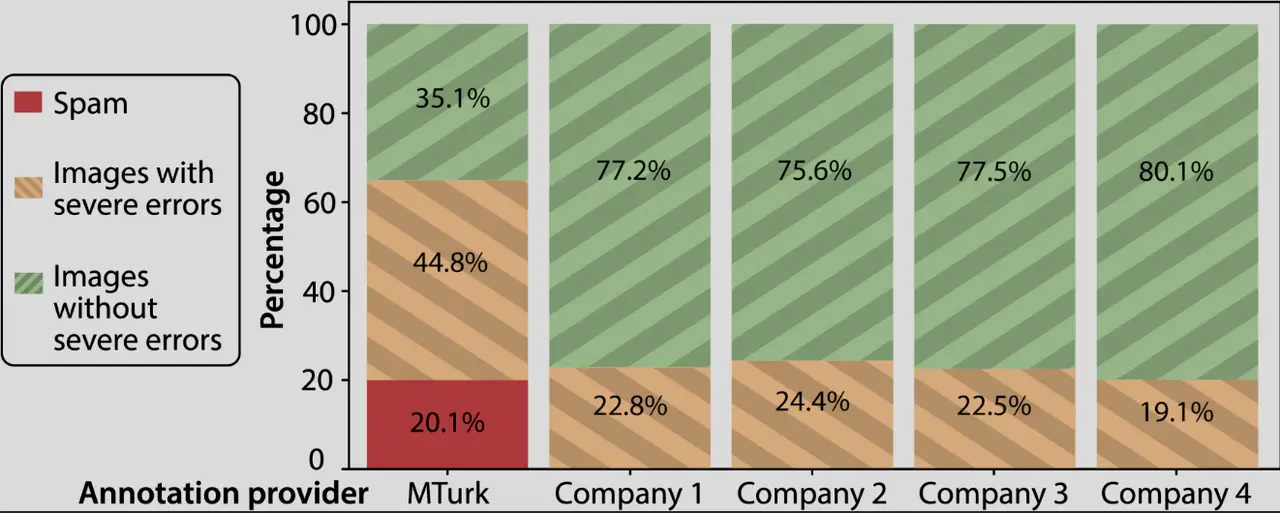
For an industry audience, this changes the framing of the outsourcing question. The real issue is not simply “cheap labor versus expensive labor.” It is the production system that turns budget into reliable ground truth.
In short: companies outsource because internal handling becomes a bottleneck and a risk surface; outsourcing is attractive when it improves throughput, security posture, and error economics, not just headcount costs.
Where is outsourcing more useful: in AI, OCR, and multimodal workflows?
Outsourced data processing appears across many industries, but in practice it tends to cluster around three major workflow families: AI labeling, OCR and document processing, and multimodal pipelines.
AI workflows
In computer vision and medical imaging, outsourcing often means paying for high quality reference annotations that make benchmarking and model validation meaningful. Rädsch et al. (2024) worked with 57,648 instance segmentation masks across 4,050 unique frames, treating annotation quality not as a secondary issue but as a foundation for real-world image analysis.
In language and semantic workflows, a common model is assisted annotation, where a model proposes labels and humans confirm or correct them. Bonet-Jover et al. (2023) provides a useful example. Using a human-in-the-loop methodology, they reported an approximately 64% reduction in annotation time compared with fully manual annotation, while also achieving 95% accuracy and 95% F1 when training a model on the resulting dataset.
This is an important point for industry readers: in AI workflows, outsourcing is often not about replacing expertise. It is about organizing expertise efficiently so that models can learn from dependable examples.
OCR workflows
OCR outsourcing usually begins with document digitization, such as scans, PDFs, or photos, and ends with structured outputs like extracted fields, tables, and normalized values.
But more often than not, OCR is strong in document processing and automation, but weak when dealing with low quality images and complex layouts. That limitation is one reason human validation remains economically necessary, and why OCR work is so often outsourced in combination with review and correction processes.
Their review also provides useful quantitative anchors. Across the sources and sector case studies they synthesize, they report printed text accuracy in the range of 98% to 99.5%, and exact match rates of 95% to 99% on key fields. These figures are not guarantees for every workflow, but they do clarify why OCR performs well in production when inputs are clean and the scope is controlled.
The key distinction here is simple: OCR is powerful when the task is structured, but it becomes fragile when documents are noisy, irregular, or visually complex.
Multimodal workflows
Multimodal workflows arise when a single record combines multiple channels, such as text and images, video and audio, or several sensor streams at once.
A practical way to understand multimodal outsourcing is this: you are outsourcing the labor of making different modalities comparable. That includes alignment, labeling, synchronization, and preprocessing so that the data can be used in a unified downstream system.
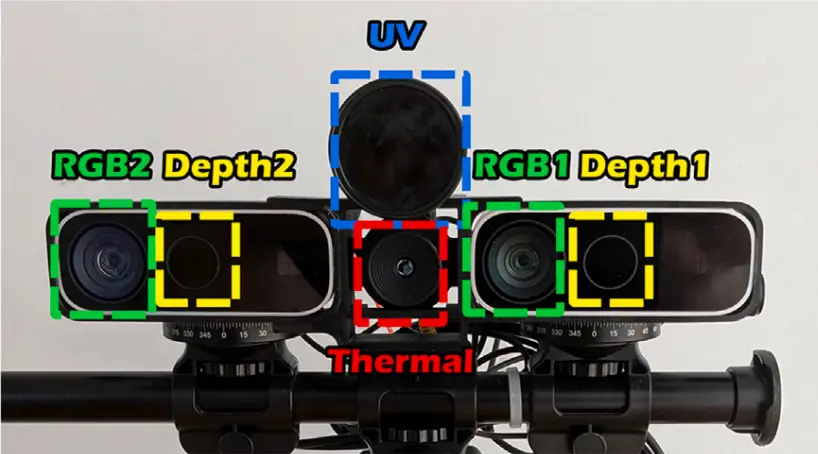
Brenner et al. (2026) offers a concrete example through a multimodal dataset case involving modality diversity and annotation strategy. They report preprocessing gains that improved downstream segmentation performance, with mean IoU rising from 70.66% to 76.33% for depth data, and from 72.67% to 79.08% for thermal encoding.
That matters because multimodal data problems are rarely about one file being “wrong.” They are usually about several data streams failing to align in a way that the model can actually use.
In short: AI outsourcing buys ground truth, OCR outsourcing buys structure, and multimodal outsourcing buys alignment. The difference is not the file type. It is the dominant failure mode. In AI, the main issue is label noise. In OCR, it is layout and scan noise. In multimodal systems, it is cross-modal alignment noise.
Common problems in outsourced data workflows
The failure modes in outsourced data processing are surprisingly consistent across industries. They usually have less to do with “bad workers” and more to do with bad system design: unclear specifications, weak measurement, and poorly placed quality control.
Quality failures
Rädsch et al. (2024) provide unusually concrete evidence that vendor choice changes the risk profile. In their comparison, MTurk contained around 20% spam, while annotation companies produced none, and the annotation companies were still 61.1% cheaper in median cost. This is useful because it shows that “outsourcing” is not a single category. The provider model matters.

Their second finding is even more practical. Internal vendor QA often produced only marginal improvements, while improved labeling instructions could substantially raise performance. They made this measurable by testing instruction sets of 168 words, 446 words, and 961 words, moving from minimal instructions to extended instructions and then to extended instructions with pictures.
That is a valuable lesson for any buyer: quality is often shaped earlier in the process than people assume. Better instructions can matter more than more review.
OCR failures
One of OCR’s oldest limitations is that it struggles with low quality images and complex layouts. That is precisely why human correction is still needed so often. For non-technical readers, this is an important conceptual point: OCR is not understood. It is extracted under visual and structural constraints. When those constraints worsen, performance drops.
Dataset failures
In OCR training and multilingual settings, dataset construction is not a clerical task. It is a design problem. Biró et al. (2023) describe the requirements of an “optimal” OCR training dataset in terms of balanced datasets, contextual understanding, robustness to noise, and scalability. They also show why multilingual OCR becomes expensive very quickly. Vocabulary size may range from 5,000 to 6,500 characters in a constrained IT domain, but in healthcare it may exceed 10,000 characters.
This illustrates a broader point: the complexity of the dataset depends on the domain, and many outsourcing failures happen because buyers underestimate that complexity.
Contract failures
On the operational side, iTech describes a common breakdown: if the statement of work is vague, the vendor may exclude fields the client assumed were included. The result is a deliverable that represents only “a fraction” of what was expected, leading to delays, rework, and conflict (iTech Data Services, n.d.).
The most expensive failures, then, are not isolated OCR mistakes or isolated annotation errors. They are mismatches between specification, measurement, and accountability, especially when QA is treated as a cosmetic add-on instead of part of the production design.
How does outsourcing help when it is designed properly?
Outsourcing works best when it is treated as workflow engineering, not simple delegation. You are not just buying labor hours. You are buying a repeatable pipeline with measurable outputs.
Quality and cost can move together
Rädsch et al. (2024) show that higher quality does not automatically require higher cost. Their annotation companies were 61.1% cheaper in median cost than MTurk and produced no spam, compared with MTurk’s approximately 20% spam rate. In business terms, that suggests outsourcing can improve ROI when vendor processes reduce rework and lower severe error rates.
The importance of human-in-the-loop
Bonet-Jover et al. (2023) show why human-in-the-loop systems are attractive in practice. Their method reduced annotation time by nearly 64%, while the resulting dataset supported 95% accuracy and 95% F1 in a trained model. This demonstrates how outsourcing can move labor away from full manual labeling and toward targeted review.
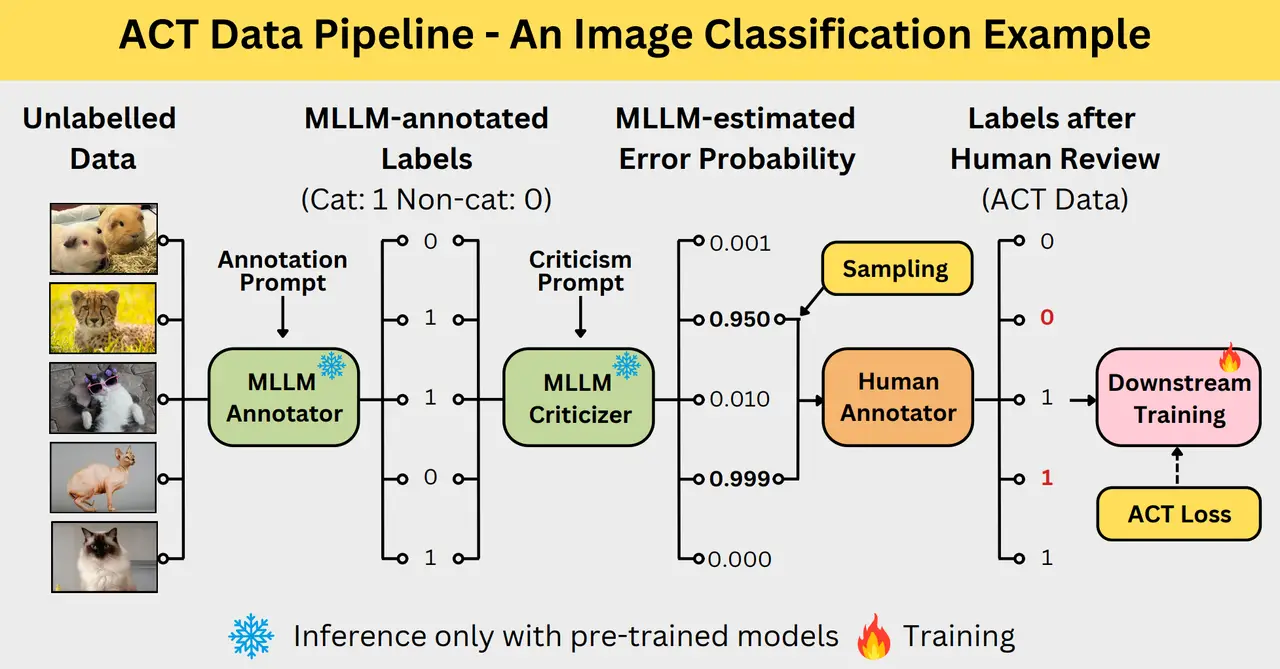
A more advanced version of the same idea appears in Lin et al. (2025), where the ACT pipeline combines a machine annotator, a machine critic, and human correction. They report that the performance gap relative to fully human-annotated data can be reduced to less than 2% on most benchmark datasets, while saving up to 90% of human costs.
A more advanced approach focuses human review only on uncertain cases, improving both efficiency and data quality, improving efficiency and data quality.
What about internal responsibility?
Outsourcing does not remove internal responsibility. iTech makes a practical point here: even when machine learning systems improve over time, quality monitoring is still necessary because “no algorithm can get it 100% right 100% of the time” (iTech Data Services, n.d.). Their recommendation is straightforward: organizations should run periodic evaluations and spot checks together with the outsourcing partner.
This is one of the most important operational truths in space. Outsourcing does not remove responsibility. It changes how responsibility is exercised. The clearest way to put it is that outsourcing helps most when it turns a fully manual workflow into a human-in-the-loop control system, where automation handles scale, humans handle ambiguity, and quality is monitored continuously rather than assumed.
In short: outsourcing helps most when it converts a fully manual pipeline into a human-in-the-loop control system, where automation handles volume, humans handle uncertainty, and quality is monitored continuously rather than assumed.
What should you look for when choosing an outsourcing partner?
Choosing a vendor is ultimately a decision about measurement, governance, and process realism. One useful way to think about it is as if you were designing an experiment: define the inputs, define the outputs, define the error metrics, and define what happens when things go wrong.
Is the scope defined precisely enough?
The iTech outsourcing guide explains that a poorly defined statement of work can lead to omitted fields, delays, and cost disputes, even when the vendor appears to deliver on schedule (iTech Data Services, n.d.).
A practical rule follows from this: if you cannot clearly define the exceptions, such as what to do when a document is unreadable, a label is ambiguous, or a table is misaligned, you are probably not ready to outsource. Outsourcing works best when the scope includes not only the normal case, but also the messy case.
Are security and compliance built into the workflow?
iTech also emphasizes that security should be treated as a core selection criterion, especially when large volumes of data are involved. The issue is simple: the moment you share data externally, you introduce risk. A weak provider can expose sensitive information or create vulnerabilities that are difficult to control.
In a related article, they go further by stressing the need for multiple layers of security. This becomes especially important when the data includes personal or sensitive information, where one weak point can compromise the entire process. Their broader message is clear: security should not be treated as an add-on. It should be built into the outsourcing model from the start.
Should you trust QA claims at face value?
Not without looking at how quality is actually produced. Internal QA alone may generate only marginal improvements, while better labeling instructions can create major gains. For vendor evaluation, that translates into a very practical question: do not just ask for the QA checklist. Ask to see the instruction design itself, including examples, edge cases, and visual cues.
You should also ask how the vendor measures spam, severe errors, and consistency, because those metrics are much more predictive of downstream model reliability than generic promises about “high accuracy.”
Can the vendor think at the dataset level?
For OCR and multilingual or multimodal workflows, dataset preparation is often constrained by issues such as balance, metadata-aware quality control, robustness, and domain-specific complexity.
A vendor that cannot discuss those tradeoffs is probably operating at the level of data entry rather than AI-ready data production.
Final remarks
When thinking about outsourcing data processing, the most effective workflows are often the ones that treat outsourced data work as a designed system: one with clear specifications, measurable outputs, explicit exception handling, and continuous quality review. In that sense, the real strategic question is not “Should we outsource?” but rather “Which parts of our data workflow require external scale, and under what control model?”
At the same time, this field rewards nuance. The strongest organizations are usually the ones that understand that outsourcing can amplify confusion if the work is poorly scoped or weakly governed; thus they outsource execution but not responsibility. For AI, OCR, and multimodal systems alike, the long-term advantage comes from building data pipelines that are not only faster, but more reliable, more interpretable, and more resilient under real-world conditions.
FAQ
1. When does outsourcing data processing become necessary rather than optional?
Outsourcing typically becomes necessary when data volume grows faster than a company’s ability to maintain consistency and quality internally. For example, in imaging AI, annotation tasks can scale to tens of thousands of labeled instances, requiring coordinated workflows and specialized labor . At that point, the challenge is no longer just processing data, but maintaining standardization across teams, formats, and edge cases. Companies often realize that internal teams struggle not because of lack of skill, but because scaling structured processes (such as labeling guidelines or validation loops) is operationally complex. Outsourcing becomes less about cost and more about maintaining reliability under scale.
2. Can small companies benefit from outsourcing, or is it only for large enterprises?
Small and mid-sized companies often benefit even more from outsourcing, particularly when working with OCR or AI pipelines that require upfront dataset preparation. For instance, building high-quality OCR datasets requires handling variability in fonts, layouts, and languages, which demands both technical expertise and structured workflows . Instead of investing heavily in infrastructure and hiring specialized teams early, smaller companies can use outsourcing as a way to access capabilities on demand. This allows them to validate products faster without committing to long-term internal scaling before product-market fit is clear.
3. How do you know if outsourced data quality is actually good enough?
Evaluating outsourced data quality requires looking beyond surface metrics like accuracy percentages. While OCR systems, for example, can reach up to 98–99.5% accuracy on structured text , real-world performance depends heavily on edge cases—such as noisy images, ambiguous labels, or rare scenarios. A more reliable approach is to assess how well the data holds up under downstream tasks, such as model performance or error consistency. In practice, the key signal is not whether errors exist, but whether they are systematic and explainable. If errors are random, the dataset is usually robust; if they cluster around specific cases, the process likely needs refinement.
4. What is the biggest hidden risk when outsourcing data processing?
One of the biggest hidden risks is not technical failure, but misalignment between instructions and execution. Research shows that improving labeling instructions can sometimes have a greater impact on data quality than adding more quality assurance layers . This means that even highly capable external teams can produce suboptimal results if the problem definition is unclear. In practice, outsourcing shifts responsibility from “doing the work” to “defining the work correctly.” Companies that underestimate this often experience inconsistent outputs, even when working with experienced providers.
Related Topics
How to Outsource Data Processing: Cost, Risks & Best Practices
Top Data Processing Outsourcing Companies in 2025
Best Multimodal Data Annotation Platforms in 2026: A Practical Comparison
2026’s Essential Multimodal Datasets for Embodied AI
The Future of Multimodal AI Benchmarks: Evaluating Agents Beyond Text
DeepSeek-OCR 2: Mastering Visual Causal Flow on OmniDocBench
More about Abaka AI
Contact Us– Learn more about how world models and interactive systems are evaluated.
Explore Our Blog – Read research and articles on embodied AI datasets, multimodal alignment, simulation grounded data, and evaluation beyond appearance alone.
Follow Our Updates– Get insights from Abaka AI on real-world robotics research, agent evaluation workflows, and emerging standards for interactive AI systems.
Read Our FAQs – See how teams design datasets and evaluation frameworks for systems that must act, adapt, and remain consistent over time.
Sources
Significance of Data Processing Services for an AI-Driven World | IoT For All
https://www.iotforall.com/ai-data-processing-importance
Quality Assured: Rethinking Annotation Strategies in Imaging AI
https://arxiv.org/html/2407.17596v2
What Is Data Entry Outsourcing and How Does It Work in 2025?
https://www.hopestoneadvisory.com/what-is-data-entry-outsourcing-and-how-does-it-work-in-2025/
Data Processing Vs. Data Entry: Know The Difference
https://rannsolve.com/blog/data-processing-vs-data-entry-know-the-difference/
Data Capture Outsourcing: 3 Tips to Help Ensure Success
https://itechdata.ai/data-capture-outsourcing-3-tips-to-help-ensure-success/
7 Tips for Outsourcing Your Data Capture Project
https://itechdata.ai/7-tips-for-outsourcing-your-data-capture-project/
Applying Human-in-the-Loop to construct a dataset for determining content reliability to combat fake news - ScienceDirect
https://www.sciencedirect.com/science/article/pii/S0952197623013362
(PDF) Leveraging OCR and AI Tools: A Comparative Guide to Enhancing Data Processing and Decision-Making Efficiency in the Digital Age
MM5: Multimodal image capture and dataset generation for RGB, depth, thermal, UV, and NIR - ScienceDirect
https://www.sciencedirect.com/science/article/pii/S1566253525005883
Optimal Training Dataset Preparation for AI-Supported Multilanguage Real-Time OCRs Using Visual Methods
https://www.mdpi.com/2076-3417/13/24/13107
ACT as Human: Multimodal Large Language Model Data Annotation with Critical Thinking
https://advanced-benchmark.sg.larksuite.com/sync/E8Gbdlr45sYjw9brDiOlOTuygEG
A Guide to Implementing Machine Learning for Data Capture
https://itechdata.ai/machine-learning-for-data-capture/
How to Evaluate a Data Entry Company Before Outsourcing
https://itechdata.ai/how-to-evaluate-a-data-entry-company-before-outsourcing/
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.