DeepSeek-OCR 2: Mastering Visual Causal Flow on OmniDocBench
Yuna Huang,Marketing Curator
DeepSeek-OCR 2 revolutionizes document parsing by replacing rigid raster-scanning with a human-like "Visual Causal Flow" mechanism. Validated on OmniDocBench v1.5 (a benchmark co-developed by Abaka AI), this new architecture reduced reading order errors by 33% and achieved a 91.09% accuracy rate, proving that semantic reordering is the key to genuine 2D document reasoning.
Why DeepSeek-OCR 2 Chooses OmniDocBench: A New Era of Visual Causal Flow
The release of DeepSeek-OCR 2 marks a fundamental shift in how Vision-Language Models (VLMs) "see." Moving away from rigid raster-scanning, DeepSeek-AI has introduced DeepEncoder V2, an architecture that mimics human foveal fixation.
As a core contributor to 2077AI, Abaka AI is proud to see our benchmark, OmniDocBench, serve as the primary validation ground for this breakthrough.
The Innovation: From Raster-Scan to Causal Flow
Traditional VLMs process images from top-left to bottom-right, regardless of content. This fails on complex layouts like newspapers or academic journals. DeepSeek-OCR 2 solves this via:
LLM-Style Vision Encoder: Replacing CLIP with Qwen2-based architecture.
Causal Flow Tokens: Learnable queries that reorder visual tokens based on semantic importance.
DeepSeek-AI selected OmniDocBench because it provides the most diverse "stress test" for document parsing. The results on v1.5 prove the power of visual causal flow:
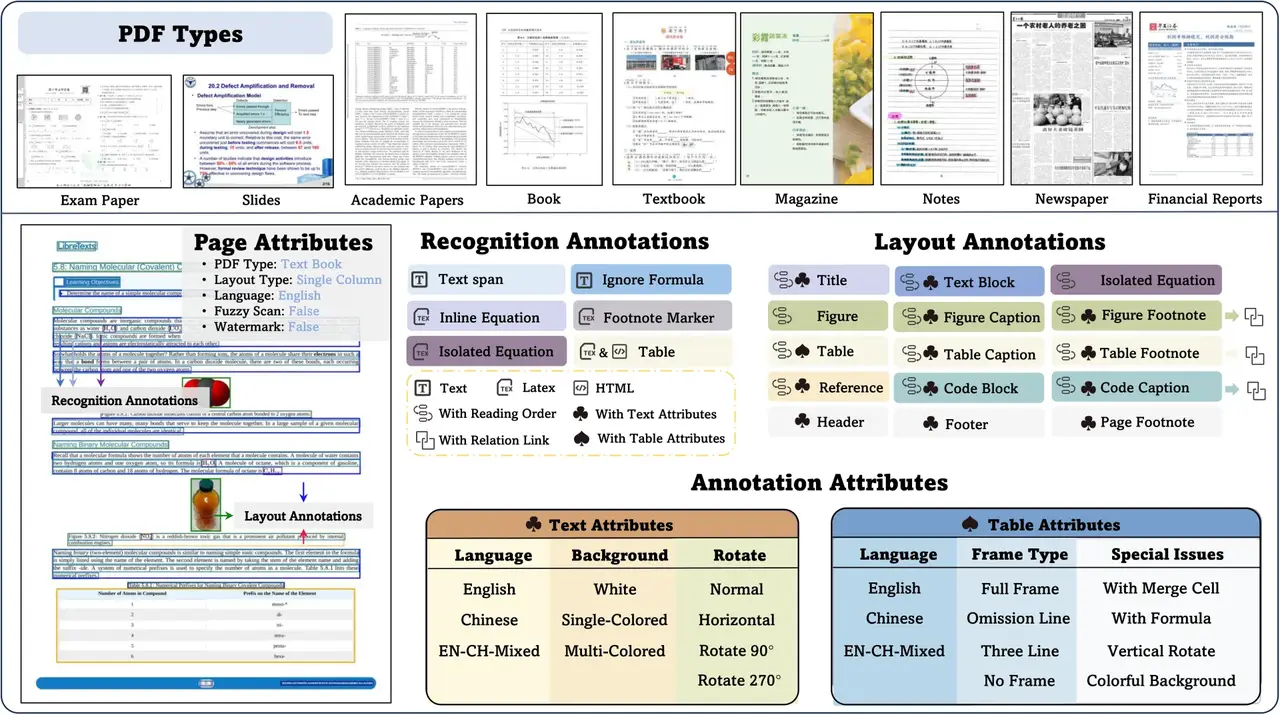
OmniDocBench Overview
The key difference between DeepSeek-OCR 2 and its predecessor is not just the parameter count, but the ability to "reason" about the reading order before generating text.
Real-World Impact: Production Readiness
In live production environments, DeepSeek-OCR 2 reduced the "repetition rate" (a key failure metric for OCR) by 2.08% for online user logs and 0.81% for large-scale PDF pretraining data. This makes it a formidable tool for enterprises building proprietary RAG (Retrieval-Augmented Generation) pipelines.
Conclusion: Toward Native Multimodality
DeepSeek-OCR 2 demonstrates that the "LLM-style encoder" is the future. By using shared attention mechanisms for both vision and text, we are moving toward a unified omni-modal architecture.
FAQ
What is OmniDocBench?
OmniDocBench is a multi-source document parsing benchmark developed by 2077AI that evaluates AI on 9 document types, including academic papers, newspapers, and notes.
How does "Visual Causal Flow" improve OCR accuracy?
By allowing the model to determine the most logical sequence of visual information (e.g., following a column in a newspaper) before processing it as text, it drastically reduces reading order errors.
Can DeepSeek-OCR 2 handle handwritten notes or formulas?
Yes. In OmniDocBench testing, it achieved a 90.31% score in formula recognition, outperforming many proprietary models with a significantly lower visual token budget.