The Future of Multimodal AI Benchmarks: Evaluating Agents Beyond Text
AI is moving beyond text into multimodal, agentic capabilities, requiring benchmarks that test perception, reasoning, and interactive capabilities. 
The Future of Multimodal AI Benchmarks: Evaluating Agents Beyond Text
The Shift Toward Multimodal Intelligence
Artificial intelligence is undergoing a profound transformation. Once defined by text-based models capable of generating language or summarizing information, today’s systems are expanding into multimodal intelligence — the ability to process text, images, audio, video, and environmental data simultaneously.
This shift enables the rise of AI agents that can perceive, reason, and act — interpreting visual scenes, responding to spoken input, or even controlling digital and physical environments. From autonomous robots to intelligent assistants and simulation agents, these systems represent a more complete form of intelligence.
But one question drives the field forward: how do we measure their performance?
Why Text-Only Benchmarks Fall Short — and How Multimodal Ones Are Rising
For several years, AI benchmarks such as SQuAD, GLUE, and SuperGLUE set the standard for evaluating natural language understanding. These datasets helped researchers measure accuracy, reasoning, and generalization in text-based tasks — but they only captured onedimension of intelligence.
As AI expands into perception, embodiment, and interaction, text-only benchmarks no longer tell the full story. They fail to evaluate:
Visual reasoning — interpreting images, diagrams, or spatial layouts
Temporal and sensory understanding — reasoning across video or real-time input
Action and interaction — taking steps, using tools, navigating interfaces
Multi-agent strategy — coordination, communication, and adaptation in dynamic environments
To address these gaps, next-generation multimodal AI benchmarks have emerged, combining academic and industry-led innovations.
Innovative Benchmarks from Research Labs
Agent-X (2025) – Vision-centric, multi-step reasoning and tool use in dynamic visual scenes
VS-Bench (2025) – Strategic reasoning in multi-agent, multimodal environments
VisualWebArena (2024) – Web navigation and perception across text, image, and layout inputs
Innovative Benchmarks from 2077AI
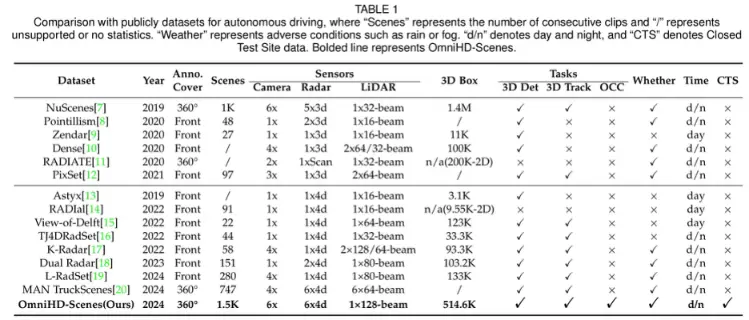
OmniHD-Scenes – Combines high-definition video, LiDAR, and 4D imaging radar data for multimodal environmental perception in autonomous driving
TaskCraft – Multi-step, multimodal task reasoning with visual cues and controlled tool interactions
VeriGUI – Evaluates agents interacting with user interfaces, testing perception-action accuracy and long-horizon task execution on desktop and web-based GUIs
Comparison – OmniHD‑Scenes vs. Publicly Available Autonomous Driving Datasets
Together, these frameworks represent the next generation of AI benchmarking, testing perception, reasoning, and action in real-world contexts.
Early results show progress but also highlight persistent challenges. Even top-performing models achieve less than 50% full-chain success in reasoning-intensive environments like Agent-X. In VS-Bench, prediction accuracy remains below 50%, demonstrating that multi-step planning, long-horizon reasoning, and cross-modal integration are still difficult to master.
How Abaka AI Can Help
At Abaka AI, we understand that as AI systems evolve, evaluation must evolve too. True intelligence can’t be measured by a single accuracy score — it must be tested across perception, reasoning, and action.
As a core contributor to 2077AI, the open-source community advancing benchmark datasets, Abaka AI provides:
Precurated multimodal datasets
High-quality data collection and annotation
Model training and evaluation frameworks
Together with our partners, we’re building a future where reliable benchmarking forms the foundation of trust, innovation, and collaboration in AI.
If you’re interested in off-the-shelf datasets, model training, evaluation, or potential collaboration, contactAbaka AI to start the conversation. Together, we can shape how the next era of AI is measured, understood, and trusted.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.