
AI systems are no longer just generating code snippets. They are debugging production systems, navigating repositories, and collaborating with developers across complex workflows. Yet the way we evaluate these systems still relies heavily on static benchmarks designed for a different era. In short, coding benchmarks measure what a model can produce, but increasingly fail to capture how well it can reason, iterate, and solve real-world problems.
Blogs
2026-04-03/General
Why AI Coding Benchmarks Are Shifting From Static Tests to Agency

Jessy Abu Khalil,Director of Sales Enablement
What Is an AI Coding Benchmark? A Practical Guide for 2026
What Is an AI Coding Benchmark?
An AI coding benchmark is a structured evaluation framework used to assess a model’s ability to generate, complete, or understand code. These benchmarks typically consist of programming problems paired with test cases, where models are scored based on correctness.
One of the most widely used benchmarks is HumanEval, introduced in early evaluations of large language models such as GPT-4. It evaluates Python coding tasks using unit tests and reports performance using pass@k, which measures whether at least one of k generated solutions passes all tests (Chen et al., 2021).
Another widely used dataset is MBPP, which focuses on simpler tasks and broader coverage of programming fundamentals (Austin et al., 2021).
These benchmarks became standard because they are reproducible, scalable, and easy to compare across models.
Summary: Coding benchmarks provide standardized tests for evaluating code generation quality.
How Coding Benchmarks Work
Coding benchmarks follow a structured pipeline. A model receives a prompt describing a programming task, generates one or more candidate solutions, and each solution is evaluated against predefined unit tests.
Coding Benchmark Evaluation Flow
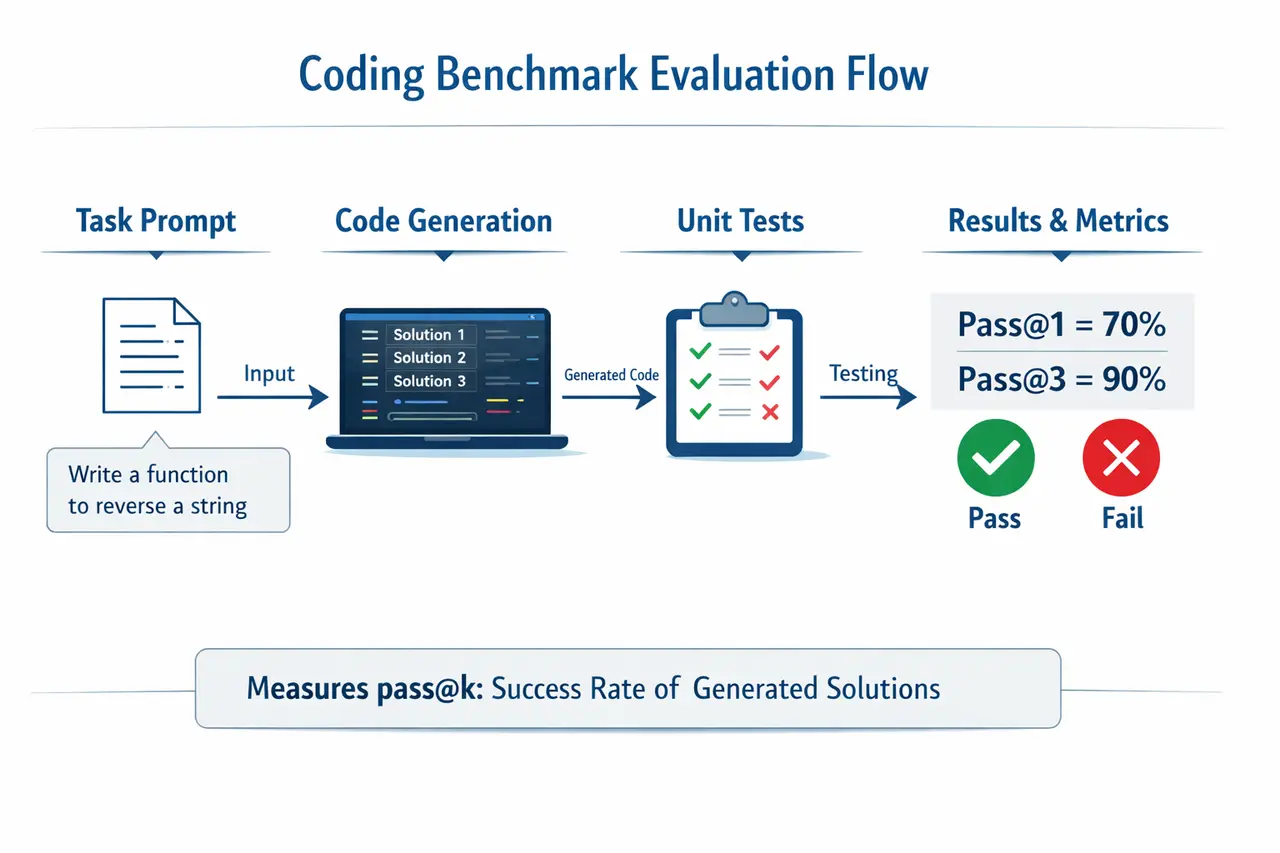
Performance is typically measured using pass@k metrics such as pass@1 or pass@10. For example, a pass@1 score of 70 percent means the model solves 70 percent of tasks on its first attempt.
According to the GPT-4 technical report, modern models achieve strong results on benchmarks like HumanEval, but these scores reflect controlled environments rather than real-world complexity (OpenAI, 2023).
Summary statement: Coding benchmarks evaluate correctness under controlled conditions, not real-world performance.
Why Coding Benchmarks Matter
Coding benchmarks have been essential for tracking progress in AI. They provide a shared standard that allows researchers and companies to compare models consistently.
The Stanford Institute for Human-Centered Artificial Intelligence AI Index Report 2024 highlights that benchmark-driven evaluation has played a central role in measuring advancements in AI capabilities, including code generation.
They are particularly useful for establishing baselines and identifying improvements across model iterations. However, as systems move closer to production, the gap between benchmark performance and real-world behavior becomes more visible.
The Limitations of Coding Benchmarks in 2026

Overfitting to Benchmark Tasks
Because benchmarks like HumanEval and MBPP are publicly available, models can implicitly learn their structure. This can inflate performance metrics without improving general coding ability.
Lack of Real-World Complexity
Most benchmarks focus on short, isolated problems. Real-world software development involves navigating large codebases, understanding dependencies, and working with incomplete specifications.
This gap is addressed by newer benchmarks like SWE-bench (2024), which evaluates models on real GitHub issues. These tasks require debugging, multi-file reasoning, and contextual understanding, making them far closer to real-world engineering workflows.
Summary: Benchmarks simplify coding into isolated tasks, while real-world development is complex and contextual.
No Evaluation of Iteration or Debugging
Coding is inherently iterative. Developers write code, test it, debug errors, and refine their approach.
Traditional benchmarks ignore this process. They evaluate only the final output, not how the solution was reached.
Agent-based benchmarks such as AgentBench (2024) introduce interactive evaluation, requiring models to use tools and adapt over multiple steps. These frameworks better reflect how coding actually happens in practice.
Weak Correlation with Real Performance
High benchmark scores do not necessarily translate into production readiness. Models that perform well on static datasets often struggle with long-horizon tasks, tool integration, and debugging.
Research such as LMRL Gym (2025) shows that performance drops significantly when models are evaluated in interactive, multi-step environments.
Summary statement: Benchmark performance does not reliably predict real-world capability.
Beyond Benchmarks: The Rise of Agent Evaluation
The evaluation paradigm is shifting from static outputs to dynamic behavior.
Instead of asking whether a model can solve a predefined problem, organizations are increasingly asking whether it can:
Navigate real repositories
Debug failing systems
Use external tools effectively
Complete multi-step workflows
This shift has important implications for how datasets are designed. Evaluation is no longer just about correctness, but about capturing realistic workflows, edge cases, and temporal dependencies.
This is where many teams are beginning to rethink their data strategies, moving toward custom, scenario-driven evaluation datasets that better reflect their production environments.
The key difference is not accuracy, but adaptability.
Case Studies: Benchmarks vs Real-World Coding
In controlled settings, models achieve high scores on benchmarks like HumanEval. However, when evaluated on SWE-bench, performance drops significantly due to the need for debugging and repository-level reasoning.
Similarly, agent-based evaluations show that systems equipped with tools and feedback loops can achieve 2 to 3 times higher task completion rates in complex workflows compared to static evaluation setups.
These findings highlight a broader truth: coding is not a one-shot task, but a process of iteration and refinement.
Key takeaway: Success on benchmarks does not equal success in production.
Why You Still Need Benchmarks
Benchmarks remain valuable. They provide a consistent way to measure progress and compare models.
However, they should be complemented by:
Real-world task evaluation
Interactive agent testing
Domain-specific scenarios
Leading teams are increasingly combining standardized benchmarks with custom evaluation pipelines tailored to their specific use cases.
In short, benchmarks are necessary for measurement, but insufficient for real-world validation.
Key Takeaways
AI coding benchmarks have been essential for measuring progress, but they are no longer enough on their own. They evaluate correctness in controlled settings but fail to capture the complexity of real-world software development.
As AI systems evolve into agents, evaluation must evolve as well. This requires moving beyond static benchmarks toward dynamic, environment-based testing and more realistic datasets.
Final summary: Coding benchmarks measure what models can generate, but real evaluation measures what they can accomplish.
FAQs
1. What is an AI coding benchmark?
It is a standardized framework used to evaluate how well AI models generate and solve programming tasks.
2. What is pass@k?
Pass@k measures whether at least one of k generated solutions passes all test cases.
3. Why are coding benchmarks limited?
They focus on static tasks and do not capture real-world complexity, debugging, or iteration.
4. What is SWE-bench?
A benchmark that evaluates models on real GitHub issues, requiring debugging and repository-level reasoning.
5. How are companies improving evaluation today?
By combining benchmarks with interactive environments and custom datasets tailored to real-world workflows.
Further Reading
Continue exploring related topics:
What Are RL Environments for AI Agents? | Enterprise Training
Benchmarks vs. Environments: Scaling Agent Intelligence in AI
Why Game Data Is Powering the Next Generation of AI Reasoning Models
👉 Connect with Abaka AI to explore custom, scenario-driven datasets that reflect real engineering environments and support reliable AI deployment.
Sources
Chen, Mark, et al. “Evaluating Large Language Models Trained on Code (HumanEval).” arXiv, 2021. https://arxiv.org/abs/2107.03374
Austin, Jacob, et al. “Program Synthesis with Large Language Models (MBPP).” arXiv, 2021. https://arxiv.org/abs/2108.07732
OpenAI. “GPT-4 Technical Report.” arXiv, 2023. https://arxiv.org/abs/2303.08774
Stanford Institute for Human-Centered Artificial Intelligence. AI Index Report 2024. Stanford University, 2024. https://aiindex.stanford.edu/report/
Jimenez, Carlos E., et al. “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” arXiv, 2024. https://arxiv.org/abs/2310.06770
Liu, Xiao, et al. “AgentBench: Evaluating LLMs as Agents.” arXiv, 2024. https://arxiv.org/abs/2308.03688
Abdulhai, Marwan, et al. “LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models.” Proceedings of Machine Learning Research, 2025. https://proceedings.mlr.press/v267/abdulhai25a.html
Zhang, et al. “Robust-Gymnasium: Benchmarking Reinforcement Learning under Environmental Uncertainty.” arXiv, 2025. https://arxiv.org/abs/2502.19652
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.