

画像データセットとは?—画像のデータセットを作成する方法
画像データセットは、効果的なコンピュータビジョンモデルをトレーニングするために不可欠な、構造化され、慎重にラベル付けされた画像のコレクションです。高品質のデータセットを構築するには、明確な目標の定義、スマートな画像の調達、正確な注釈、データの多様性の確保、および正確で偏りのないAIを作成するための厳格な品質保証が含まれます。
あなたのコンピュータビジョンモデルは、ぼやけた猫や間違ってラベル付けされたバナナ以上のものに値するからです!
コンピュータビジョンモデルのトレーニングを試みたことがあるなら、この厳しい真実をすでにご存存知でしょう。モデルの知能はデータから始まり、そのデータがめちゃくちゃならそこで終わります。しっかりした画像データセットのない優れたモデルとは?それは、壊れたクレヨンで傑作を描こうとするようなものです。

では、画像データセットとは正確には何でしょうか?簡単に言えば、オブジェクト検出から顔認識まで、機械学習タスクのためにキュレーションされた画像の構造化されたコレクションです。しかし、それはフォルダに放り込まれたランダムな写真の束ではありません。適切なデータセットには、慎重に選択された画像と、「犬」、「歩行者」、「欠陥部品」、「職場閲覧注意(インターネットのおかげ)」などの対応するラベルが含まれています。
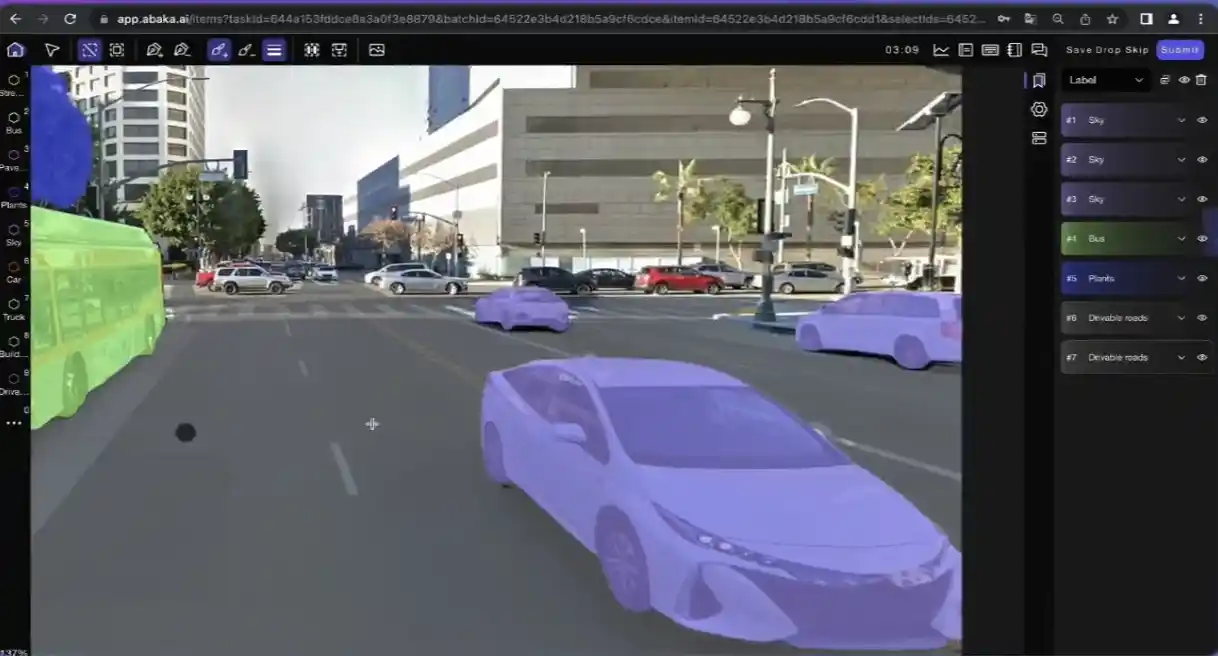
しかし、ここが問題です。高品質の画像データセットを構築することは、たくさんのJPEGをググって最善を期待するほど簡単ではありません。
ウェブをスクレイピングして終わりにする人もいます。ピクセルパーフェクトな注釈にこだわる人もいます。すべてを自動化しようとして、結局、雲と羊を混同するモデルをトレーニングしてしまう人もいます。本当に必要なのは、スマートな収集、慎重なラベリング、継続的なQAのバランスをとるプロセスです。
堅牢な画像データセットを構築するための推奨方法は次のとおりです。
- 目標を定義します。 モデルは何を「見る」ことになっていますか?自動運転車には車線が必要です。ファッションAIには?生地のパターンと衣服の種類です。具体的にしてください。
- 画像を調達します。 ウェブスクレイピング、ユーザー投稿の写真、センサーキャプチャ、または合成生成を考えてみてください。ただし、ライセンスと良心を確認してください。
- 慎重に注釈を付けます。 バウンディングボックス、セグメンテーションマスク、キーポイントなど、タスクが要求するものは何でも、精度が重要です。そこで、専門の人間のラベラーとうまく調整されたツールが違いを生みます。
- バランスと多様化。 データセットに、照明、背景、角度、人口統計(人間の被写体の場合)のバリエーションが含まれていることを確認してください。偏ったデータセットは、偏ったモデルをトレーニングします。
- マニアのように検証します。 間違ってラベル付けされたすべての画像は、モデルにとって後退です。QAはオプションではありません。それは基礎です。

Abaka.AIでは、クリーンで注釈付きで、すぐにトレーニングできるカスタム画像データセットを構築しています。当社のスマートツーリングスタックには次のものが含まれます。
- 人間参加型の修正による自動ラベリングにより、品質を損なうことなく注釈を高速化
- ピクセル精度に最適化された高度なセグメンテーションおよびバウンディングツール
- モデルが1つの視覚的特徴に過剰適合しないようにするためのスマートなクラスバランシングアルゴリズム
- AIを活用した検証と専門家によるレビューを組み合わせた多層QAパイプライン
- リアルタイム分析ダッシュボードにより、データセットの進捗状況とラベルの品質を大規模に追跡できます
X線写真で病気を特定したり、TikTokでスニーカーにタグを付けたりするようにモデルに教えている場合でも、当社独自のスマートツールを使用した自動化と人間の専門知識を組み合わせて、最初から正しく行います。
あなたのビジョンモデルは、思うものではなく、あるべきものを見るデータセットに値するからです。
実際に成果を上げる画像データセットを構築したいですか? 話しましょう。