

画像がAI生成かどうかを判別する方法
💡AI生成画像は、ゆがみ、ラベルの不一致を確認するか、実画像と合成データを区別するよう訓練されたスマート検出ツールを使用することで識別できます。信頼できる結果を得るには、常に技術的なチェックと明確なラベル付けの慣行を組み合わせてください。Abaka AIは、実画像と合成画像の両方のデータを検証および監査するのに役立ちます。
DALL·E、Midjourney、StyleGANなどの生成AIツールが進化し続ける中、実画像とAI生成画像を区別することはますます難しくなっています。特に、機械学習モデルのトレーニングとデプロイに高品質な画像データを依存する企業にとっては重要な課題です。
コンピュータビジョンのトレーニングデータを収集する場合でも、サードパーティからの画像入力を検証する場合でも、AI生成画像と実画像のデータセットを区別する方法を知ることは、モデルの性能を確保し、バイアスを減らし、システムへの信頼を構築するために不可欠です。
画像データセットにとっての重要性
AI開発において、データは基盤です。合成画像と実画像を適切にラベル付けしたり、その起源を理解したりせずに混在させると、モデルの精度を低下させ、出力に歪みを生じさせ、倫理的な懸念を引き起こす可能性があります。
JNTUハイデラバードの研究者による研究を含む最近の研究は、これら2種類のデータを明確に区別する重要性を強調しています。これらの研究は、データセットが適切に準備され、バランスが取れている場合、比較的単純なCNN分類器でもAI生成画像と実画像を区別するよう訓練できることを示しています。
つまり、実際の課題は多くの場合検出そのものではなく、クリーンで透明なデータセットを収集することにあります。
AI生成画像の一般的な兆候
データセット全体や単一の画像を評価する際、人為的に生成された可能性を示すいくつかの危険信号が存在します:
- 背景の微妙なゆがみ(例:歪んだ建物や風景)
- 人間の特徴の不一致、例えば非対称の目や不自然な手
- 輪郭周辺のアーティファクト、特に衣類、髪の毛、細かい質感の部分
- 非論理的なオブジェクトの組み合わせ(例:一致しないイヤリング、奇妙な反射)
画像品質が向上しても、AIモデルは依然として細かいディテールと空間的な論理に苦戦しています。これらのエラーを識別すること、特に大規模に識別することは、合成コンテンツがトレーニングパイプラインに入る前にフラグを立てるのに役立ちます。

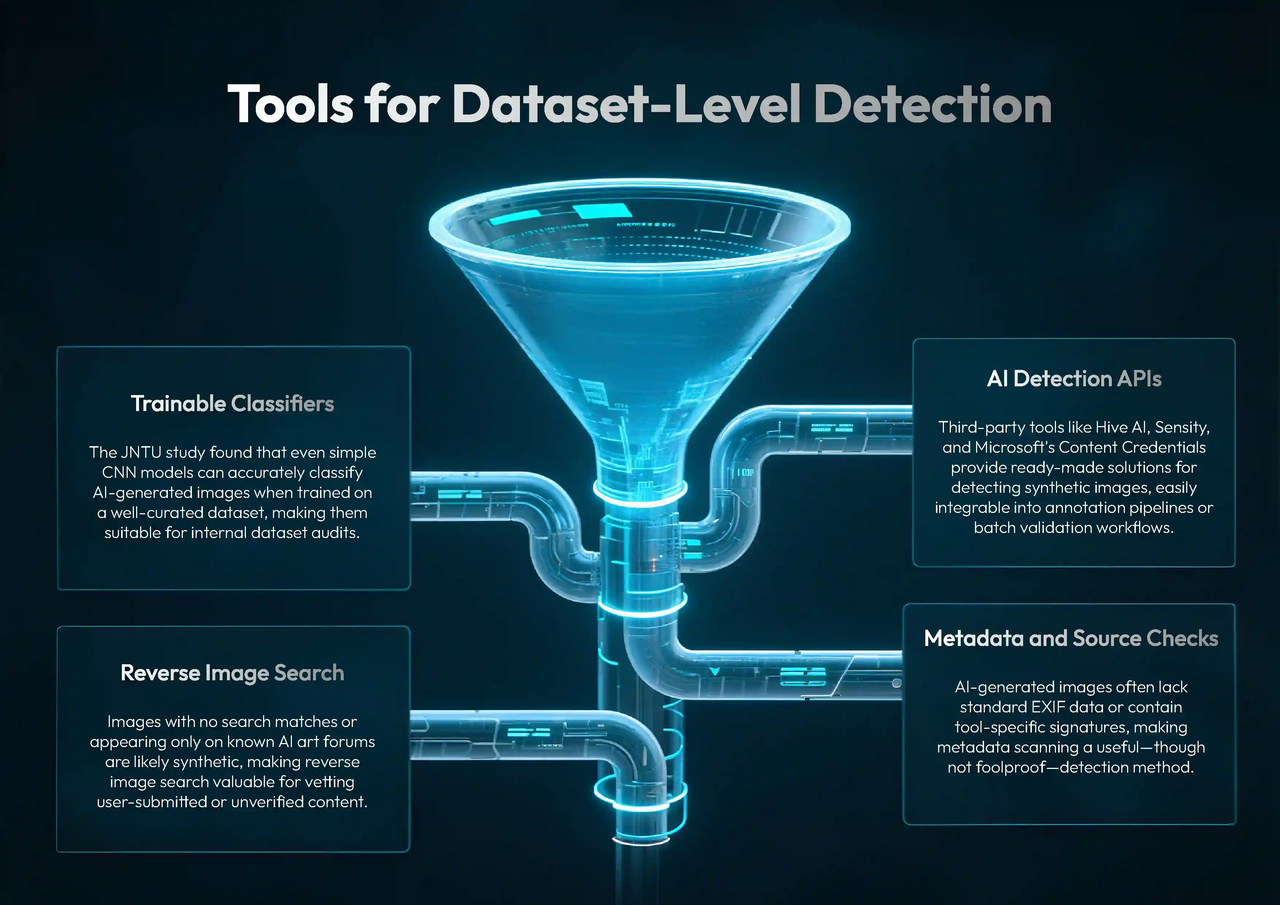
データセットレベルの検出ツール
大規模な画像パイプラインを管理する組織にとって、手動での検査だけでは不十分です。以下は、データセットにAI生成コンテンツが含まれているかどうかを検証するためのスケーラブルな方法です:
1. 訓練可能な分類器
JNTUの研究によると、CNNモデルは、適切に収集されたデータセットで訓練されると、比較的単純なアーキテクチャでも高い精度でAI生成画像を分類できます。これにより、内部のデータセット監査に最適なツールとなります。
3.2 AI検出API
Hive AI、Sensity、MicrosoftのContent Credentialsなどのサードパーティツールは、即座に使用可能な合成画像識別サービスを提供しています。これらはアノテーションパイプラインやバッチバリデータに統合できます。
3.3 メタデータとソースチェック
AI生成画像は多くの場合、EXIFメタデータ(カメラモデルやGPS情報など)を欠いているか、「Midjourney」や「Stable Diffusion」などのツールからの署名を含んでいます。完全に確実ではありませんが、メタデータのスキャンは追加の防御層を提供します。
3.4 逆画像検索
一致する結果がない、または既知のAIアートフォーラムにのみ出現する画像は、合成されている可能性が高いです。この方法は、ユーザーからの投稿や未検証のプラットフォームからデータを取得する場合に特に有用です。
AI生成画像と実画像のデータセットを扱う際のベストプラクティス
意図的にAI生成画像をデータセットに取り入れる場合(例えば、多様性を向上させたり、エッジケースのバランスを取ったりするため)、いくつかのベストプラクティスに従うことが重要です:
- 各画像をメタデータレベルで実画像か合成画像か明確にラベル付けする
- 特に規制遵守のため、生成元とモデルバージョンを追跡する
- 適切な層別化なしにトレーニングでAI画像と実画像を混在させない—適切に処理しない限り、アーティファクトやバイアスを導入する可能性があります
- 新しい画像生成ツールが既存のフィルタを超えて進化する可能性があるため、定期的にデータセットを再監査する
JNTUハイデラバードの研究はこれを強調しています。彼らは、正確な分類を達成する上で、データセットの品質と前処理(リサイズ、拡張、正規化)がモデルアーキテクチャと同じくらい重要であることを発見しました。
結論
生成ツールが進化するにつれ、肉眼に頼るだけでは不十分になっています。AIアプリケーションを構築する場合でも、データを収集する場合でも、ブランドの完全性を保護する場合でも、AI生成画像と実画像のデータセットを区別するための明確な戦略を持つことはこれまで以上に重要です。
視覚的検査、自動検出、および適切なデータセット管理を組み合わせることで、透明性と信頼を維持しながら、性能の高いモデルを構築することができます。
自分のデータセットの検証やAI画像検出パイプラインの構築に役立つ支援が必要ですか?Abaka AIは、チームが大規模に実画像と合成画像のデータを取得、注釈付け、監査するのを支援します。お話ししましょう — Abaka AIのツールと専門家が、先を行くためのサポートを提供します。