

リアルな画像とAI生成画像を区別する方法は?
💡 AI生成画像は、微妙な人工物を探すことや、ラベル付きデータセットで訓練されたディープラーニングモデルを使用することで検出できます。自動分類器は現在、ほとんどの場合で人間による検出を上回っています。スケールで最高の精度を得るには、技術とキュレートされたデータを組み合わせたAbaka AIのソリューションを使用してください。
AI生成画像とリアル画像のデータセットについて
IJIRTに掲載された最近の研究では、AI生成画像とリアル画像のデータセットを使用した実践的なアプローチが取られています。研究者たちは、合成画像と真正な画像のバランスの取れたコレクションでCNNモデルを訓練し、約91%の分類精度を達成しました。これは、適切にキュレートされたデータと組み合わせると、ディープラーニングがどれほど強力であるかを示しています。

視覚的手がかり:異常と人工物
高品質なAI生成画像でも、多くの場合微妙な矛盾が含まれています:
- 形が崩れた手や余分な指 – AIモデルは多くの場合、解剖学的な正確さに苦労します

- プラスチックのような肌や目の異常:光沢があり、平たい、または非対称な目や肌

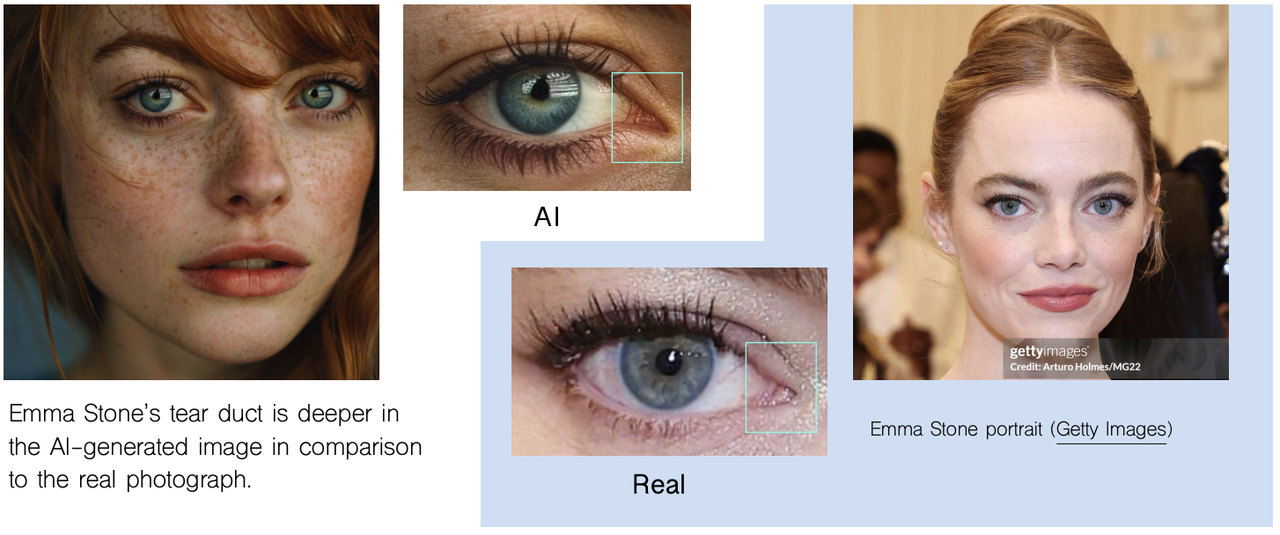
- 一貫性のないテキスト – ごちゃ混ぜの文字、鏡像文字、または意味のない文字を探します


- 繰り返されるテクスチャ – 髪、毛皮、葉っぱは不自然なパターンを示すことがあります

- 照明と影 – しばしば矛盾や物理的に不可能な投影が出現します

例えば、この写真では、女の子たちの影は後ろに落ちていますが、木の影は歩道の左側にあります。女の子たちの影と一致させるには、木はその影の前にあるべきです。また、女性の影に鋭い角があり、これは不自然です。
- 遠近法の誤り – 位置合わせがずれた線や歪んだ構造物は、多くの場合合成された起源を明らかにします
この女性は鏡の真正面に立っていますが、彼女の反射は後ろを向いています。

最近の別のガイドでは、これらの矛盾を5つのカテゴリー(解剖学的、様式的、機能的、物理学的、社会文化的)に分類しており、それぞれが何かがおかしいことを示す手がかりを提供しています。
技術的検出:法医学とディープラーニング
視覚的な検査で不十分な場合、技術的な方法でさらに詳しく調査できます:
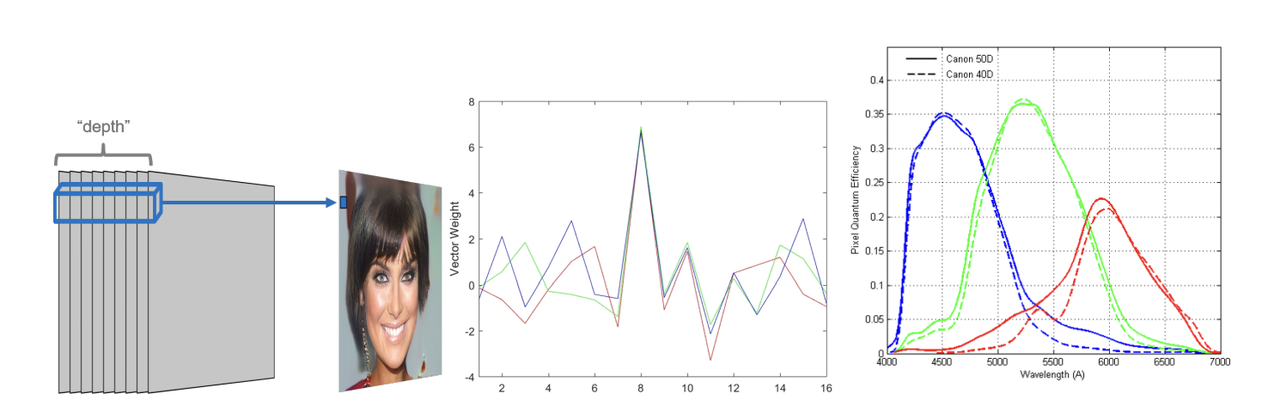
- 色分布分析により、AI生成画像(特にGANによるもの)は、リアルなカメラにはない特定の予測可能なパターンを持つ傾向があることが明らかになります。
GAN生成画像(左と中央)は、固定された畳み込み重みを使用して複数の深度層をRGBピクセルに結合し、一貫したが人工的なパターンを生成します。対照的に、リアルなカメラセンサー(右)は、デバイス全体で変化し、より自然なスペクトル応答を持つカラーフィルターアレイに依存しています。
- ディープラーニング分類器(ResNet、VGG、DenseNetなど)は、CIFAKEなどのデータセットで訓練することで、偽物を見分ける精度が最大98%に達することができます。

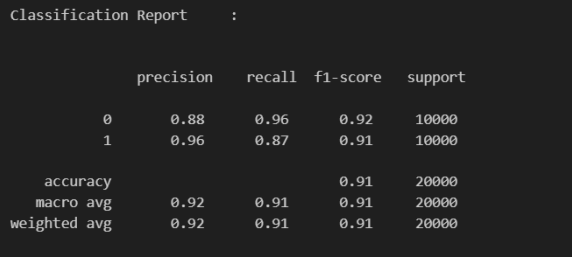
- 例えば、IJIRTモデルは次の成果を達成しました:
- 全体的な精度91%
- リアル画像の再現率0.96
- AI生成画像の再現率0.87
人間 vs AI:誰が偽物を見分けるのが上手ですか?
驚くべきことに、人間は思っているほど上手く表現しません。研究によると、人々はAI生成画像の約39%を誤分類しています。比較すると、最高のAI検出器の誤り率は13%近くです。これは、最も効果的なアプローチは人間の洞察とAIの支援を組み合わせることであるという考えを強化しています。
画像評価の実用的なチェックリスト
| チェックポイント | 確認事項 |
|---|---|
| 手と解剖学 | 余分な/欠けた指、奇妙な手足の配置 |
| テキストと標識 | ごちゃ混ぜの、鏡像の、ピクセル化したテキスト |
| 照明と影 | 一貫性のない影や光の角度 |
| テクスチャとパターン | 繰り返される、または完璧すぎるテクスチャ |
| 物理的一貫性 | 位置合わせのずれた遠近法や物体のスケール |
| 色と人工物 | 不自然な色のバランスやノイズ |
| 文脈上の異常 | 奇妙な物体の配置やありえない設定 |
検出システムの統合と改善
IJIRTの「リアル vs AI生成画像の検出と分類」フレームワークは、以下の手順を使用しています:
- 収集:リアル画像とAI生成画像のデータセットを収集(例:「This Person Does Not Exist」から)
- 前処理(224×224にリサイズ、正規化、拡張)
- CNNの構築:畳み込み-プーリング層、全結合層を備え、Adamオプティマイザを使用して訓練(Britannica Education、arXiv、IJIRT)。
- 評価:91%の精度、リアル画像で0.92のF1スコア、AI画像で0.91のF1スコア(IJIRT)。
- デプロイ:インターフェースを介して(例:画像アップロードと分類のためのStreamlitウェブサイト)(IJIRT)。
この研究では、データセットの拡大、新しい拡散ベースのモデルの探索、ソーシャルメディアのコンテンツモデレーションのためのリアルタイムツールの統合など、今後の改善点も指摘されています。
最後に
AIツールが進化し続けるにつれ、欺瞞の技術も進化しています。幸いなことに、観察、技術、批判的思考を適切に組み合わせることで、私たちは先を行くことができます。オンラインで偽の顔を見つける場合でも、プラットフォームのコンテンツを検証する場合でも、何を探すべきか、そしてAI生成画像とリアル画像のデータセットで訓練されたツールをどのように活用するかを知ることで、大きな違いを生み出すことができます。
検出精度を向上させたり、堅牢な画像法医学パイプラインを構築したりしたいですか? Abaka AIと連絡を取って、データ駆動型のソリューションをご覧いただき、コンテンツ検証プロセスを強化してください。