How to Choose an AI Training Data Services Provider: 7 Questions Enterprise Buyers Should Ask
Jessy Abu Khalil,Director of Sales Enablement
Artificial intelligence systems succeed or fail largely because of the quality of the data used to train them. According to the Stanford Institute for Human-Centered AI AI Index Report, data preparation and labeling account for about 80% of the time spent on AI projects. At the same time, research from Gartner estimates that poor data quality costs organizations an average of $12.9 million per year due to operational inefficiencies, inaccurate analytics, and decision errors.
For enterprise teams developing large scale AI systems such as robotics, autonomous vehicles, and large language models, choosing a training data provider is not just a procurement decision. It is a core infrastructure decision.
In short, the right provider does more than label datasets. The best partners operate secure, scalable, and continuously improving data pipelines that directly influence model performance.
How to Choose an AI Training Data Services Provider: 7 Questions Enterprise Buyers Should Ask
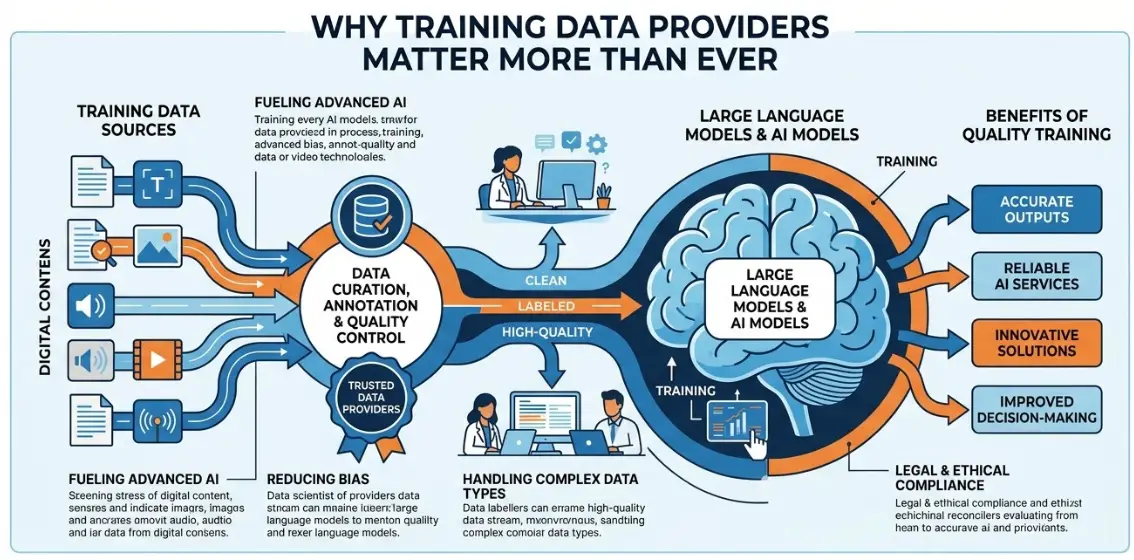
Why Training Data Providers Matter More Than Ever
Training Data Providers Matter More Than Ever
The rapid growth of generative AI and multimodal systems has significantly increased the demand for high quality datasets.
A report from McKinsey & Company shows that AI adoption among companies has more than doubled since 2017, while the amount of data required to train modern models continues to grow. Many AI systems now require:
Millions of labeled images or video frames
Billions of text tokens
Thousands of hours of annotated audio
For example, reinforcement learning pipelines used by OpenAI rely heavily on human feedback datasets where trained annotators evaluate model outputs and rank responses.
This shift means enterprises must evaluate training data providers based on their data infrastructure, quality control systems, and scalability, not just their labeling capacity.
7 Questions Enterprise Buyers Should Ask
1. What Data Quality Assurance Processes Do They Use?
Reliable AI systems require rigorous dataset validation.
Leading training data providers implement quality control systems such as consensus labeling, expert review layers, benchmark datasets, and automated validation tools.
Research discussed in Nature Machine Intelligence highlights that dataset quality and labeling consistency play a critical role in machine learning performance. Even small annotation inconsistencies can reduce model accuracy.
Summary statement: In short, strong quality assurance processes are often the difference between usable training data and unreliable datasets.
2. Do They Have Domain Expertise in Your Industry?
Training data requirements vary significantly across industries.
Examples include:
Industry
Annotation Requirements
Autonomous driving
LiDAR segmentation and sensor fusion
Healthcare AI
Medical imaging annotation
Retail
Product attribute tagging
Finance
Document entity extraction
Autonomous vehicle developers such as Waymo rely on specialized annotation teams trained to identify complex road scenarios and rare edge cases.
Research in applied machine learning shows that domain expertise in data annotation can significantly improve model accuracy compared with generic labeling approaches.
Summary statement: The key difference between generic annotation vendors and specialized providers is not scale. It is domain expertise.
3. Can Their Workforce Scale With Your AI Pipeline?
Enterprise AI systems often require extremely large datasets.
For example, autonomous driving systems may require tens of millions of labeled objects each year, while large language models may require billions of annotated data points.
AI infrastructure companies such as Abaka AI manage distributed global annotation workforces and specialized data platforms to support this demand.
According to Gartner, demand for training datasets continues to grow as organizations expand their AI deployments.
Summary statement: A provider's workforce scalability determines whether they can support enterprise scale AI deployment.
4. How Do They Protect Sensitive Data?
Training datasets often contain sensitive or proprietary information. This may include customer content, medical images, financial documents, or internal enterprise data.
Organizations should confirm that providers follow established security frameworks such as SOC 2, ISO 27001, GDPR, and HIPAA for healthcare datasets.
The IBM Security Cost of a Data Breach Report found that the average global data breach cost reached $4.45 million in 2023.
Summary statement: Security is a core requirement for enterprise AI training pipelines.
5. What Annotation Tools and Automation Do They Use?
Modern AI dataset pipelines combine human expertise with automated tools.
Advanced providers often deploy active learning pipelines, automated pre labeling systems, dataset management platforms, and edge case detection tools.
Industry research from Gartner suggests that AI assisted annotation can significantly improve labeling efficiency and reduce dataset production costs.
Summary statement: The goal of modern training data pipelines is not manual labeling alone. It is efficient collaboration between humans and machine learning systems.
6. Can They Handle Multimodal Data?
Many modern AI systems rely on multimodal datasets that combine different types of data.
Examples include image and text datasets used in vision language models, audio datasets for speech recognition systems, and video datasets used in robotics perception.
Researchers at Google DeepMind have developed multimodal systems trained on combinations of text, images, audio, and video.
Industry analyses from CB Insights show that multimodal AI startups have raised billions of dollars in funding in recent years as demand for advanced AI systems continues to grow.
Summary statement: Training data providers must support multimodal datasets, not only single format data.
7. Do They Support Continuous Dataset Improvement?
AI datasets are not static resources. They must evolve as models improve.
Most high performing AI systems rely on an iterative data cycle that includes training models, identifying errors, collecting additional data, labeling new edge cases, and retraining the system.
Research from Google Research highlights that iterative dataset improvement and active learning pipelines can significantly improve machine learning performance over time.
Summary statement: The best training data providers support long term dataset improvement pipelines rather than one time labeling projects.
Key Takeaways
Choosing an AI training data services provider requires evaluating far more than cost.
Enterprise buyers should prioritize providers that offer:
Strong data quality assurance systems
Domain expertise within the target industry
Scalable annotation workforces
Robust security and compliance frameworks
Advanced annotation tools and automation
Multimodal dataset capabilities
Continuous dataset improvement pipelines
In short, AI models are only as reliable as the datasets used to train them.
Contact Us
Ready to build reliable AI models with high quality training data? 📩Contact our teamto learn how scalable data collection, annotation, and validation pipelines can support your next AI project.
Explore Related Resources
If you are exploring enterprise AI infrastructure, these articles may also be useful.
What does an AI training data services provider do? An AI training data services provider collects, annotates, and manages datasets used to train machine learning models, including text, images, audio, and video.
Why is training data quality so important for AI models? Training data quality directly affects model accuracy and reliability. According to the Stanford Institute for Human-Centered AI AI Index, data preparation and management represent a large portion of machine learning development work.
How large are typical AI training datasets? Dataset size varies by application. Large language models may require billions of tokens, while autonomous driving systems often require millions of labeled images and sensor frames.
How should enterprises evaluate a training data vendor? Enterprises should evaluate vendors based on data quality processes, industry expertise, scalability, security standards, and the ability to continuously improve datasets.