
Choosing an AI data provider is less like signing a contract and more like choosing who pours the foundation of your future system. Some vendors move fast and cheap. Others build carefully and last. This article walks through how to tell the difference before biased labels, hidden costs, or brittle pipelines show up in your metrics. Quality first. Scale without pain.
Blogs
2026-01-09/General
How to Choose AI Data Providers: Quality, Scale, and Cost Compared

Tatiana Zalikina,Director of Growth Marketing
How to Choose AI Data Providers: Quality, Scale, and Cost Compared
What makes AI data, the lifeblood of machine learning, good? And what makes a vendor worth your team’s time, budget, and trust? That's the question. Is it simply a commercial contract? Or is it like picking a bridge builder: one who delivers something strong, elegant, and lasting, or a pile of bricks faster than you can lift them?
Choosing an AI data provider isn’t a checkbox exercise. Too much hinges on the data you feed your models: clean or dirty, representative or biased, complete or broken, it all shows up in your model’s behavior, obviously. Even industry research tells us that poor-quality training data can degrade model performance by 10–25%, hurting business outcomes directly.
Let’s stroll through what matters, quality first, then scale, then the part that makes finance teams gleeful: ✨the cost✨.
1. What “AI Data Provider” Means
In AI development, “data provider” can mean many things:
Raw training data collections
Data collection services
Annotation/labeling teams
Synthetic data generation vendors
Managed pipelines that collect, label, validate, and deliver ready-to-use datasets
Or altogether.
Different vendors solve different parts of that pipeline. Some are great at curating massive raw datasets, others specialize in annotation quality, and a few do both while offering augmentation, bias mitigation, and compliance protocols.
Before you pick someone, define which part of the pipeline matters most for your project.
2. How to Choose AI Data Providers
1. Quality: The Base of the Pyramid
Imagine building a cathedral on sand versus granite. Quality matters THAT much.
Good quality AI data is:
Clean and consistent: With no glitches, anomalies, missing values, or random formatting errors.
Relevant and diverse: Reflective of real-world distributions across regions, languages, ages, etc.
Accurately labeled: Close to the “ground truth” your training assumes.
Free of systematic bias: So models generalize and don’t inadvertently harm users.
When providers source and annotate data, ask yourself:
Does their dataset reflect the real world my model will face? If not, your model will learn gaps and biases, and you’ll pay to fix them later. A lot.
Annotation quality deserves special attention, too. In data labeling tasks, clear instructions and structured rules significantly improve annotator accuracy. An experiment conducted by Johann Laux found that simply giving clear rules improved accuracy by 14% compared to vague ones, and adding incentives further boosted accuracy.
When evaluating vendors, request sample quality metrics like test-set accuracy, inter-annotator agreement, or even confusion matrices. If a provider can tell you how good its labels are, that’s a huge credibility signal.
2. Scale: Growth Without Pain
Once quality is in place, the next level is quantity, and the ability to scale it when your project grows.
You probably know that scale matters because many real-world AI use cases require far more than a few thousand samples. Some research pipelines suggest needing at least 100,000 high-quality samples just to get decent baseline performance.
Ask potential providers:
Can they handle volume increases smoothly? Some vendors can scale from thousands to millions of annotations without quality loss.
Do they have global reach and contribute diversity? Global datasets, spanning 150+ languages and multiple geographies, help avoid blind spots in your models.
Do they support multiple data types? Text, image, video, LiDAR, audio, modern AI isn’t one-modal anymore.
What automation tools do they use? AI-assisted annotation and automated QC keeps quality high and turnaround fast.
Scalability also includes delivery speed and flexibility, especially if you’re building fast-moving products or operating in competitive markets.
3. Cost: Budget Smart, Not Cheap
Science meets spreadsheet poetry.
Cost is more than a single number; it’s a negotiation between quality, speed, and scale. But a few real industry factors influence vendor pricing:
3. Pricing Models You’ll See (And How to Read Them Correctly)
AI data pricing rarely comes as a single neat number. Instead, it’s expressed through units that reflect how humans actually touch the data: frames, seconds, objects, hours, or entire projects. Understanding these units matters more than comparing raw quotes.
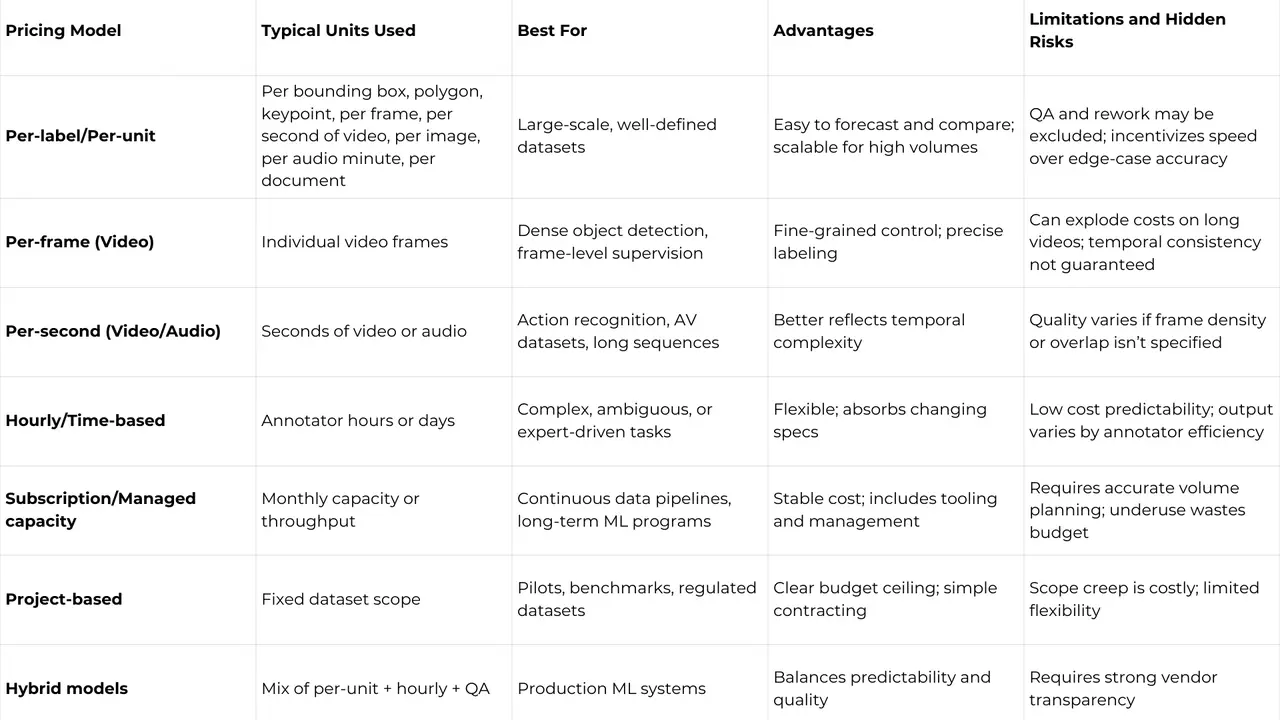
1. Per-Label/Per-Unit Pricing
The “unit” depends on data modality:
- Images → per bounding box, polygon, keypoint, or image
- Video → per frame or per second of video
- Audio → per second or per minute of audio
- Text → per document, sentence, or entity
This model is easy to forecast at scale: count the units, multiply, done. The catch: QA, review passes, and edge-case handling may be priced separately or bundled inconsistently. Cheap per-unit pricing often assumes minimal quality control.
Best for: large, well-defined datasets with stable annotation rules.
2. Time-Based Pricing (Hourly/Daily)
Here, solutions are billed by time spent, not output:
- Common for complex, ambiguous, or exploratory tasks
- Often used for expert labeling, audits, or ontology refinement
- Frequently paired with human-in-the-loop workflows
This model is flexible but less predictable. Two annotators can spend very different amounts of time on the same task, especially when specs evolve mid-project.
Best for: early-stage projects, research datasets, or rapidly changing requirements.
3. Subscription/Managed Capacity
You pay a recurring monthly fee for a defined throughput or team capacity:
- Continuous data streams (e.g., daily video ingestion)
- Long-running ML programs with steady annotation needs
- Integrated tooling + workforce + QA pipelines
This model prioritizes operational stability over per-unit optimization. It often includes project management, QA, and tooling, but only if clearly defined upfront.
Best for: teams with ongoing annotation needs and predictable volume.
4. Project-Based Pricing
A fixed price for a clearly scoped dataset:
- Defined volume
- Fixed annotation schema
- Known delivery timeline
This model works well when requirements are stable; however, it breaks quickly when they aren’t. Scope creep is the budget killer.
Best for: well-specified pilots, benchmarks, or regulatory datasets.
Choosing the Right Pricing Unit (Not the Lowest One)
Different pricing units optimize for different risks:
- Per-frame pricing rewards speed but can punish quality in dense scenes
- Per-second video pricing favors long-form consistency
- Hourly pricing absorbs ambiguity but reduces predictability
- Project-based pricing assumes clarity, whether you actually have it or not
Across industry breakdowns, mid-tier providers tend to balance cost and quality more reliably, with production accuracy commonly stabilizing in the mid-90% range when QA is properly structured. Lower pricing often correlates with fewer review passes, thinner specs, and slower rework cycles.
Don’t Forget the Hidden Costs
Even transparent pricing can mask real expenses:
- Re-annotations and revisions
- Multi-stage QA and arbitration
- Project management overhead
- Data security and access controls
- Integration with internal pipelines
This is why experienced teams evaluate total cost of ownership (TCO), not the first invoice. A cheaper dataset that needs rework is rarely cheaper in the end.
Also consider hidden costs: revisions, rework, project management overhead, data security controls, and integration expenses. Building total cost of ownership (TCO) into your evaluation is an essential best practice.
4. Ultimate Choosing Criteria Guide (Your Vendor Scorecard)
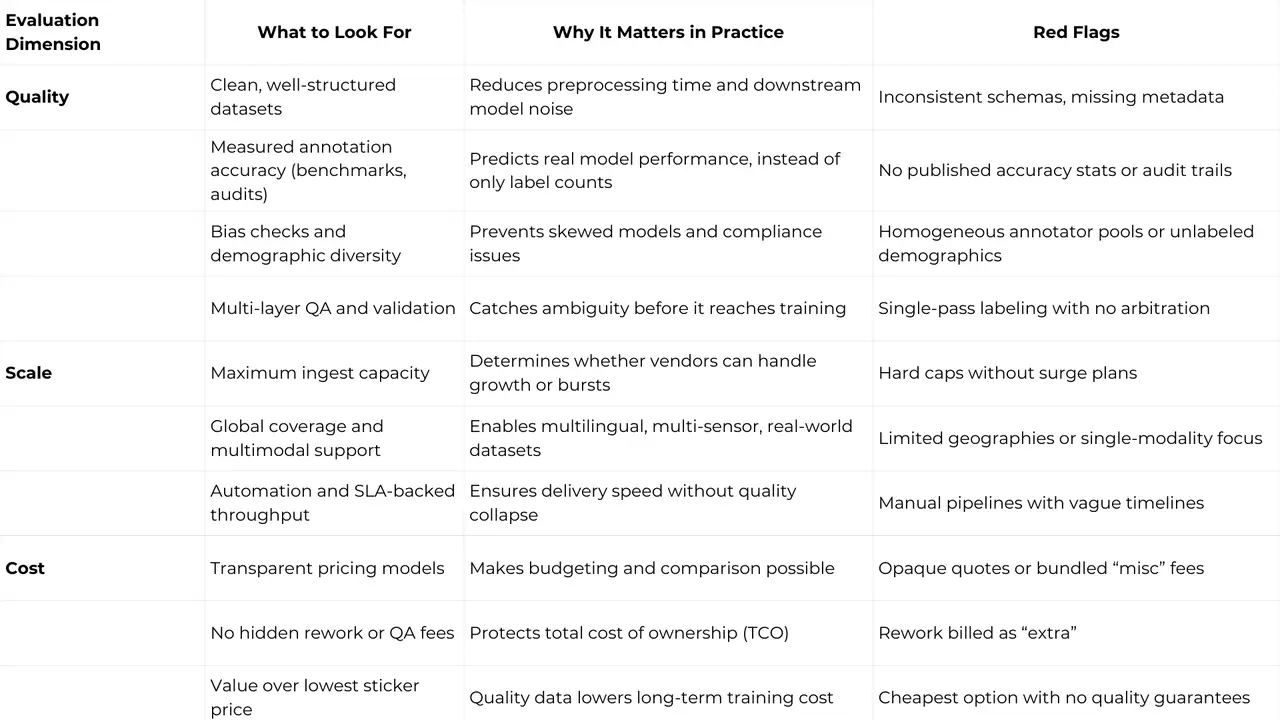
To choose confidently, evaluate providers across three dimensions:
Quality
Cleanliness and structure of data.
Annotation accuracy (benchmark stats).
Bias checks and demographic diversity.
QA processes and validation layers.
Scale
Maximum ingest volume.
Worldwide coverage and multi-modal support.
Tools for automation/SLA guarantees.
Cost
Transparent pricing models.
No hidden rework fees.
Value over lowest sticker price.
5. Examples of Provider Types You’ll Evaluate
Here’s how different sorts of AI data providers position themselves in 2025.
Enterprise-Scale Annotation Firms
Big players with global reach, high automation, and deep QA systems, ideal for massive, critical datasets.
Domain-Specialized Providers
Experts who excel in specific verticals (e.g., medical, autonomous driving) with niche expertise and strict compliance.
Open-Source or Tool-Driven Aggregators
Platforms that blend community contributions with tooling for cost savings, good for experimentation and prototyping, but require strong oversight.
Synthetic Data Platforms
Providers who generate AI-ready data synthetically, useful when real samples are scarce.
6. Where Abaka AI in This Landscape
Choosing an AI data provider often feels like choosing which part of your future you’re betting on. Here’s why Abaka AI deserves a seat at your comparison table:
✨ Holistic Pipelines: We ignore simple labeling; instead, we help source, clean, annotate, validate, and package data for modeling. ✨ Hybrid Quality Control: We blend machine assistance with human review, increasing throughput without sacrificing quality. ✨ Scalable Architecture: From thousands to millions of items, we scale with your project, including multimodal data types and vast diversity. ✨ Transparent Costing: No hidden fees, clear pricing models, and engineered efficiency to give you bang for your buck.
Abaka AI’s approach is designed to solve the central challenge every AI team faces: data that’s reliable, timely, and aligned with your use case :)
7. Final Thought: No Data is a Commodity; It’s a Narrative
Good AI data isn’t “lots of examples” at all. More precisely, it’s the story your model learns from. It’s the diversity of voices, the richness of real-world contexts, the precision of accurate labels, and the foresight of thinking about future scale.
A cheap dataset might get a prototype running. A good one makes your model behave responsibly in the wild.
Choose carefully. Measure something other than price. And always remember: the right provider doesn’t only sell data, they entirely shape the foundation of what your AI can become.
Choose carefully and wisely. Contact us.
Further Readings
Abaka AI vs Dataloop: End-to-End Data-Centric AI Development Platform
How to Outsource Data Processing: Cost, Risks & Best Practices
Latest Insights in AI & Data | Dec 1-31
Best data annotation tools for machine learning in 2025
Annotate a Video Poorly and No Amount of Data Will Save Your Mode
Sources:
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.