
Video models often fail not because of too little data, but because labels are too coarse or inconsistent. As video understanding becomes temporal and multimodal, label granularity has emerged as a key driver of model performance, not just data scale and model size.
Blogs
2025-12-26/General
Annotate a Video Poorly and No Amount of Data Will Save Your Mode

Nadya Widjaja,Director of Growth Marketing
Annotate a Video: Why Label Granularity Determines Model Performance
Video models rarely fail because of insufficient data. Often they fail due to coarse, vague, or inconsistent labels.
Label granularity has started emerging as one of the strongest and underestimated drivers of model performance following the shift of video understanding from static toward multi-label, temporal, and multimodal reasoning. Evidence from academic benchmarks, medical AI, and production-scale annotation workflows all arrive at the same conclusion:
How you label data matters as much as how much data you have.
This article explains why label granularity is a modeling problem, how research provides evidence on its influence on model accuracy, and why it has become a competitive advantage in modern video training pipelines.
Why Is Label Granularity a Modeling Problem, Not Just an Annotation Choice?
Modern video models are not trained on isolated labels. They learn from correlated signals: actions, scenes, objects, attributes, and temporal transitions. If labels are too coarse, these correlations are read as noise, resulting in weaker model performance.
A recent study by Tianna et al. on granular correlation-based label-specific feature augmentation (GOFA) shows that performance improves when labels are represented at multiple levels of granularity, rather than as a single overall signal. The key insight here is that models learn better when labels explain why label A applies 'here' (locally) and why label B does not.
This applies to video annotation where a clip labeled only as “sports” provides little learning signal. A clip labeled as sports → basketball → dunk → indoor → crowd present, however, exposes the hidden structure that models can learn from.
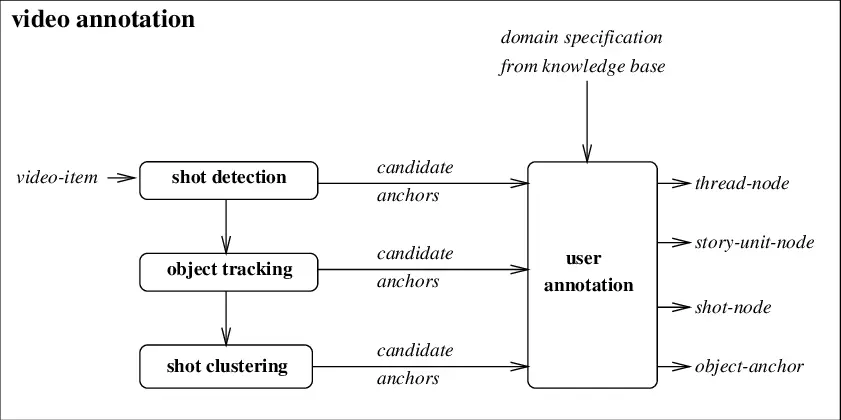
At Abaka AI, this distinction appears repeatedly across our custom video annotation projects, large-scale multimodal datasets, and evaluation benchmarks delivered to leading AI teams. The shift towards hierarchical and context-aware video labels, which are designed and enforced through Abaka AI's task-specific taxonomy design, human-in-the-loop annotation workflows, and multi-level temporal labeling pipelines, their downstream models consistently show stronger generalization. Improvements in model performance are most visible in multimodal reasoning tasks, where models must identify why an action occurs and how it relates to surrounding context, not merely relying on surface-level visual similarities.
What Does Research Show About Granular Labels and Model Performance?
The GOFA framework was evaluated on 13 benchmark datasets using five standard multi-label metrics, including Hamming Loss, Ranking Loss, Average Precision, and Macro-AUC. The granular approach ranked best overall across different datasets in aggregate, and frequently first or second per benchmark.
Most importantly, these gains were achieved without increasing model complexity. Instead of adding parameters or computing power, GOFA improves accuracy by improving labels using local neighborhood information:
instance similarity (who looks like whom)
label distribution (which labels appear nearby)
neighborhood compactness (how tight the cluster is)
Better label structure can outperform bigger models.
Similar patterns emerge in Abaka AI’s multimodal and video training pipelines. Instead of scaling raw video volume by default, Abaka emphasizes label taxonomy design, temporal segmentation strategy, and multi-level semantic labeling all the way from scene and action to contextual attributes. This translates into fewer retaining iterations, lower label correction rates, and faster convergence on complex video understanding tasks.
Is Granularity Just About "More Labels" or About the Right Level of Detail?
Granularity is often mistaken for increasing label count. In reality, it is about capturing meaningful variation at the appropriate level of detail.
Effective granularity is:
Spatial granularity: bounding boxes vs polygons vs cuboids
Temporal granularity: frame-level vs segment-level vs clip-level
Semantic granularity: scene → action → object → attribute

Choosing the wrong level of labeling limits model performance. For example, if an action clearly starts and ends, labeling the entire clip ignores important timing/temporal information. Similarly, using rough bounding boxes for thin or complex objects, where segmentation is required, weakens model accuracy down the line.
Abaka AI’s video datasets are designed around task-aligned granularity, rather than annotator convenience. Granularity works when it reflects how the model reasons, not how quickly humans can label.
Why Does Label Granularity Break Down in Real Video Annotation Workflows?
Granular labels are powerful but fragile. Several workflow decisions can silently diminish their value.
First, over-labeling and vague categories both reduce the effectiveness of learning. Over-labeling increases inconsistency and inter-annotator disagreement, while vague labels blur class boundaries. Again, granularity is about resolution, not quantity.
Second, poor temporal segmentation undermines fine-grained labels. Annotating long, continuous videos without logical clip boundaries introduces context drift and inconsistent label scope.
Third, automation without governance backfires. Keyframes, interpolation, and object tracking can accelerate annotation, but only when motion and occlusion do not change label interpretations. Otherwise, automation propagates subtle errors faster than humans can detect them.
This is why granular labeling demands stronger annotation guidelines: clear definitions, visual examples, consistent metadata, and feedback loops—principles embedded directly into Abaka AI’s human-in-the-loop annotation systems.
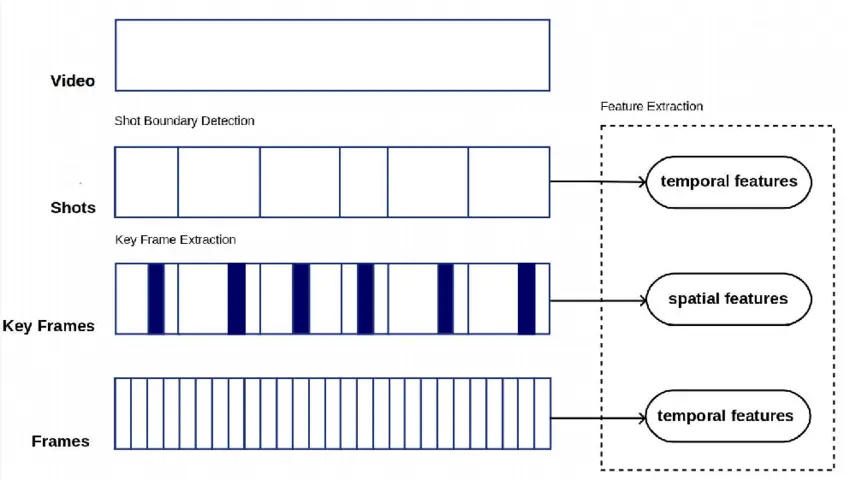
What Happens When Labels Become Too Coarse? Evidence from Medical AI Case Study
A dermatology study by Shah et al. provides one demonstration that label granularity alone can change model performance.
In the study, researchers tested whether the level of detail of the labels can change how well a model performs. They trained AI models to identify if a skin lesion was benign or malignant using skin-tone labels that were either more detailed or more simplified.
In the detailed setup, skin tones were split into three separate groups, while in the simplified one, several lighter skin tones were combined into one group. Everything else was kept constant, including the amount of training data, the ratio of benign versus malignant cases, and the test images.
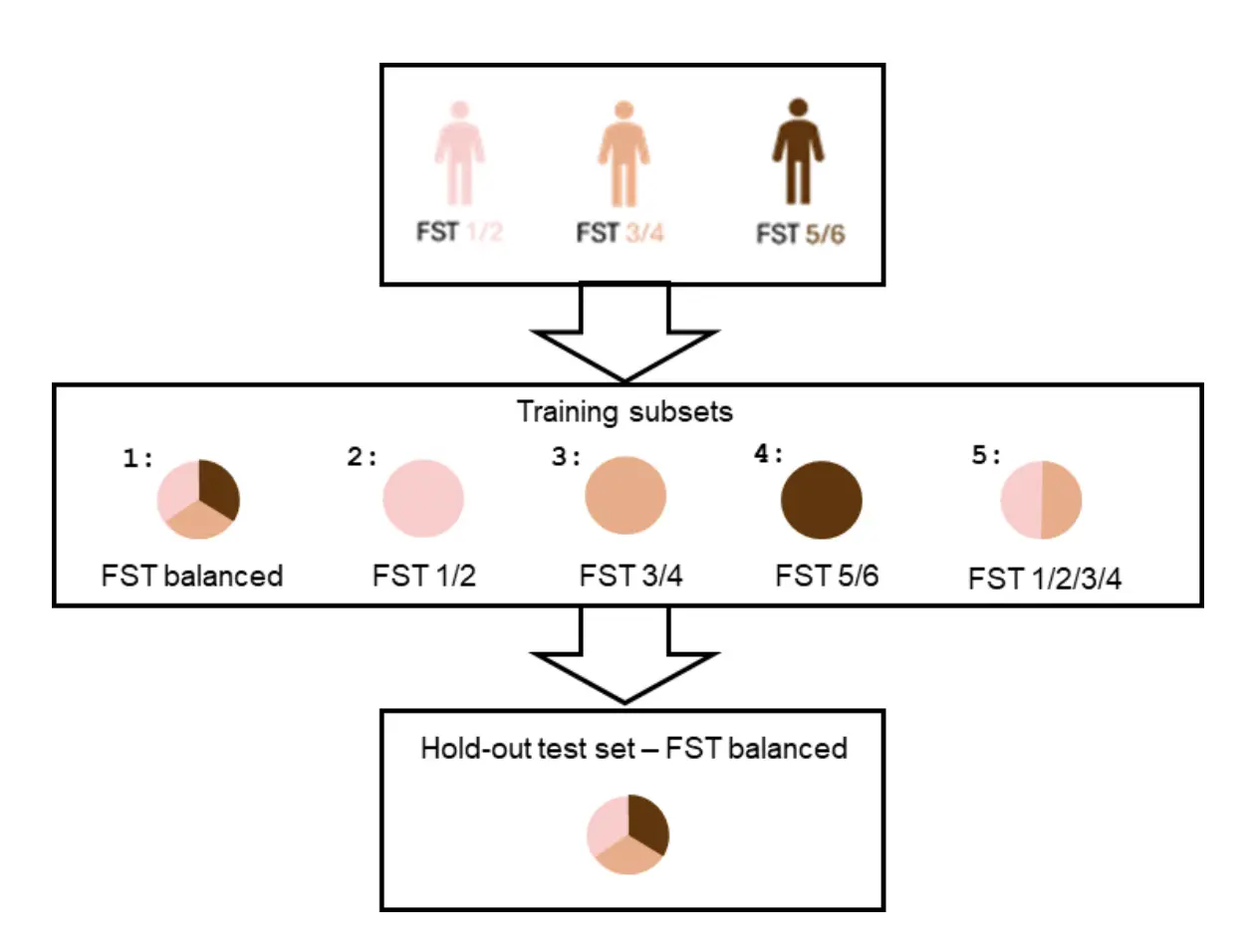
When the labels were simplified, model accuracy dropped, and the model also became less reliable at telling cases apart, with key indicators dropping from 87% to 84%, and another from 79% to 75%. While the percentage changes look small in magnitude, in machine learning, this drop in accuracy is statistically significant. This happened because simpler labels hide important differences; when very different examples are grouped together under one label, the model struggles to learn which ones are actually important.
The same can be applied to video data. Combining clearly different actions or scenes into a single label may make annotation simpler and faster, but it removes the details models need to learn and perform well on new data.
Why Granularity Has Become a Competitive Advantage in Video Training Data
Today, many teams have similar models and computing power, making data quality and data structure the true differentiators. For teams training video-centric and multimodal models, granularity is no longer optional but a structural advantage.
At Abaka AI, label granularity is treated as an early data design consideration, not as an afterthought in annotation. By aligning label classification systems with model objectives, as well as enforcing consistency through expert annotation, Abaka AI aims to produce datasets that support multiple tasks without repeated relabeling and better suited for efficient model training.
👉Explore Abaka AI's platform for scalable video annotation 👉 Browse Abaka’s off-the-shelf video & multimodal datasets 👉 Learn how Abaka evaluates and benchmarks multimodal models
Key Takeaways
Label granularity directly affects model accuracy, calibration, and fairness
Fine-grained labels reveal correlations between actions, context, and time, resulting in reduced noise and better model performance
Granularity is multi-dimensional: spatial, temporal, and semantic
In modern video pipelines, improving label structure yields more performance gains than increasing model capacity alone
Want to Learn More About How Abaka AI Supports High-Quality Video Data Annotation?
Contact Us - Speak with our specialists about designing task-aligned label taxonomies, enforcing granular video annotation workflows, and building high-quality training data for video and multimodal models
Explore Our Blog - Read more on label granularity, video annotation strategies, and how data structure shapes model performance.
See Our Latest Updates - Discover new releases, tooling improvements, and partnerships advancing large-scale video and multimodal AI training at Abaka AI.
Read Our FAQs - Find answers to common questions on video annotation workflows, label structure, temporal segmentation, and dataset curation.
Explore More From Abaka AI
Some Further Reading
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.