Claude Opus 4.5: The New King of AI Coding & Reasoning
Yuna Huang,Marketing Curator
Anthropic has launched Claude Opus 4.5, a new frontier model that outperforms top rivals from Google and OpenAI on critical software engineering benchmarks. With breakthroughs in reasoning, agentic capabilities, and safety, Opus 4.5 represents a significant leap for automated coding and complex task management. However, leveraging its full potential requires a robust data strategy—something Abaka AI specializes in delivering.
Claude Opus 4.5 Takes Coding Crown, Dethroning Google and OpenAI Rivals
The New King of Code
The race for AI dominance has a new leader. Anthropic has officially released Claude Opus 4.5, a model that claims the "coding crown" by outperforming all current frontier models on real-world software engineering tasks.
Available immediately via API and cloud platforms, Opus 4.5 isn't just an incremental update. It introduces significant efficiencies, scoring higher on benchmarks while using fewer tokens than its predecessor, Sonnet 4.5. For AI engineers and technical leads, this release signals a shift toward more capable, autonomous, and cost-effective AI agents.
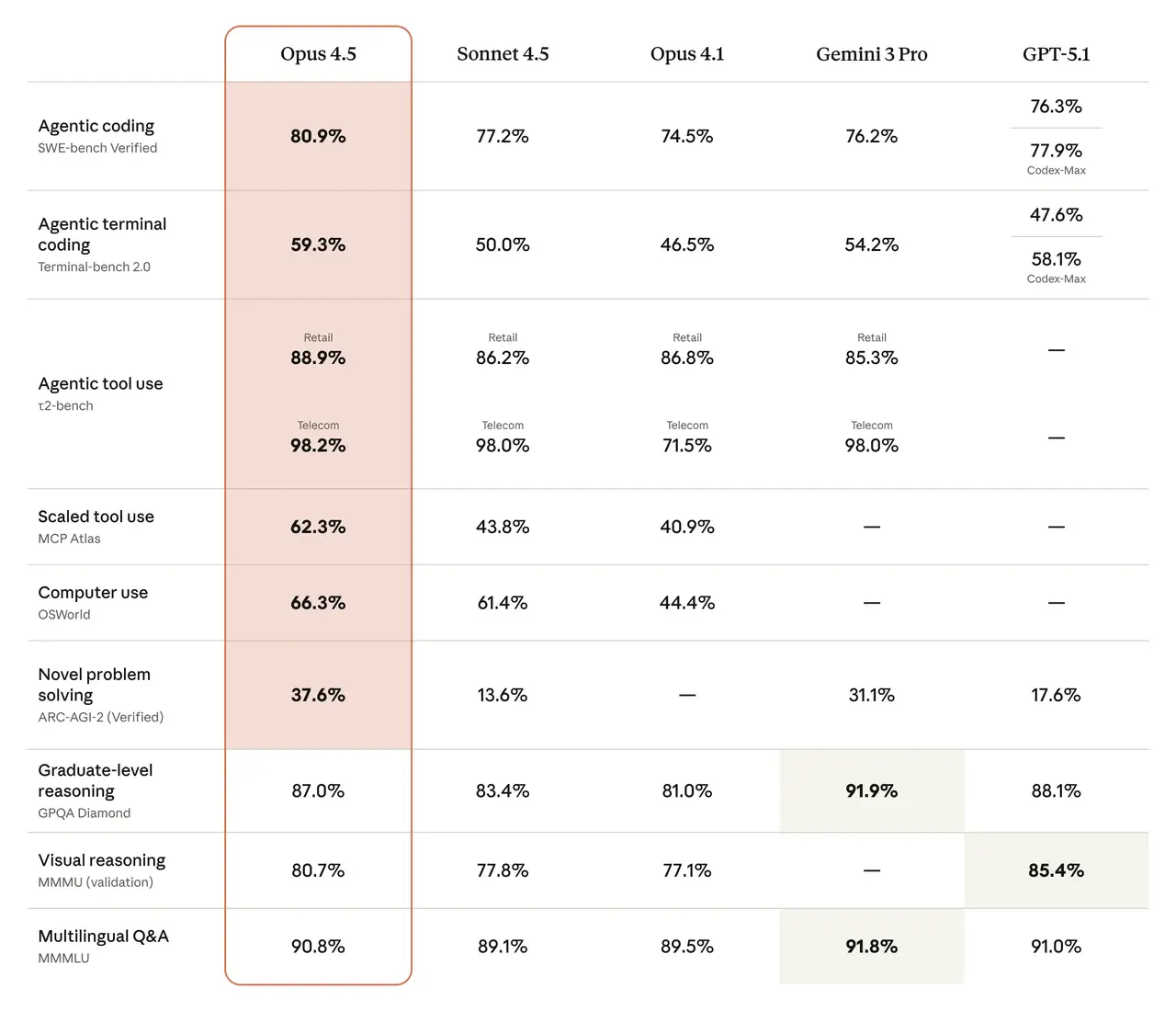
Claude Opus 4.5
Shattering Benchmarks: Opus 4.5 vs. The World
The standout achievement of Opus 4.5 is its performance on SWE-bench Verified, the industry standard for evaluating an AI's ability to solve real-world GitHub issues. As shown in the comparison below, Opus 4.5 establishes a clear lead over its top-tier competitors.
Claude Opus 4.5 achieves SOTA performance on a series of benchmark
SOTA: Opus 4.5 achieves the highest score on SWE-bench Verified, effectively "dethroning" major competitors like Google's Gemini and OpenAI's GPT series in coding proficiency.
Multilingual Mastery: On SWE-bench Multilingual, Opus 4.5 leads across 7 out of 8 programming languages, proving its versatility in global development environments.
Human-Level Competence: In internal testing, Opus 4.5 scored higher than any human candidate ever on Anthropic's own notoriously difficult performance engineering take-home exam.
These coding capabilities are supported by broad improvements across other domains. The table below details Opus 4.5's performance against other frontier models on a wide range of popular benchmarks.
Beyond Code: Agentic Reasoning and "Creative" Problem Solving
Opus 4.5's advancements go beyond syntax. It demonstrates a leap in agentic reasoning—the ability to handle ambiguity, manage tradeoffs, and navigate complex, multi-turn tasks without hand-holding.
A prime example comes from the τ2-bench (agentic capabilities benchmark). In a scenario requiring an airline agent to modify a basic economy ticket (which is technically non-modifiable), Opus 4.5 didn't just fail or refuse. It found a legitimate policy loophole: upgrade the cabin first, then modify the flight. This level of creative, goal-oriented problem solving mimics high-level human intuition.
Deploying Opus 4.5? You Need the Right Data Foundation
The release of Claude Opus 4.5 provides a powerful engine for building autonomous coding agents, complex reasoning systems, and next-gen applications. But as models become more capable, the quality of the data they interact with becomes the bottleneck.
To truly leverage Opus 4.5's capabilities for your specific use case—whether it's fine-tuning for proprietary codebases or evaluating its performance on niche tasks—you need a partner who understands the data lifecycle.
This is where Abaka AI comes in.
We help forward-thinking engineering teams unlock the full potential of frontier models like Opus 4.5 through:
Expert Code Annotation: High-fidelity, human-verified code datasets to fine-tune models for your specific tech stack.
Agent Trajectory Data: Curated datasets of multi-turn agent interactions to train models in complex reasoning and tool use.
Rigorous Model Evaluation: Independent benchmarking of Opus 4.5 against your internal metrics to ensure reliability and safety before deployment.
Don't just use the best model—build the best system. Contact Abaka AI for Data Solutions
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.