

データラベリングとは何か?
💡データラベリング(アノテーションとも呼ばれる)とは、生データに明確なタグまたはラベルを付けてAIが学習できるようにする作業です。データラベリングの品質は、あらゆるAIプロジェクトの信頼性を決定します。Abaka AIは、スケーラブルな専門チームと多段階の品質保証により、高速かつ正確で一貫性のあるラベリングを実現しています。
人工知能と機械学習の時代において、データは王様です。しかし、未処理の生データだけではしばしば不十分です。AIモデルが学習し、理解し、正確な予測を行うためには、組織化されたコンテキスト豊かな情報が必要です。ここでデータラベリングの役割が重要になります。
データラベリング(データアノテーションとも呼ばれます)は、生データ(画像、テキスト、オーディオ、ビデオなど)に意味のあるラベルを付けてタグ付け、分類、または注釈を付けるプロセスであり、機械学習モデルにコンテキストを提供します。AIに例を示して明確な説明を与えて教えるようなものだと考えてください。たとえば、画像では「猫」や「車」をすべてラベル付けすることで、AIが独立してそれらを識別できるように学習させることができます。この細心の注意を払って準備されたデータは、アルゴリズムの訓練場として機能し、パターンを認識し、決定を下し、タスクを効果的に実行できるようにします。
データラベリングの仕組み
データラベリングプロセスには通常、いくつかの主なステップが含まれます:
- データ収集:特定のAIプロジェクトに必要な生データを収集する。
- ツール選択:単純な手動プラットフォームから高度なAI支援システムまで、適切なアノテーションツールを選択する。
- アノテーションガイドライン:データセット全体で一貫性と正確性を確保するために、アノテーターに明確で正確かつ包括的なガイドラインを作成する。これは品質確保のための重要なステップです。
- アノテーション実行:人間のアノテーター(または時にはAI支援ツール)が、ガイドラインに従ってデータに事前定義されたラベルを付ける。
- 品質保証(QA):注釈付けされたデータをレビューしてエラーを特定し修正し、高い正確性とガイドラインへの準拠を確保する。これには多くの場合複数回のレビューが含まれます。
- データエクスポート:機械学習モデルの訓練に適した形式でラベル付けされたデータを準備する。
AIプロジェクトの成功は、この注釈付けされたデータの品質に大きく依存します。不適切にラベル付けされたデータは、偏ったモデル、不正確な予測を引き起こし、最終的にはプロジェクトの失敗につながる可能性があります。
データラベリングの一般的な種類は何か?
データラベリングにはさまざまな技術があり、それぞれが異なるデータ型とAIアプリケーションに適しています:
- 画像アノテーション:
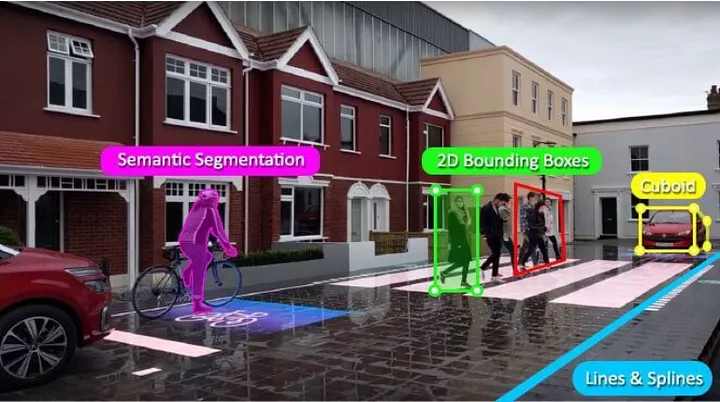
- 境界ボックス:オブジェクトの周りに長方形のボックスを描画する。
- 多角形:不規則な形状を正確に輪郭で描く。
- セマンティックセグメンテーション:オブジェクトのピクセルレベルの分類。
- キーポイントアノテーション:オブジェクト上の特定の点(顔の特徴、人間の関節など)をマークする。
- テキストアノテーション:
- 感情分析:テキストを肯定的、否定的、または中立的としてラベル付けする。
- 固有表現抽出(NER):主要なエンティティ(人、組織、場所)を識別し分類する。
- テキスト分類:文書または文を事前定義されたクラスに分類する。
- オーディオアノテーション:音声をテキストに文字起こししたり、音声イベント(車のクラクション、ガラスの割れる音など)を識別したり、話者分離を行ったりする。
- ビデオアノテーション:画像アノテーションに似ていますが、フレームごとにまたはシーケンス全体に適用され、時間経過に伴うオブジェクトとアクションの追跡を可能にします。
- LiDARアノテーション:自律走行車に不可欠な3D点群データにラベルを付ける。
それぞれのアノテーションタイプには、正確で価値のある結果を得るために特定の専門知識とツールが必要です。
データラベリングのベストプラクティスは何か?
AIモデルのための最高品質のデータを確保するには、次のベストプラクティスを考慮してください:
- 明確なガイドライン:すべてのアノテーターがアクセスできる明確であいまいさのない詳細なアノテーションガイドラインを作成する。
- アノテーターの訓練:プロジェクトの特定の要件とツールについてアノテーターを徹底的に訓練する。
- 品質管理メカニズム:コンセンサスメカニズム、ピアレビュー、ランダムサンプリングを含む堅牢なQAプロセスを実装する。
- 反復的なフィードバックループ:アノテーターからのフィードバックとモデルのパフォーマンスを継続的に収集し、ガイドラインを改良しデータ品質を向上させる。
- データセキュリティとプライバシー:すべてのデータ処理が関連するプライバシー規制(GDPR、CCPAなど)に準拠していることを確保する。
- スケーラビリティ計画:プロジェクトが拡大するにつれてデータラベリングのニーズがどのように成長するかを計画する。
これらの慣行に従うことは、強靭で高性能なAIシステムを構築するために重要です。
データラベリングを効率的に完了する方法は何か?
効率的なデータラベリングとは、速度、コスト、そして最も重要な品質のバランスをとることです。手動ラベリングは正確ですが、大規模なデータセットの場合、時間がかかり費用が高くなる可能性があります。効率化のための戦略には以下が含まれます:
- AI支援ツールの活用:アクティブラーニング、事前ラベリング、またはスマートサンプリングを使用して人間の労力を削減する。
- 効果的なワークフロー管理:データ取り込みからQA、エクスポートまでのアノテーションパイプラインを合理化する。
- 専門チーム:複雑な理解が必要な場合には、ドメイン固有の知識を持つアノテーターを活用する。
- 明確なコミュニケーション:プロジェクトマネージャー、アノテーター、QAチーム間の継続的なコミュニケーションを確保する。
- 専門家とのパートナーシップ:確立されたプロセスと熟練した労働力を持つプロフェッショナルなデータラベリングサービスと協力する。
効率性は決して品質を犠牲にしてはなりません。データラベリングの小さなエラーでもAIモデルに伝播し、最終的には重大な不正確さにつながる可能性があるからです。
Abaka AIはどのようにデータアノテーションの要件を満たしていますか?
Abaka AIでは、高品質で保証された効率的なデータラベリングが、成功したAI導入の基盤であることを理解しています。私たちは、現代的な機械学習プロジェクトの厳しい要求を満たすように設計された包括的なデータアノテーションサービスを提供することに特化しています。
Abaka AIの特長:
- 高品質保証:コンセンサスに基づくラベリング、専門家によるレビュー、専任のQAチームを含む多段階の品質保証(QA)プロトコルを実装しています。私たちの細心のアプローチにより、ラベル付けされたデータは高精度で一貫性があり、モデルの性能に影響を与える可能性のあるエラーを最小限に抑えます。
- 保証された正確性と信頼性:堅牢なプロセスと経験豊富なアノテーターにより、比類のない信頼性を提供できます。正確性に関する明確なサービスレベル契約(SLA)を確立するために緊密に協力し、データ基盤が堅牢で信頼できることを保証します。お客様の成功が私たちの保証です。
- 高効率ワークフロー:熟練した人間のアノテーターと最先端のAI支援ツールを組み合わせることで、精度を犠牲にすることなくラベリングパイプラインを速度最適化しています。柔軟な労働力により、あらゆる規模のプロジェクトに迅速に対応し、膨大なデータセットでもタイムリーな配送を保証します。これにより、開発サイクルが短縮され、AIソリューションを早く市場に投入することができます。
- 多様なアノテーション専門知識:コンピュータビジョンのための複雑な画像セグメンテーションから、微妙な自然言語処理(NLP)アノテーション、複雑なLiDARデータラベリングまで、私たちのチームは事実上あらゆるデータ型とプロジェクトの複雑さに対応できる多様なスキルとドメイン知識を備えています。
- カスタマイズされたソリューション:一括りに対応する考え方はありません。個々のプロジェクト要件を理解するために緊密に協力し、特定のAIモデルのニーズに合わせた独自のアノテーションガイドラインとワークフローを開発します。
一貫性がない、または低品質のデータがAIイノベーションを妨げることのないようにしましょう。Abaka AIとパートナーシップを結び、モデルが成功するために必要な正確で信頼できる効率的にラベル付けされたデータセットを確保してください。今日すぐお問い合わせいただき、信頼できるデータによってAIの旅を加速させる方法についてご相談ください。