

身体化された知能データセットに関する最も包括的な共有:グローバルに利用可能な高品質の身体化された知能データセット
2024年があっという間に過ぎ去り、人工知能はモデル、計算能力、データのレベルで開花し、仮想的な相互作用から物理的な実装へと徐々に進化しています。大規模モデルとロボット技術の進歩に伴い、身体化AIは人工知能システムに物理的な形態を与え、環境との相互作用と学習を可能にしました。モーションプログラミングから人間の遠隔操作、ロボットアームから器用な手、そしてシリコンバレーから中国まで、身体化AIはソフトウェアとハードウェアの両方のレベルで徐々に開発パラダイムを確立してきました。
自動運転車の開発パスから教訓を得て、データは身体化AIにとっても同様に重要です。データは、エージェントが環境を認識し理解するための「燃料」として機能するだけでなく、マルチモーダルセンサー(視覚、聴覚、触覚など)を通じて環境モデルを構築し、変化を予測するのにも役立ちます。これにより、エージェントは履歴データに基づいて状況認識と予測メンテナンスを実行し、より良い意思決定を行うことができます。高品質で多様な知覚データセットを構築することは、不可欠な基礎的なタスクです。これらのデータセットは、アルゴリズムトレーニングのための豊富な資料を提供するだけでなく、身体化されたパフォーマンスを評価するためのベンチマークリファレンスとしても機能します。
Integer Smartは常に「人工知能業界のデータパートナー」になることを目指してきました。私たちが前進するにつれて、世界中で利用可能な高品質の身体化AIデータセットを見てみましょう。
| 身体化AIデータセット | 発行者 | リリース日 | デモ数 | シーンタスク | アクションスキル | 収集方法 |
|---|---|---|---|---|---|---|
| AgiBot World | Zhiyuan Roboticsなど | 2024年12月 | 100万以上 | 100種類以上 | 数百 | デュアルアームロボットと器用な手の遠隔操作 |
| Open X-Embodiment | Google DeepMindなど(21のグローバル機関) | 2023年1月 | 140万 | 311種類 | 527 | シングルアーム、デュアルアーム、四足歩行など(22のロボット形態) |
| DROID | スタンフォード大学など | 2024年3月 | 76K | 564種類 | 86 | シングルアームの遠隔操作 |
| RT-1 | Google DeepMind | 2022年12月 | 135K | 2種類 | 2 | シングルアームの遠隔操作 |
| BridgeData V2 | UCバークレーなど | 2023年9月 | 60K | 24種類 | 13 | シングルアームの遠隔操作とスクリプト化されたアクション |
| RoboSet | カーネギーメロン大学など | 2023年9月 | 98.5K | 38種類 | 12 | シングルアームの遠隔操作とスクリプト化されたアクション |
| BC-Z | Robotics at Google | 2022年2月 | 26K | 1種類 | 12 | シングルアームの遠隔操作 |
| MIME | カーネギーメロン大学 | 2018年1月 | 8,260 | 1種類 | 20 | シングルアームの遠隔操作 |
| ARIO | Pengcheng Laboratoryなど | 2024年8月 | 300万 | 258種類 | 345 | マスター・スレーブデュアルアームロボットの遠隔操作 |
| RoboMIND | National Land Centerなど | 2024年12月 | 55K | 279種類 | 36 | シングルアーム、デュアルアーム、ヒューマノイドロボット、器用な手の遠隔操作 |
| RH20T | 上海交通大学 | 2023年7月 | 110K | 7種類 | 140 | シングルアームの遠隔操作 |
1. AgiBot World
- 発行者: Zhiyuan Robotics、上海AI研究所など
- リリース日: 2024年12月
- プロジェクトリンク:
- HuggingFace: https://huggingface.co/agibot-world
- Github: https://github.com/OpenDriveLab/agibot-world
- プロジェクトホームページ: https://agibot-world.com/
- データセットリンク: https://huggingface.co/datasets/agibot-world/AgiBotWorld-Alpha
- 説明: Zhiyuan Roboticsは、上海AI研究所、国家地方共同ヒューマノイドロボットイノベーションセンター、および上海Cooperasと共同で、AgiBot Worldプロジェクトを正式にオープンソース化しました。AgiBot Worldは、包括的な実世界シナリオ、多用途のハードウェアプラットフォーム、および全プロセス品質管理に基づく、世界初の百万規模の実世界データセットです。AgiBot Worldデータセットでカバーされているシナリオは多様で多面的であり、つかむ、置く、押す、引くなどの基本的な操作から、かき混ぜる、折りたたむ、アイロンをかけるなどの複雑なアクションまで、人間の日常生活に必要なほぼすべてのシナリオを網羅しています。
- 規模: 100台のロボットから100万を超えるデモンストレーショントラジェクトリが含まれています。長期的なデータ規模の点では、GoogleのOpenX-Embodimentデータセットを10倍上回っています。Googleがオープンソース化したOpen X-Embodimentデータセットと比較して、AgiBot Worldの長期的なデータ規模は10倍大きく、シナリオの範囲は100倍広く、データ品質は実験室グレードから産業グレードの基準に引き上げられています。

AgiBot World
- シナリオ: AgiBot Worldデータセットは、Zhiyuanが自社で構築した大規模なデータ収集工場と、総面積4,000平方メートルを超えるアプリケーション実験拠点で作成されました。3,000以上の実世界のアイテムが含まれています。一方では、大規模なロボットデータトレーニングの場を提供し、他方では、家庭、ダイニング、産業、商業、オフィスの5つのコアシナリオを正確に再現しています。これにより、生産と日常生活の両方におけるロボットの典型的なアプリケーションニーズを包括的にカバーしています。

多様なタスクの実演
- スキル: AgiBot Worldデータセットは、家庭(40%)、ダイニング(20%)、産業(20%)、オフィス(10%)、スーパーマーケット(10%)を含む数百の一般的なシナリオと、3,000以上の操作オブジェクトをカバーしています。海外で広く使用されているOpen X-EmbodimentおよびDROIDデータセットと比較して、AgiBot Worldデータセットはデータ期間の分布において大幅に改善されています。そのタスクのうち、80%は長期間のタスクであり、タスク期間は60秒から150秒の間に集中しています。また、複数のアトミックスキルも含まれており、長期間のデータはDROIDおよびOpenX-Embodimentの10倍以上です。3,000以上のアイテムは、基本的にこれら5つの主要なシナリオをカバーしています。
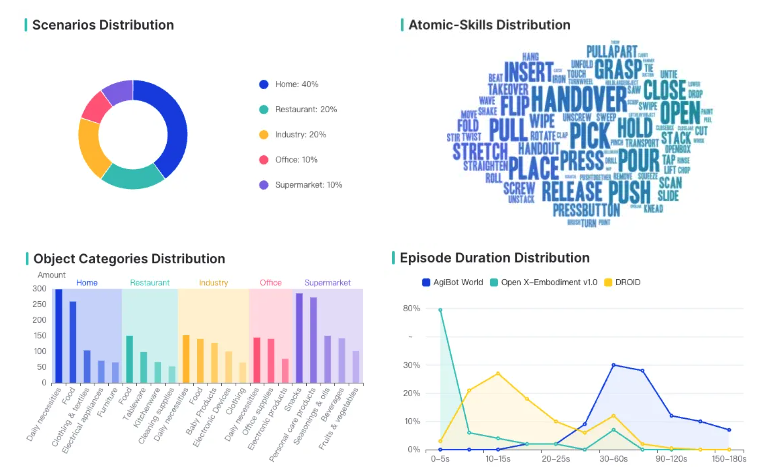
Agibot Worldデータセットの分布
- データ収集: AgiBot Worldは、完全に制御可能なモバイルデュアルアームロボットを使用して収集されたデータに基づいており、視覚触覚センサー、6次元力覚センサー、6自由度巧緻ハンドなどの高度なデバイスを搭載しています。このセットアップは、模倣学習とマルチエージェント協調の最先端の研究に適しています。Zhiyuan Genie-1ロボットには、リアルタイムの360度全方向知覚のための8台のサラウンドレイアウトカメラ、6次元力覚センサーと高精度触覚センサーを備えた6自由度巧緻ハンド、および全身で合計32の能動自由度が含まれています。
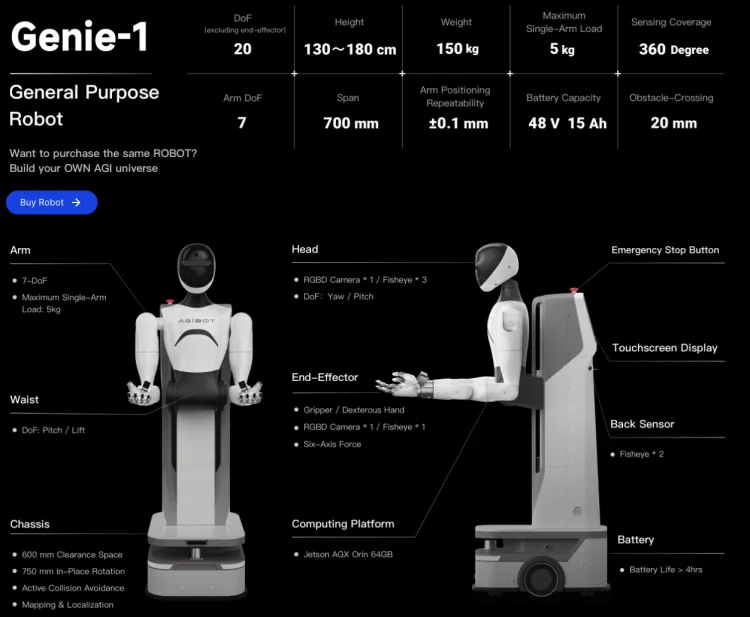
Zhiyuanロボット
2. Open X-Embodiment
- 発行者: Google DeepMindおよびその他21のグローバル機関
- リリース日: 2023年10月
- プロジェクトリンク: https://robotics-transformer-x.github.io/
- 論文リンク: https://arxiv.org/abs/2310.08864
- データセットリンク: https://github.com/google-deepmind/open_x_embodiment
- 説明: Open X-Embodimentは、Google DeepMindが34の研究室と21の国際的に有名な機関と共同で作成した、オープンで大規模な標準化されたロボット学習データセットです。60の既存のロボットデータセットを統合しています。Open X-Embodiment Datasetの研究者は、さまざまなソースからのデータセットを統一されたデータ形式に変換し、ユーザーが簡単にダウンロードして使用できるようにしました。各データセットは一連の「エピソード」として提示され、Googleが確立したRLDS形式を使用して記述されており、高い互換性と理解のしやすさを保証しています。
- 規模: シングルアームロボットからデュアルアームロボット、四足歩行ロボットまで、22種類のロボットをカバーし、100万を超えるロボットのデモンストレーショントラジェクトリ、311のシナリオ、527のスキル、160,266のタスクが含まれています。

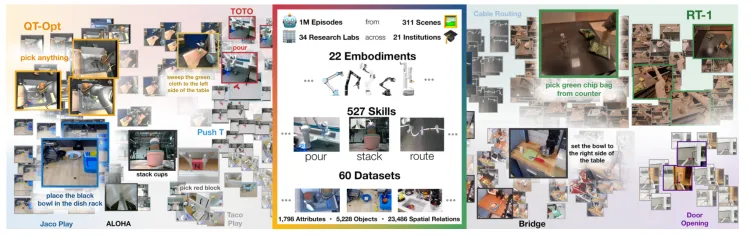
Open X-Embodiment:ロボット学習データセットとRT-Xモデル
- シナリオ: 研究者は、混合ロボットデータで2つのモデルをトレーニングしました。
- RT-1、ロボット制御専用に設計された効率的なTransformerベースのアーキテクチャ。
- RT-2、自然言語トークンとしてロボットのアクションを出力するように共同で微調整された大規模な視覚言語モデル。
両方のモデルは、ロボットのグリッパーフレームに対して相対的に表現されたロボットのアクションを出力します。ロボットのアクションは、x、y、z、ロール、ピッチ、ヨー、およびグリッパーの開口部、またはこれらの量の変化率で構成される7次元ベクトルです。ロボットが特定の次元を使用しないデータセットの場合、対応する次元の値はトレーニング中にゼロに設定されます。混合ロボットデータでトレーニングされたRT-1モデルはRT-1-Xと呼ばれ、混合ロボットデータでトレーニングされたRT-2モデルはRT-2-Xと呼ばれます。
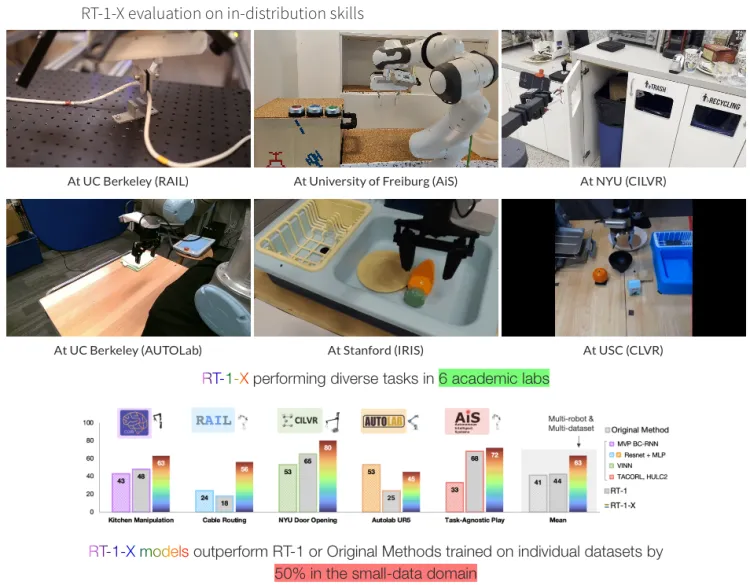
RT-1-Xは、小規模データの分野で、単一のデータセットまたは元の方法でトレーニングされたRT-1を50%上回っています。
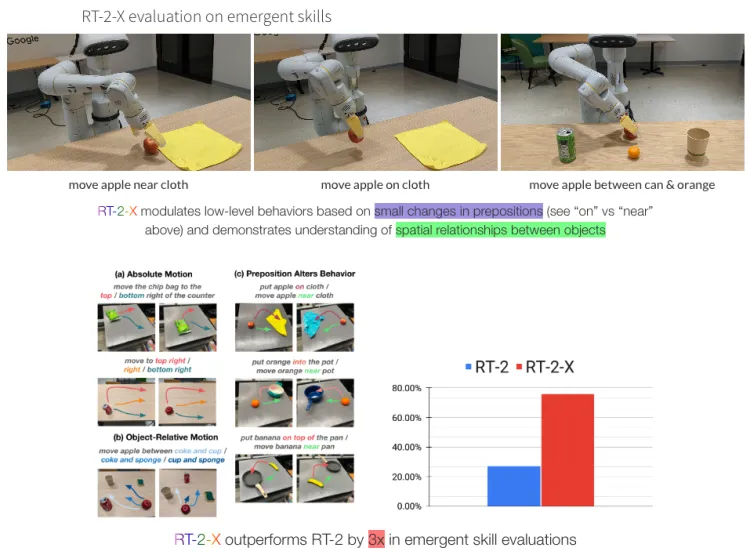
RT-2-Xは、新しいスキル評価でRT-2を3倍上回っています。
- スキル: データセットの一般的なタスクスキルには、ピッキング、移動、プッシュ、配置などが含まれます。タスクの目的には、形状、コンテナ、家具、食品、電化製品、調理器具などが含まれます。
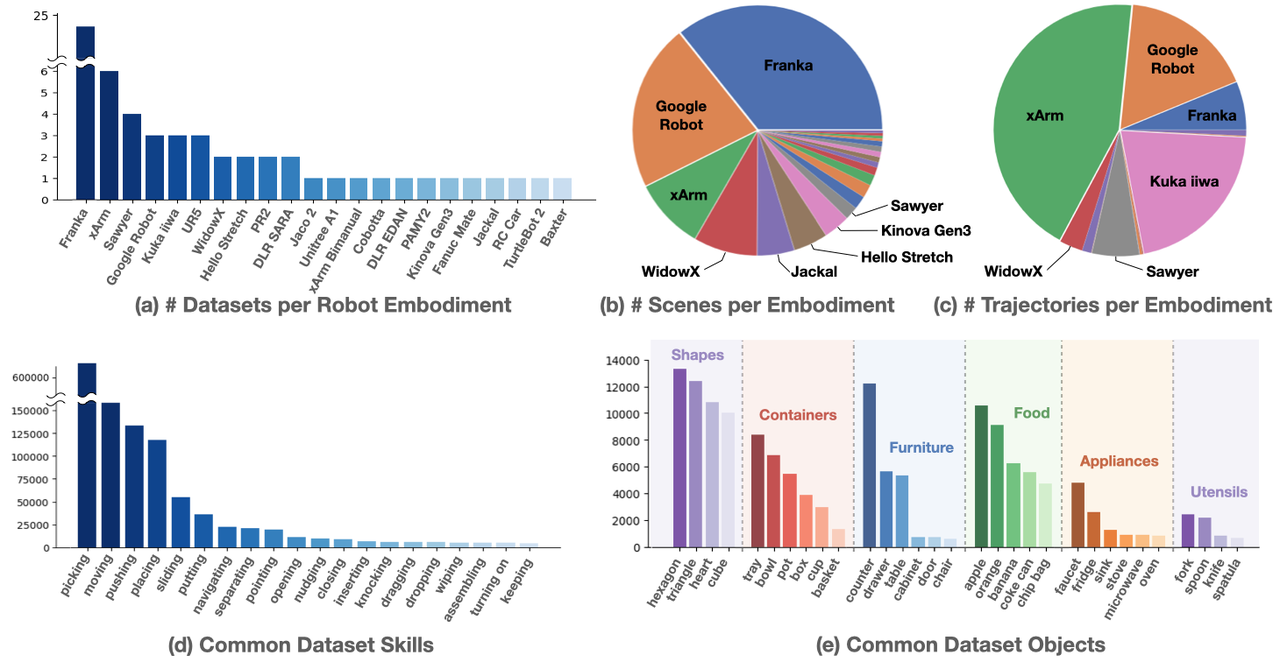
Open X-Embodimentスキル分布
- データ収集: シーン分布の観点から見ると、Frankaロボットが優勢であり、Google RobotとxArmがそれに続きます。軌道分布の観点から見ると、xArmが最も多くの軌道を提供しており、Google Robot、Franka、Kuka、iiwa、Sawyer、WidowXがそれに続きます。

Franka Robotics
3. DROID
- 発行者: スタンフォード大学、UCバークレー、トヨタ研究所など
- リリース日: 2024年3月
- プロジェクトリンク: https://droid-dataset.github.io/
- 論文リンク: https://arxiv.org/abs/2403.12945
- データセットリンク: https://droid-dataset.github.io/
- 説明: 大規模で多様で高品質なロボット操作データセットを作成することは、より強力で堅牢なロボット操作戦略を開発するための重要な基盤です。しかし、そのようなデータセットを作成することは困難です。多様な環境でロボット操作データを収集することは、ロジスティックおよび安全上の課題を提示し、かなりのハードウェアと人的資源を必要とします。研究者は、多様なロボット操作データセットであるDROID(Distributed Robot Interaction Dataset)を導入しました。研究によると、既存の大規模なロボット操作データセットを利用した最先端の方法と比較して、DROIDはポリシーのパフォーマンス、堅牢性、および一般化を平均20%向上させます。
- 規模: DROIDデータセットは1.7TBのデータで構成されており、76,000のロボットデモンストレーショントラジェクトリが含まれ、86のタスクと564のシナリオをカバーしています。

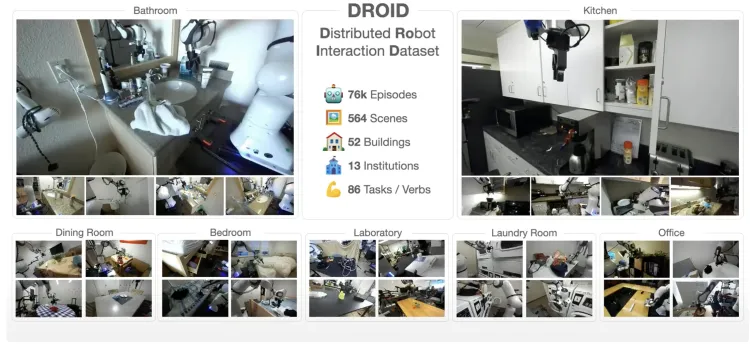
DROID:大規模な実環境ロボット操作データセット
- シナリオ: データセットは、産業用オフィス、家庭のキッチン、産業用キッチン、オフィス、リビングルーム、廊下/クローゼット、寝室、ダイニングルーム、バスルーム、ランドリールームなど、564のデモンストレーションシナリオをカバーしています。

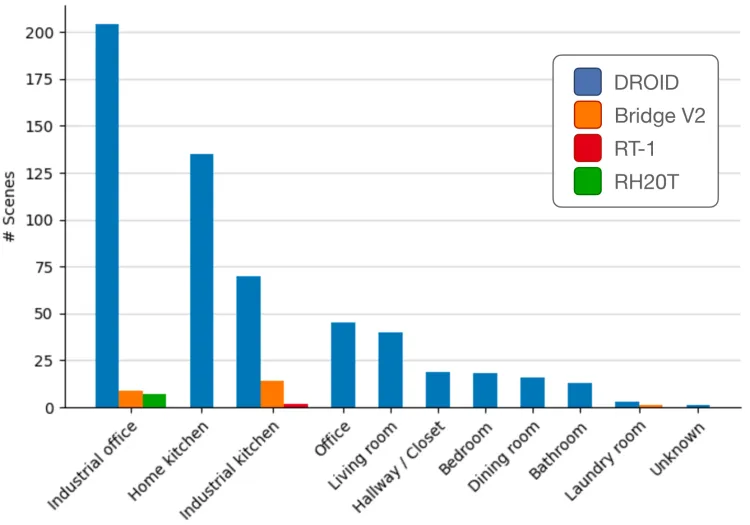
Oroidデータセットのシーン分布
- スキル: DROIDデータセットには86のアクションタスクが含まれており、以前のデータセットと比較して、より広範なシナリオタイプと、大幅に多くのロングテールタスク分布をカバーしています。
Oroidデータセットのスキル分布
- データ収集: DROIDは、13のすべての機関で同じハードウェア設定を使用し、データ収集を簡素化しながら、携帯性と柔軟性を最大限に高めています。この設定には、Franka Panda 7DoFロボットアーム、2台の調整可能なZed 2ステレオカメラ、手首に取り付けられたZed Miniステレオカメラ、および遠隔操作用のコントローラー付きOculus Quest 2ヘッドセットが含まれます。すべての機器は、迅速なシーン切り替えのために、携帯可能で高さ調整可能なテーブルに取り付けられています。
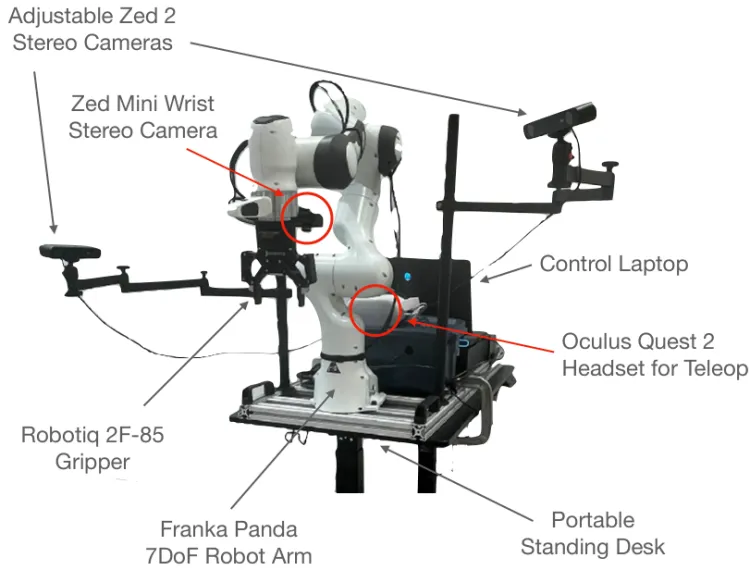
Droidデータ収集デバイス
4. RT-2/RT-1
- 発行者: Google DeepMind
- リリース日: 2022年12月
- プロジェクトリンク: https://robotics-transformer2.github.io/
- 論文リンク: https://robotics-transformer2.github.io/assets/rt2.pdf
- データセットリンク: https://github.com/google-research/robotics_transformer
- 説明: 2022年、Google DeepMindの研究チームは、大規模な実世界のロボットデータセットと、マルチタスクモデルRT-1:Robotics Transformerを発表しました。2023年7月、研究者はRT-2:Vision-Language-Action Models(VLA)を提案しました。
- 規模: RT-2データセットは、主に2つの主要なコンポーネントで構成されています。1つ目は、109の言語をカバーする約100億の画像とテキストのペアを含むWebLI視覚言語データセットで、10億のトレーニングサンプルにフィルタリングされています。2つ目のコンポーネントは、RT-1などのロボットデータセットです。RT-1は、7自由度のアーム、2本指のグリッパー、およびモバイルベースを備えた13台のEDRロボットアームを使用して、17か月にわたって130,000のエピソードを収集しました。総データ量は111.06GBに達しました。各エピソードには、ロボットの実際の行動記録だけでなく、対応する人間の指示テキスト注釈も含まれています。

RT-2:視覚言語行動モデルがWeb知識をロボット制御に転送
- シナリオとスキル: RT-2のシナリオは、主に家庭やキッチンなどの環境に焦点を当てており、家具、食品、調理器具などのアイテムが含まれます。スキルは、主にピックアンドプレースなどの一般的な操作と、拭き取りや組み立てなどのより困難なスキルが含まれます。タスクは、オブジェクトのピックアップと配置から、引き出しの開閉、細いオブジェクトの取り扱い、オブジェクトの転倒、ナプキンの引き出し、缶の開封など、700種類以上の異なるオブジェクトを含むタスクまで多岐にわたります。

RT-2シーンタスク
- 研究の意義: RT-2は、RT-1の32%から62%へと、見慣れないシナリオでのパフォーマンスを向上させ、大規模な事前学習の大きな利点を示しています。VC-1やロボット操作のための再利用可能な表現(R3M)など、純粋に視覚的なタスクで事前学習されたベースラインや、Open-World Object Manipulation(MOO)など、オブジェクト認識にVLMを使用するアルゴリズムと比較して、大幅な改善を示しています。RT-2は、視覚言語モデル(VLM)が、VLMの事前学習とロボットデータを組み合わせることでロボットを直接制御できる強力な視覚言語行動(VLA)モデルに変換できることを示しています。
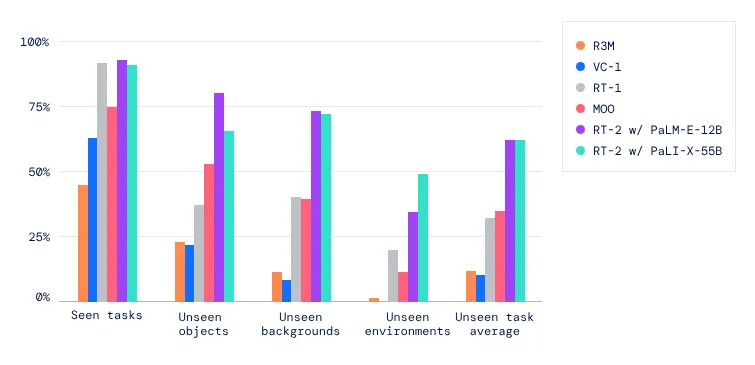
RT-2のパフォーマンス比較
5. BridgeData V2
- 発行者: UCバークレー、スタンフォード、Google DeepMind、CMU
- リリース日: 2023年9月
- プロジェクトリンク: https://rail-berkeley.github.io/bridgedata/
- 論文リンク: https://arxiv.org/abs/2308.12952
- データセットリンク: https://rail.eecs.berkeley.edu/datasets/bridge_release/data/
- 説明: BridgeData V2は、スケーラブルなロボット学習の研究を促進するために設計された、大規模で多様なロボット操作行動のデータセットです。このデータセットは、目標画像または自然言語の指示に基づいて条件付けされた、オープンボキャブラリ、マルチタスク学習手法と互換性があります。データから学習したスキルは、新しいオブジェクト、環境、および機関に一般化できます。
- 規模: BridgeData V2データセットには60,096の軌道が含まれており、そのうち50,365は遠隔操作によるデモンストレーション、9,731はスクリプト化されたピックアンドプレースポリシーによる展開です。

BridgeData V2:大規模なロボット学習のためのデータセット
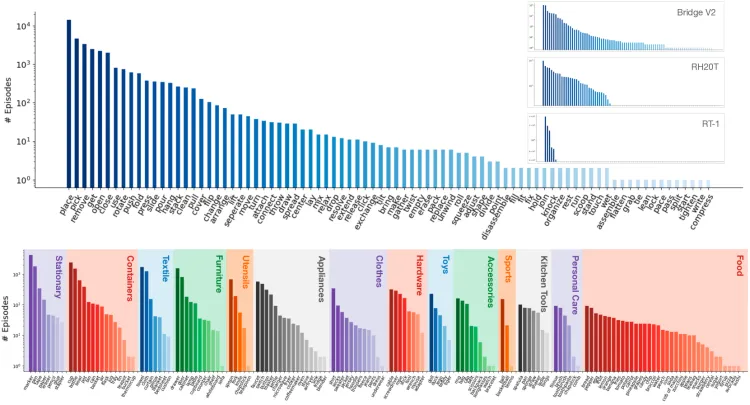
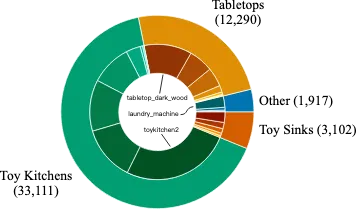
- シナリオ: BridgeData V2の24の環境は4つのカテゴリに分類されます。データのほとんどは、シンク、コンロ、電子レンジの組み合わせを含む7つの異なるおもちゃのキッチンセットアップからのものです。残りの環境は、さまざまなテーブルトップ、独立したおもちゃのシンク、おもちゃの洗濯機など、さまざまなソースからのものです。

BridgeData V2設定
- スキル: データの大部分は、ピッキングと配置、プッシュ、スイープなどの基本的なオブジェクト操作タスクからのものです。一部のデータは、ドアや引き出しの開閉などの環境操作からのものです。また、ブロックの積み重ね、布の折りたたみ、粒状媒体のスイープなどのより複雑なタスクからのものもあります。
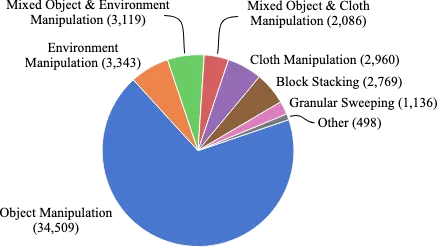
BridgeData V2スキル
- データ収集: データは、WidowX250 6-DOFロボットアームを使用して収集され、ロボットはVRコントローラーを使用して5Hzの制御周波数で遠隔操作されました。平均軌道長は38タイムステップです。センシングは、肩越しのビューに固定されたRGB-Dカメラ、データ収集中にランダムなポーズを持つ2台のRGBカメラ、およびロボットの手首に取り付けられたRGBカメラを使用して実行されました。画像は640x480の解像度で保存されました。
6. RoboSet
- 発行者: カーネギーメロン大学、FAIR-MetaAI
- リリース日: 2023年9月
- プロジェクトリンク: https://robopen.github.io/
- 論文リンク: https://arxiv.org/pdf/2309.01918.pdf
- データセットリンク: https://robopen.github.io/roboset/
- 説明: RoboAgentプロジェクトのRoboSetデータセットは、キッチン環境での一連の日常的な家庭活動から収集された、大規模で実世界のマルチタスクデータセットです。RoboSetは、運動感覚によるデモンストレーションと遠隔操作によるデモンストレーションで構成されています。このデータセットには、マルチタスク活動、フレームごとに4つの異なるカメラビュー、および各デモンストレーションのシーンバリエーションが含まれています。
- 規模: わずか7,500の軌道でトレーニングすることで、38のタスクにわたって12の操作スキルを発揮し、それらを数百の異なる未知のシナリオに一般化できる汎用RoboAgentを実証しています。

RoboAgent:セマンティック拡張とアクションチャンキングによるロボット操作における一般化と効率
- シナリオ: データセットは、主にお茶を入れる、パンを焼くなどの日常的なキッチン活動のシナリオに焦点を当てています。
- スキル: RoboSetは、38のタスクにわたる12の操作スキルをカバーしています。

- データ収集: データは、Robotiqグリッパーを装備したFranka-Emikaロボットを使用して、人間の遠隔操作によって収集されました。日常のキッチン活動はさまざまなサブタスクに分解され、これらのサブタスクの実行中に対応するロボットデータが記録されました。
7. BC-Z
- 発行者: Robotics at Google、X(The Moonshot Factory)、UCバークレー、スタンフォード大学
- リリース日: 2022年2月
- プロジェクトリンク: https://sites.google.com/view/bc-z/
- 論文リンク: https://arxiv.org/abs/2202.02005
- データセットリンク: https://www.kaggle.com/datasets/google/bc-z-robot
- 説明: 研究者たちは、ビジョンベースのロボットオペレーティングシステムが新しいタスクに一般化できるようにする方法を調査し、模倣学習の観点からこの課題に取り組みました。この目的のために、彼らはデモンストレーションや介入から学習でき、事前トレーニングされた自然言語埋め込みやタスクを実行する人間のビデオなど、タスクを伝えるさまざまな形式の情報に基づいて条件付けできる、インタラクティブで柔軟な模倣学習システムを開発しました。実際のロボットで100以上の異なるタスクにデータ収集を拡大したところ、研究者たちは、これらのタスクのロボットデモンストレーションを必要とせずに、システムが24の未知の操作タスクを平均成功率44%で実行できることを発見しました。
- 規模: 25,877の異なる操作タスクが含まれており、100の多様なタスクをカバーしています。

BC-Z:ロボット模倣学習によるゼロショットタスク一般化
- シナリオ:
- オブジェクトの位置のバリエーション
- 複数の場所でのデータ収集によるシーンの背景の変化
- ロボット間の微妙なハードウェアの違い
- オブジェクトインスタンスのバリエーション
- 複数の邪魔なオブジェクト
- 10Hzの非同期推論での閉ループ、RGBのみの視覚運動制御。エピソードあたり100を超える決定(つまり、スパースなRL目標にとって困難な長期タスク)になります。

BC-Zシーンタスク
8. MIME
- 発行者: カーネギーメロン大学ロボット工学研究所
- リリース日: 2018年10月
- 論文リンク: https://arxiv.org/abs/1810.07121
- 説明: ロボット学習と人工知能の分野では、ロボットが人間の行動を模倣して複雑なタスクを学習できるようにすることが重要な研究の方向性です。従来の学習方法は、複数のインタラクティブなアクションを必要とする複雑なタスクを扱う際に限界に直面します。Multiple Interactions Made Easy(MIME)プロジェクトは、ロボットの模倣学習を促進するために大規模なデモンストレーションデータを提供することを目的としています。人間の行動の豊富なデモンストレーションを収集することで、ロボットはさまざまなインタラクティブなアクションを学習し、それによって複雑なタスクをより適切に達成できます。MIMEプロジェクトは、複数のインタラクティブなアクションを含む大規模なデモンストレーションデータを提供することで、ロボット模倣学習の分野のギャップを埋めます。
- 規模: MIMEデータセットには、20以上の異なるロボットタスクにわたる8,260の人とロボットのデモンストレーションが含まれています。これらのタスクは、オブジェクトを押すなどの単純なタスクから、家庭用品を積み重ねるなどのより困難なタスクまで多岐にわたり、人間のデモンストレーションのビデオとロボットのデモンストレーションの運動学的軌道で構成されています。

Multiple Interactions Made Easy (MIME): Large Scale Demonstrations Data for Imitation
- スキル: MIMEは、デモンストレーションデータセットを収集するための先駆的な方法です。MIMEプロジェクトには、ロボット学習のための十分なサンプルを提供する大量のデモンストレーションデータが含まれています。豊富なサンプルサイズは、ロボットがさまざまな状況や行動パターンを学習するのに役立ち、汎化能力を高め、現実世界のシナリオで複雑で可変的なタスクをより適切に処理できるようにします。データセットは単純な行動に限定されず、さまざまなインタラクティブな行動をカバーしています。たとえば、家庭のシナリオでは、ロボットはオブジェクトのピックアップ、オブジェクトの配置、引き出しの開閉、引き出しへのアイテムの配置など、一連の一貫した行動を学習できます。この多様なインタラクティブな行動データにより、ロボットはタスクの順序と論理的な関係を理解できます。
Mimeアクションスキル
- データ収集: 重力補償された運動感覚モードのBaxterロボットが使用されました。Baxterは、2本指の平行グリッパーを備えた7-DOFアームを持つデュアルアームマニピュレーターです。さらに、ロボットには頭部にKinectが、両手首にSoftKinetic DS325カメラがそれぞれ取り付けられています。頭部カメラはテーブル上のタスクを観察する外部カメラとして機能し、手首カメラはロボットの目として機能し、腕とともに動きます。

ロボットデモンストレーションにおける複数のビュー
9. ARIO
- 発行者: Pengcheng Laboratory、南方科技大学、中山大学など
- リリース日: 2024年8月
- プロジェクトリンク: https://imaei.github.io/project_pages/ario/
- 論文リンク: https://arxiv.org/abs/2408.10899
- データセットリンク: https://openi.pcl.ac.cn/ARIO/ARIO_Dataset
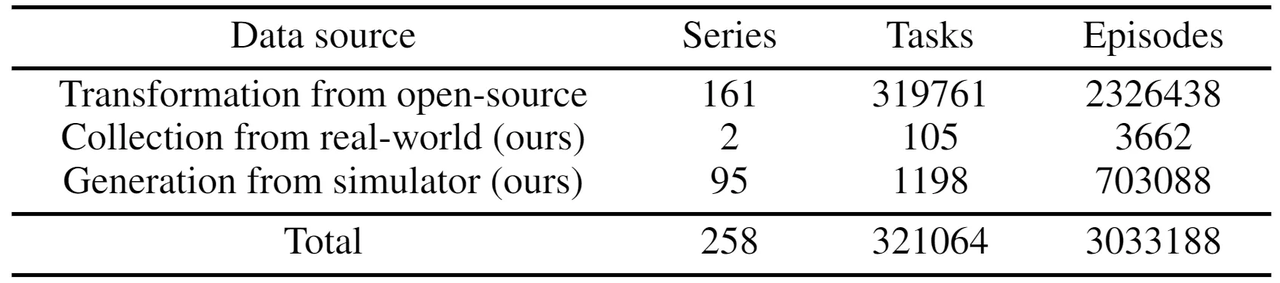
- 説明: ARIO(All Robots In One)身体化知能データオープンソースアライアンスは、Pengcheng Laboratory、AgileX Robotics、中山大学、南方科技大学、香港大学などの主要機関によって共同で設立されました。Pengcheng Laboratoryの身体化知能研究所は、まず身体化ビッグデータの一連のフォーマット標準を設計しました。これらの標準は、さまざまな形態のロボットの制御パラメータを記録でき、明確なデータ編成構造を備え、異なるフレームレートのセンサーと互換性があり、同時に対応するタイムスタンプを記録して、身体化知能モデルの知覚と制御タイミングの正確な要件を満たします。
- 規模: ARIOデータセットには、258のシナリオ、321,064のタスク、3,033,188のデモンストレーショントラジェクトリが含まれています。データモダリティは、2D画像、3D点群、音声、テキスト、および触覚データをカバーしています。データは主に3つのソースから得られます。
(1) 人間によって収集された実世界の環境設定とタスク。
(2) MuJoCoやHabitatなどのシミュレーションエンジンを使用して設計された仮想シーンとオブジェクトモデル、シミュレーションエンジンによって駆動されるロボットモデル。
(3) 既存のオープンソースの身体化データセットの分析と処理、それらをARIO形式標準に準拠するデータに変換。
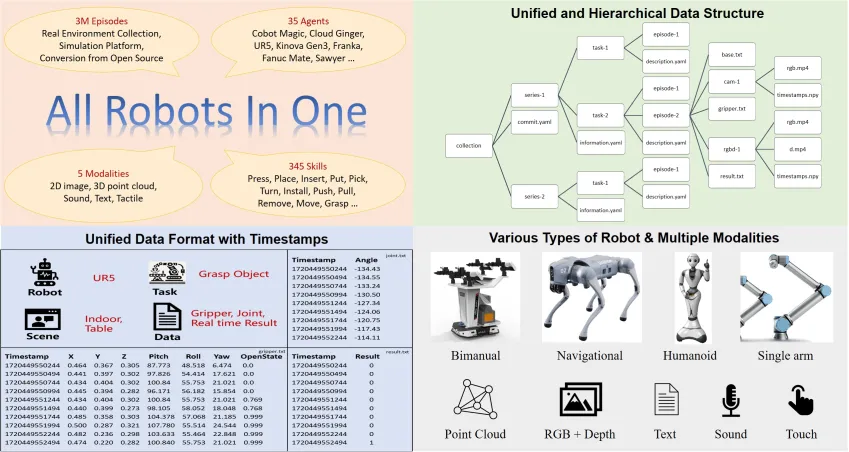
All Robots in One: A New Standard and Unified Dataset for Versatile, General-Purpose Embodied Agents
- シナリオとスキル: ARIOのシナリオは、デスクトップ、オープン環境、マルチルーム設定、キッチン、家事、廊下などをカバーしています。スキルには、ピック、プレース、プット、ムーブ、オープン、グラスプなどが含まれます。
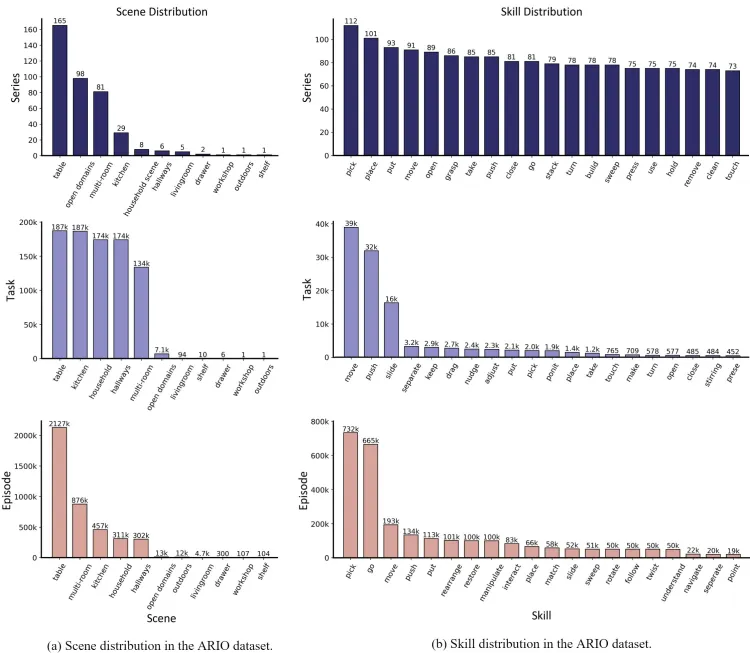
Arioデータセットのシナリオとスキル
- データ収集: AgileX Cobot Magicマスター・スレーブデュアルアームロボットプラットフォームに基づいて、実世界の環境でシーンとタスクが設定され、人間のデータ収集が行われました。30以上のタスクが設計され、操作の難易度に応じて単純、中程度、困難のレベルに分類されました。邪魔なオブジェクトを追加したり、オブジェクトとロボットの位置をランダムに変更したり、設定環境を変更したりすることで、多様性が高められました。最終的に、3台のRGB-Dカメラからのデータを含む3,000以上の軌道が収集されました。

Arioスキルタスク
10. RoboMIND
- 発行者: 国家地方共同ヒューマノイドロボットイノベーションセンター、北京大学、北京人工知能アカデミーなど
- リリース日: 2024年12月
- プロジェクトリンク: https://x-humanoid-robomind.github.io/
- 論文リンク: https://arxiv.org/abs/2412.13877
- データセットリンク: https://zitd5je6f7j.feishu.cn/share/base/form/shrcnOF6Ww4BuRWWtxljfs0aQqh
- 説明: RoboMINDは人間の遠隔操作によって収集され、多視点RGB-D画像、固有受容ロボット状態情報、エンドエフェクタの詳細、言語タスク記述など、包括的なロボット関連情報が含まれています。研究者は55,000の成功した輸送軌道を公開しただけでなく、5,000の実世界の失敗ケース軌道も記録しました。ロボットモデルは、これらの失敗軌道から学習することで失敗の原因を探求し、この学習経験を通じてパフォーマンスを向上させることができます。この技術は、人間の監督とフィードバックがモデルの学習プロセスを導き、より満足のいく正確な結果を生み出す、人間のフィードバックからの強化学習(RLHF)を表しています。
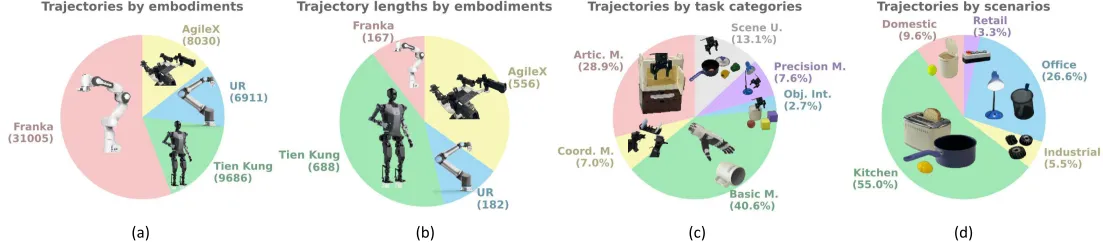
- 規模: RoboMINDデータセットには、4つの異なるロボットエンティティからのデータが含まれており、279のタスク、61の異なるオブジェクトカテゴリ、36の操作スキルにわたる合計55,000の軌道があります。

RoboMIND:ロボット操作のための多体知能規範データに関するベンチマーク
- シナリオ: RoboMINDには、家庭、産業、キッチン、オフィス、小売の5つの使用シナリオから60種類以上のオブジェクトタイプが含まれており、ほとんどの日常生活環境をカバーしています。
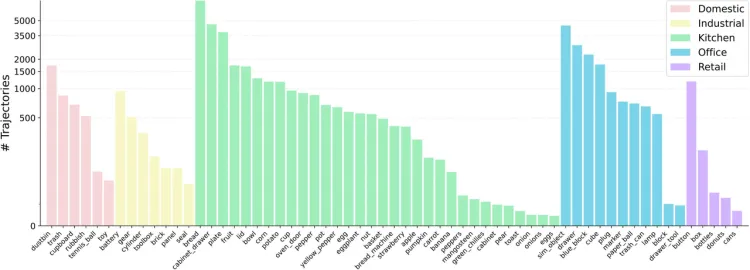
ロボマインドの5つの主要なシーン
- スキル: すべてのタスクは6つのタイプに分類されます。
- 関節操作(Artic. M.): 関節のあるオブジェクトを開閉、オン/オフする操作が含まれます。
- 協調操作(Coord. M.): ロボットの両腕の協調が必要です。
- 基本操作(Basic M.): 掴む、持つ、置くなどの基本的なスキルが含まれます。
- オブジェクトインタラクション(Obj. Int.): 1つのキューブを別のキューブの上に押すなど、複数のオブジェクトとのインタラクションが含まれます。
- 精密操作(Precision M.): オブジェクトを掴むのが難しい場合や、ターゲット領域が限られている場合に必要です。たとえば、カップに液体を注いだり、バッテリーを挿入したりする場合などです。
- シーン理解(Scene U.): 右側から上の引き出しを閉める、または4つの異なる色のブロックを対応する色の箱に入れるなど、シーンを理解するという主な課題に関連しています。
ロボマインドタスク分布
- データ収集: RoboMINDは、Franka Emika Pandaシングルアームロボットからの19,222の運動軌道、Tien Kungヒューマノイドロボットからの9,686の運動軌道、AgileX Cobot Magic V2.0デュアルアームロボットからの8,030の運動軌道、UR-5eシングルアームロボットからの6,911の運動軌道、およびシミュレーションからの11,783の運動軌道を含む、さまざまなロボットタイプからのデータを統合しています。

ロボマインドデータ収集
11. RH20T
- 発行者: 上海交通大学
- リリース日: 2023年7月
- プロジェクトリンク: https://rh20t.github.io/
- 論文リンク: https://arxiv.org/abs/2307.00595
- データセットリンク: https://rh20t.github.io/#download
- 説明: 研究者たちは、マルチモーダル知覚を通じて、エージェントが数百もの実世界のスキルを一般化する可能性を解き放つことを目指しています。これを達成するために、RH20Tプロジェクトは、11万を超える接触の多いロボット操作シーケンスを含むデータセットを収集しました。これらのシーケンスは、実世界のさまざまなスキル、シナリオ、ロボット、およびカメラの視点をカバーしています。データセットの各シーケンスには、視覚、力、音声、およびモーション情報、ならびにそれに対応する人間のデモンストレーションビデオが含まれています。
- 規模: RH20Tデータセットは、多様なスキル、環境、ロボット、カメラの視点を網羅しており、各タスクには数百万の<人間のデモンストレーション、ロボットの操作>ペアと、合計40TBを超えるデータ量が含まれています。データセットの各シーケンスには、視覚、力、音声、モーション情報、および対応する人間のデモンストレーションビデオが含まれています。

RH20T:ワンショットで多様なスキルを学習するための包括的なロボットデータセット
- スキル: 研究者たちは、RLBenchから48のタスク、MetaWorldから29のタスクを選択し、ロボットが頻繁に遭遇し、達成できる70の自己提案タスクを導入しました。

- データ収集: 3Dマウス、VRリモコン、または簡素化された遠隔操作インターフェースを使用する以前の方法とは異なり、このプロジェクトは、接触の多いロボット操作データを収集する際の直感的で正確な遠隔操作の重要性を強調しています。各プラットフォームには、トルクセンサー付きのロボットアーム、グリッパー、1〜2台のハンドヘルドカメラ、8〜10台のグローバルRGB-Dカメラ、およびデータ収集用の2つのマイクが含まれています。触覚デバイスとペダルを使用して、オペレーターは直感的にロボットを遠隔操作できます。すべてのデバイスはデータ収集ワークステーションに接続されています。

RH20Tデータ収集