
OpenAI o1 has emerged. Take a look at the open-source datasets available for training LLMs
OpenAI o1 Makes a Powerful Entrance
On September 12th local time, OpenAI officially released OpenAI o1. The newly named o1 series includes three model versions: OpenAI o1, OpenAI o1-preview, and OpenAI o1-mini. Compared to previous models, these versions are more capable of handling complex tasks in science, programming, and mathematics, as well as solving more challenging problems.
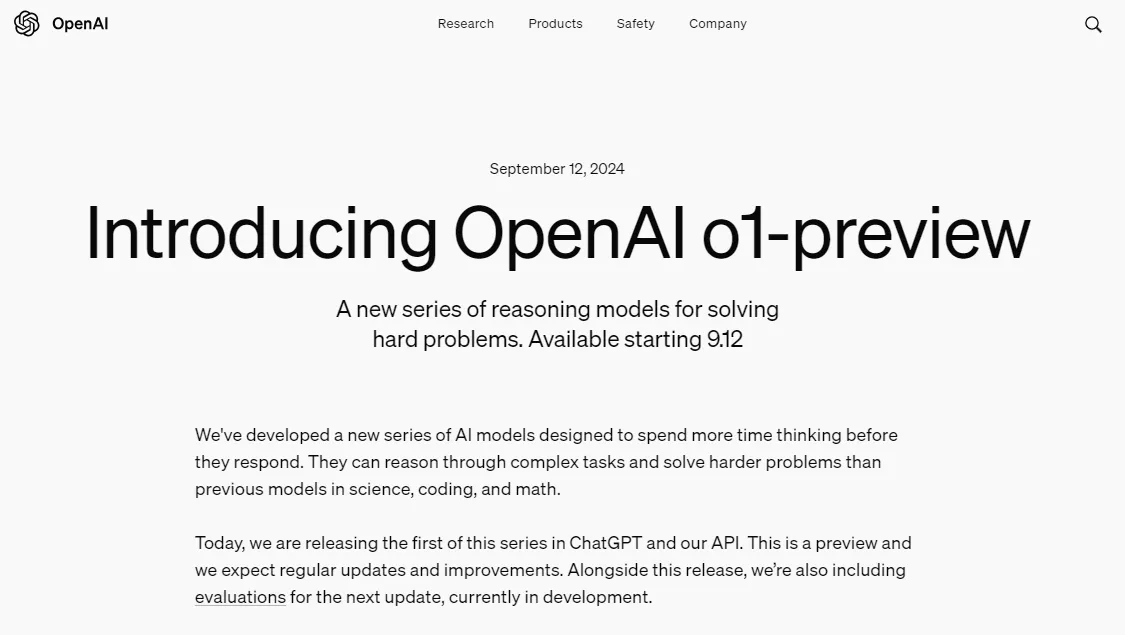
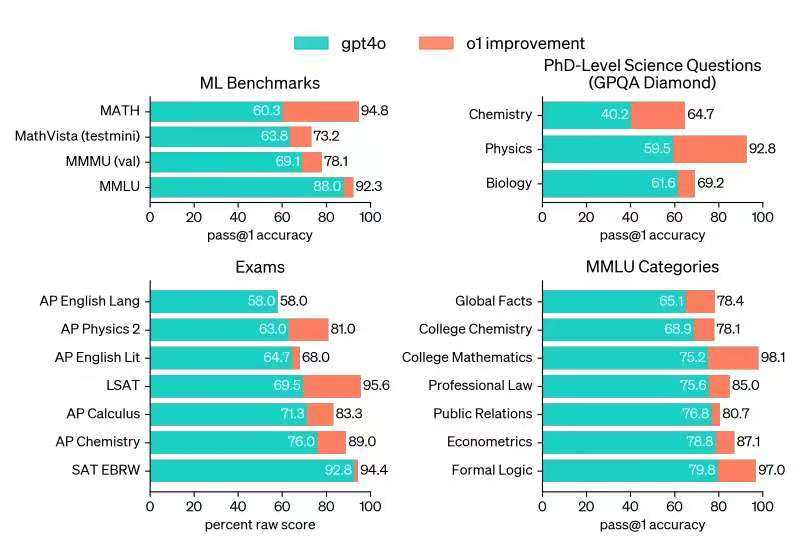
In OpenAI's tests, the new model performed at a level comparable to PhD students in challenging benchmark tasks in physics, chemistry, and biology. It excelled in mathematics and coding, achieving an accuracy rate of 83% in the International Mathematical Olympiad (IMO) qualification exam, reaching the 89th percentile in programming competition tests (Codeforces), and surpassing human experts with a 78% accuracy rate in PhD-level science problem tests.
Chain of Thought
OpenAI o1 is a new large language model (LLM) trained through reinforcement learning to perform complex reasoning. Previously, large models were often criticized for their inability to conduct structured reasoning, primarily because they relied on unstructured text data, which lacks strict logic and rules. This led to models being better at generating language rather than performing logical reasoning or adhering to fixed rules. To address this issue, OpenAI introduced the Chain of Thought (CoT) method. OpenAI o1 thinks before answering—it can generate a long internal chain of thought before responding to users. The o1 model has already demonstrated the ability to present chains of thought in fields such as cryptography, programming, mathematics, crosswords, English, science, safety, and health.

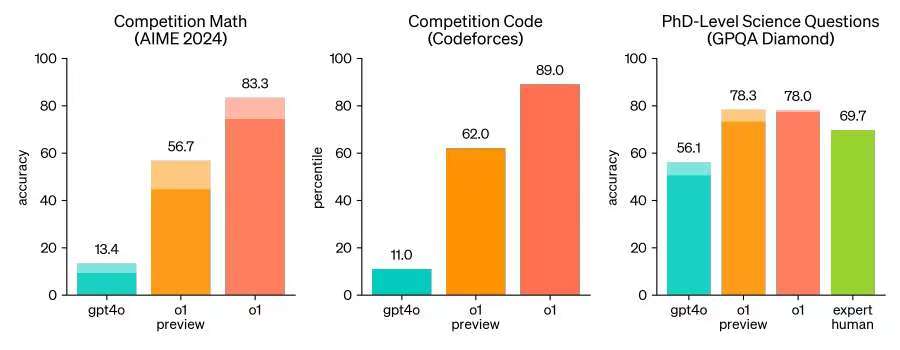
The thinking mode of OpenAI's previous models was System 1 (relying on intuitive experience for quick feedback), while the Chain of Thought (CoT) in the o1 model activates System 2 (taking time for logical reasoning). OpenAI employs large-scale reinforcement learning algorithms to train the o1 model on how to effectively utilize its chain of thought during highly efficient data training. The o1 model, like humans, spends more time thinking about problems before responding. Through training, the model learns to refine its thinking process, explore different strategies, and recognize its mistakes. Test results show that the accuracy rate of the o1 model in the American Invitational Mathematics Examination (AIME) continuously increases with the enhancement of reinforcement learning (training time) and thinking time (testing time). OpenAI has found that the limitations of scaling this method differ significantly from the limitations of LLM pretraining and will continue to research these constraints. This discovery adds a new dimension to the Scaling Law, indicating that model performance can be improved along two dimensions: the amount of reinforcement learning training resources and the thinking time of the chain of thought.

Taking the programming scenario as an example, OpenAI o1 brings more possibilities to programming. The model achieved a 49th percentile ranking with a score of 213 in the 2024 International Olympiad in Informatics (IOI). For each problem, the system samples many candidate submissions and selects 50 of them based on testing time strategies. If submissions were random, the average score would only be 156. OpenAI found that model performance significantly improved when submission limits were relaxed. When allowed 10,000 submissions per problem, even without any testing time selection strategy, the model achieved a score of 362.14, surpassing the gold medal threshold. OpenAI also simulated competitive programming contests hosted by Codeforces to demonstrate the model's coding skills. While GPT-4o ranked at the 11th percentile among human participants, the o1 model's Elo rating significantly improved to the 89th percentile and, after fine-tuning, outperformed 93% of human competitors.

Currently, the OpenAI o1 model can be accessed via the web version or API. For developers, using OpenAI o1 is quite expensive. In comparison, GPT-4o is priced at 5.00 per million tokens for input and 5.00 per million tokens for input and 15.00 per million tokens for output, while GPT-4o mini is priced at 0.15per million tokens for input and 0.15 per million tokens for input and 0.60 per million tokens for output. Additionally, the token consumption of the o1 model's chain-of-thought process is also counted as output tokens, meaning the output costs will be significantly higher.
OpenAI o1-preview is a new reasoning model designed for complex tasks requiring extensive commonsense knowledge. It features a 128K context window and knowledge up to October 2023, with the following pricing:
- Input: $15.00 per million tokens
- Output: $60.00 per million tokens
OpenAI o1-mini is a fast and cost-effective reasoning model specifically tailored for programming, mathematics, and science. It also features a 128K context window and knowledge up to October 2023, with the following pricing:
- Input: $3.00 per million tokens
- Output: $12.00 per million tokens
What Are the Open-Source Code Datasets in the Field of Large Models?
The powerful reasoning capabilities of OpenAI o1 signal the beginning of a new arms race in large models. The o1 model's ability to handle complex tasks in science, programming, and mathematics suggests that coding ability will become a critical factor in evaluating the quality of large models. Improving model capabilities requires highly effective datasets as a training foundation, as the quantity and quality of datasets significantly influence the training of large-scale reinforcement learning algorithms.
In our previous technical article, we introduced a series of open-source math datasets aimed at enhancing the mathematical abilities of large models. This time, we turn our attention to another equally important area: the coding capabilities of models. Code datasets need to cover different programming languages and paradigms, as well as include tasks of varying difficulty and types, to comprehensively evaluate and improve the logical reasoning abilities of models.
Below, we will introduce some widely used open-source code datasets for training and evaluating the coding capabilities of large models.
Human-eval
https://github.com/openai/human-eval
The HumanEval dataset is a benchmark test set developed by OpenAI to evaluate the capabilities of code generation models. This dataset contains 164 original Python programming problems, each of which includes a function signature, a docstring (describing the function's purpose), a runnable test case, and a canonical reference implementation.
HumanEval provides high-quality, diverse programming tasks and is primarily used for rigorous evaluation of the functional completeness and correctness of code generation models. HumanEval employs the "pass@k" metric to evaluate models, which measures the probability that at least one of the k candidate solutions generated by the model passes all test cases. This evaluation method is closer to real-world programming scenarios, as it considers that the code must be fully functionally correct, not just seemingly reasonable.
CodeSearchNet
https://github.com/github/CodeSearchNet
The CodeSearchNet dataset is a large-scale benchmark dataset designed to evaluate code search and comprehension capabilities. This dataset contains millions of lines of code and associated natural language descriptions sourced from GitHub, covering multiple programming languages such as Python, JavaScript, Go, Java, PHP, and Ruby.
The defining feature of CodeSearchNet is its provision of a vast number of code-documentation pairs, each consisting of a code snippet and its corresponding docstring or comments.
CodeSearchNet supports the diagnosis of current code search and comprehension models' capabilities and drives progress in related research. Through CodeSearchNet, researchers can test and improve model performance in tasks such as code retrieval, code-natural language matching, and code understanding. Particularly in scenarios requiring a deep understanding of the relationship between code semantics and natural language descriptions, CodeSearchNet serves as an effective benchmark for evaluating and enhancing model performance.
CodeXGLUE
https://github.com/microsoft/CodeXGLUE
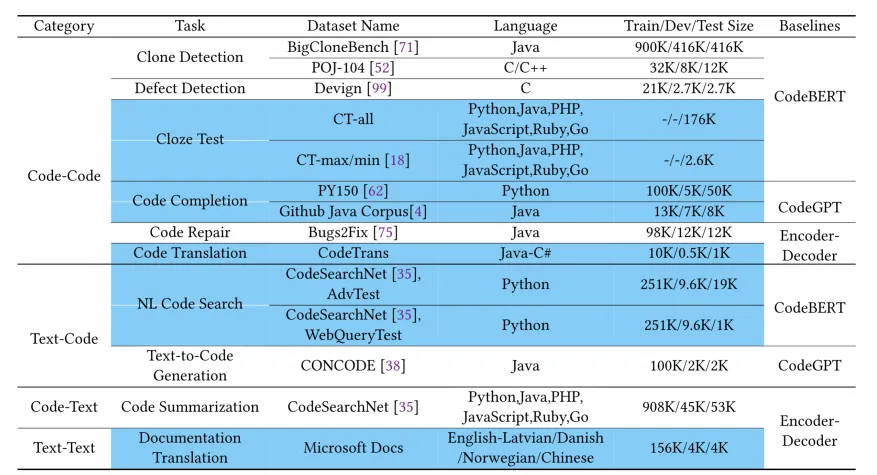
The CodeXGLUE dataset is a comprehensive code intelligence benchmark developed by Microsoft Research. This dataset includes 10 different code intelligence tasks, covering four major categories: code-to-code, text-to-code, code-to-text, and code-to-execution. Each task comes with specific datasets, evaluation metrics, and baseline model implementations. The defining feature of CodeXGLUE is its provision of a multilingual, multitask evaluation framework, encompassing a variety of common code intelligence applications, from code clone detection to code generation.
The uniqueness of CodeXGLUE lies in its offering of a unified evaluation framework, enabling direct performance comparisons between different models. Additionally, its multitask-nature allows researchers to assess the generalization and transfer learning capabilities of models.
Project_CodeNet
https://github.com/IBM/Project\_CodeNet
Project CodeNet is a large-scale, versatile dataset developed by IBM Research to advance AI research and applications in the field of code intelligence. It contains over 14 million code samples, covering 55 programming languages, with a total of approximately 500 million lines of code.
The dataset provides a vast number of problem-solution pairs, with multiple solutions for each problem, along with rich metadata. Its primary applications include:
- Code similarity analysis
- Code translation
- Code completion and generation
- Program repair
- Computational complexity estimation
As a comprehensive benchmark, Project CodeNet enables the evaluation and improvement of model performance across various code intelligence tasks, particularly in understanding code structure, semantics, and cross-language equivalence.
the-stack-v2
https://huggingface.co/datasets/bigcode/the-stack-v2
The Stack v2 is a large-scale multilingual code dataset developed by the BigCode project. It contains open-source code from GitHub, covering over 358 programming languages, with a total of approximately 4.5 TB of data and 215 billion tokens, making it one of the largest publicly available code datasets.
This dataset is primarily used to support the training and research of large-scale language models in the field of code, including:
- Training specialized code understanding and generation models
- Researching multilingual code representation and transfer learning
- Developing tools for code completion, search, and translation
- Exploring code structure and programming patterns
- Researching code annotation and documentation generation
The uniqueness of The Stack v2 lies in the diversity and scale of its data, which includes not only common programming languages but also many less common ones, providing valuable resources for cross-language code understanding research. It effectively evaluates and improves models' capabilities in handling multiple programming languages and understanding complex code structures and semantics.
mbpp
https://huggingface.co/datasets/google-research-datasets/mbpp
MBPP is a Python programming problem set developed by Google Research, containing 974 original problems, each accompanied by a description, solution code, and test cases. It focuses on basic to intermediate Python programming tasks, covering a variety of programming concepts and algorithms.
This dataset is primarily used to evaluate code generation models, improve model performance, provide benchmark testing, and support programming education. It effectively assesses models' natural language understanding, code generation, syntactic correctness, functional completeness, and algorithm implementation capabilities. The uniqueness of MBPP lies in its focus on everyday programming challenges, encompassing common task types in practical programming such as string manipulation, list processing, and mathematical calculations.
Researchers can use MBPP to train specialized Python code generation models, evaluate the performance of large language models on Python tasks, study the relationship between problem understanding and code generation, and develop intelligent programming assistance tools.
NaturalCodeBench
https://github.com/THUDM/NaturalCodeBench
NaturalCodeBench is a comprehensive code intelligence benchmark developed by Tsinghua University's THUDM. It integrates multiple existing code evaluation datasets and introduces new evaluation dimensions, aiming to provide a more comprehensive and natural framework for assessing code capabilities. This dataset is primarily used for comprehensively evaluating code model capabilities, cross-task comparisons, guiding model improvements, and simulating real-world programming scenarios. Its unique features include multidimensional evaluation, code naturalness assessment, cross-dataset integration, difficulty stratification, multilingual support, simulation of real programming scenarios, and a design that supports continuous updates.
NaturalCodeBench enables researchers to comprehensively evaluate and compare code intelligence models, identify model strengths and weaknesses, explore methods to improve the naturalness and practicality of code generation, and study the cross-language and cross-task generalization capabilities of models.
humaneval-x
HumanEval-X is a multilingual code generation evaluation dataset developed by Tsinghua University's THUDM, serving as an extension of the original HumanEval. It contains 164 programming problems, each implemented in 6 languages (Python, C++, Java, JavaScript, Go, and Rust), totaling 984 tasks.
HumanEval-X is primarily used to evaluate models' multilingual code generation capabilities, cross-language transfer learning abilities, and language-agnostic programming skills. Its unique features include parallel implementations in multiple languages, maintaining the original difficulty level, ensuring cross-language equivalence, and providing automated evaluation scripts.
Automated Programming Progress Standard(APPS)
https://github.com/hendrycks/apps
The Automated Programming Progress Standard (APPS) is a large-scale benchmark developed by researchers at UC Berkeley to evaluate the capabilities of code generation models. This dataset contains 10,000 original programming problems, covering a range of difficulty levels from basic to advanced, including some competition-level challenges.
Each problem in APPS includes a detailed problem description, function signature, test cases, and reference solutions. This structured data design makes it an ideal tool for evaluating code generation models. While APPS primarily focuses on Python, it also supports other programming languages, increasing its flexibility. The dataset is equipped with automated evaluation scripts that objectively test the correctness of generated code, significantly simplifying the research process.
The main application of APPS lies in evaluating the comprehensive capabilities of code generation models, particularly their performance in handling complex and diverse programming tasks. Researchers can use APPS to test models' ability to understand problem descriptions and generate correct implementations, as well as their performance across tasks of varying difficulty levels.
DeepSeek-Coder
https://github.com/deepseek-ai/DeepSeek-Coder
DeepSeek has not only demonstrated excellent performance in the mathematics field, as mentioned in the previous issue, but has also shown remarkable capabilities in the code domain. This issue continues to introduce the generation process of DeepSeek-Coder's non-open-source datasets.

This dataset primarily consists of two parts: code data and instruction data. The code data is sourced from public code repositories, particularly GitHub, and undergoes a rigorous data cleaning and filtering process, including the removal of duplicate code, low-quality code, and code that may contain personal information. The instruction data includes code-related question-answer pairs and multi-turn dialogue data, partly curated and filtered from existing open-source datasets, and partly generated as synthetic data using large language models, which are manually reviewed to ensure quality. During the data processing, DeepSeek-AI uses tree-sitter for code parsing and tokenization, applies specific encoding schemes to preserve the structural information of the code, and performs deduplication and quality control.