
Long-horizon video tasks challenge traditional annotation tools with tracking errors, slow processing, and high costs. Combining AI-assisted labeling with human review ensures accurate, scalable, and consistent annotations across extended video sequences for real-world applications.
Blogs
2025-12-26/General
Most Video Annotation Software Fails Before Your Model Ever Trains

Alexandra Bezea-Tudor,Marketing Specialist
Video Annotation Software: Why Most Tools Fail Long-Horizon Video Tasks
Why Is Long-Horizon Video Becoming Critical for Modern AI Systems?
In today's competitive computer vision landscape, video annotation software is essential for building accurate AI models that handle real-world environments. However, long-horizon video tasks require deep temporal understanding, persistent object tracking, and analysis of videos spanning minutes or even hours. These specific needs reveal limitations in most conventional video annotation tools.
Long-horizon video annotation becomes increasingly critical for fields like autonomous driving, sports analytics, and embodied AI, where models must maintain context across thousands of frames and reason about events unfolding over extended time periods.
Consider this: a standard 10-minute video at 30 frames per second (FPS) contains 18,000 frames, introducing massive labeling and annotation consistency challenges (IABM, 2021). Scaling to hour-long videos amplifies these issues dramatically, pointing to limitations in traditional annotation tools.

Why Do Most Video Annotation Tools Fail at Long-Horizon Video Tasks?
Temporal Consistency and Object Tracking Challenges
In long videos, objects frequently experience occlusions, leave and re-entries, scale changes, and motion blur. Maintaining consistent object identities across these events is a well-known challenge in long-term video understanding and multi-object tracking, especially when models and annotators must reason across extended temporal spans rather than short clips.
Most traditional video annotation tools rely on manual frame-by-frame adjustments, sparse keyframes or basic interpolation. These approaches tend to break down as video length increases, leading to inconsistent object IDs, identity switches, or complete track loss over time. Because object identity is typically managed locally rather than globally across the full sequence, small errors compound, quietly degrading dataset quality.

Scalability and Computational Limitations
Long-horizon video annotation places significant computational and system-level demands on annotation tools. Videos spanning tens or hundreds of thousands of frames strain memory usage, storage, and interactive performance, especially when multiple object tracks and dense annotations are involved.
As sequence length increases, tools often struggle with:
Memory pressure from loading long timelines
Slow or unstable interpolation across distant keyframes
Interface lag that interrupts annotator flow
Many traditional platforms experience slow timeline navigation, delayed interpolation, or unstable interfaces as video length increases. These limitations make it difficult to review, revise, and quality-check annotations at scale, reducing throughput and making large-scale long-video projects costly and operationally inefficient.
High Costs and Labor Intensity
Manual annotation prevails on most video annotation platforms. Recent academic research shows that collecting high-quality question-answer (QnA) pairs for long-video reasoning can cost tens of dollars per hour-long video (Jain et. al 2025). This cost makes building diverse, large-scale datasets economically unfeasible for many teams.
As a workaround, some researchers may adopt synthetic data pipelines: breaking videos into short 10-30 second subclips, processing them with short-video models to generate captions or QnA pairs, and iterating via LLMs (Jain et. al 2025). While clever, these methods are still time-consuming, resource-intensive, and sometimes may introduce potential biases or inaccuracies that are unable to capture true long-horizon dynamics.
What Do Long-Video Benchmarks Reveal About Current Model Limitations?
Recent long-video benchmarks consistently demonstrate that model performance degrades as temporal length increases, showing fundamental weaknesses in long-horizon video understanding.
For instance, the MLVU benchmark (CVPR 2025) shows persistent challenges in long-horizon video tasks. The paper notes that the performance of all models declines as video length increases, with short-video models like Video-LLaMA-2 maintains "a certain level of LVU ability at 3 minutes, but its performance approaches random results at 10 minutes" (Zhou et. al 2025). Even the top performer, GPT-4o, scores an M-Avg of 54.5% (within 0-100%) in multiple-choice tasks. Multi-detail tasks prove particularly difficult: while some models handle single details reasonably, they suffer catastrophic degradation on multi-detail LVU tasks. Most models fail entirely on action order (AO) and action count (AC), and struggle with summarization tasks that demand recall of multiple nuanced details (Zhou et. al 2025).
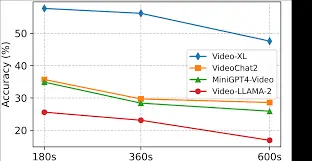
Similarly, the Neptune benchmark (2025) shows most open-source long-video models perform poorly, especially on temporal ordering, counting, and state changes, underlining the need for consistent, high-quality video annotations across long sequences (Nagrani et. Al 2024).
Beyond these benchmarks, LongVideoBench further shows the difficulty of long-context video understanding. Designed with video-language interleaved inputs of up to one hour, LongVideoBench reveals that even advanced proprietary models such as GPT-4o and Gemini-1.5-Pro face significant challenges, while open-source models lag further behind (Wu et. al 2024). Notably, performance improves only when models are capable of processing more frames. While newer long-context models continue to emerge, these results highlight persistent challenges that remain fundamental to long-horizon video understanding.
How Can Abaka AI Support Long-Horizon Video Annotation?
Abaka AI addresses long-horizon video annotation by combining AI-powered auto-labeling with human-in-the-loop quality control, smart interpolation and a smart feedback loop that improves annotation accuracy over time. The MooreData Platform is able to handle long video sequences and complex scenarios, supporting object and instance tracking, occlusion handling, multi-camera synchronization, 2D and 3D labeling, segmentation, and event annotation.

By blending automation for speed with expert review for accuracy, Abaka AI delivers consistent, high-quality video data across thousands of frames. With options like synthetic video scenarios, pre-annotated datasets, and scalable cloud pipelines, teams can train more robust models and reduce the cost and effort of large-scale video annotation. By leveraging cutting-edge automation and expert curation, Abaka AI empowers teams to build superior datasets that power truly capable long-video models.
Ready to overcome long-horizon challenges in video annotation? Let's talk.
References
Decoding Timecode Standards in Video Production (2021). https://theiabm.org/decoding-timecode-standards-in-video-production/
Guan, Z., Wang, Z., Zhang, G., Li, L., Zhang, M., Shi, Z., & Jiang, N. (2025). Multi-object tracking review: retrospective and emerging trend. Artificial Intelligence Review. https://doi.org/10.1007/s10462-025-11212-y
Zhou et al. (2025). MLVU: Benchmarking multi-task long video understanding. CVPR 2025.https://doi.org/10.48550/arXiv.2406.04264
Jain et al. (2025). SAGE: Training smart any-horizon agents for long video reasoning. arXiv. https://doi.org/10.48550/arXiv.2512.13874
Nagrani et al. (2024). Neptune: Benchmarking long video understanding. arXiv:2412.09582. https://doi.org/10.48550/arXiv.2412.09582
Wu et al. (2024). LongVideoBench: A benchmark for long-context video-language understanding. arXiv:2407.15754. https://doi.org/10.48550/arXiv.2407.15754
Neptune: The long orbit to benchmarking long video understanding (2024). Google Research Blog. https://research.google/blog/neptune-the-long-orbit-to-benchmarking-long-video-understanding/
Further Reading
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.