
To build effective training data for terminal-native agents, teams must create executable, verifiable, and task complete coding environments with clear evaluation criteria. AB-Terminal Bench achieves this through containerized tasks, pytest-based verification, oracle solutions, and multi-stage agent pipelines. In practice, structured task design and evaluation rigor, not raw data scale, determine whether coding agents improve after training.
Blogs
2026-04-28/Research
Terminal Agent Training Data: How AB-Terminal Bench Improves Coding AI

Longtian Ye,Member of Technical Staff
AB-Terminal Bench: Training Data for Terminal-Native Agents
AB-Terminal Bench is a post-training corpus of containerized terminal-coding tasks, produced through an agent-driven pipeline for training and evaluating agentic coding systems. A single round of supervised fine-tuning with approximately 2k task samples lifts Qwen3-32B from 3.37% to 28.1% averaged Pass@1 on the official Terminal-Bench 2.0 test set, with Pass@4 reaching 44.9%. That puts an open 32B base at parity with Claude Haiku 4.5 (28.3%) and above Qwen 3 Coder 480B (23.9%).on the same Terminus-2 harness.
The field is moving fast enough that this kind of data is becoming the rate-limiter. On the current Vals AI leaderboard, Claude Opus 4.7, Gemini 3.1 Pro Preview, and GPT-5.3 Codex sit at 68%, 67%, and 64% pass@1 on Terminal-Bench 2.0. Eighteen months ago, the same family of coding agents was below 15% on comparable tasks. METR's March 2025 analysis reported agent task-completion horizons doubling roughly every four months through 2024–2025. Most of the gain comes from post-training: more task variety, better tool-use trajectories, reinforcement learning on verifier-graded rollouts.
AB-Terminal Bench is independent from the official Terminal-Bench benchmark. It is produced internally at Abaka, but follows the Terminal-Bench taxonomy and Harbor-compatible runtime conventions because that stack has become the reference standard for terminal-agent work. Each task includes a self-contained Docker environment, a natural-language brief, a pytest-based verifier, and an oracle solution that proves the task is solvable. Where tasks derive from open-source materials such as GitHub Issues, pull requests, or Kaggle notebooks, we preserve attribution and apply source-specific license review before inclusion.
The dataset follows the Terminal-Bench 2.0 taxonomy, spanning 16 task categories — software-engineering, debugging, system-administration, security, file-operations, optimization, data-science, machine-learning, model-training, data-processing, data-querying, scientific-computing, mathematics, video-processing, games, and personal-assistant. Together these cover the core things a terminal agent needs to do in a real CLI environment: understand complex instructions, use tools, work with files and system resources, manipulate data and code, run experiments, verify results, and complete multi-step tasks against objective tests.
Task example
Below is a task from the ML/DS category, derived from a Kaggle materials-science competition. The agent receives a dataset of material structures (a train.json with labeled rows and test.json without) and is asked to train a regression model predicting a numeric property called hform.
Task brief excerpt. Predict the target columnhform. Use an 80/20 train/validation split withrandom_state=42. Feature pipeline must be deterministic and identical for train and test. Validation RMSE must be ≤ 0.20. Writesubmission.csv, avalid.txtcontaining the RMSE, and amain.pythat runs the full pipeline end-to-end.
The verifier is a pytest suite that encodes the brief's acceptance criteria. It runs 12 assertions on the agent's response, including these four:
- Schema alignment.
submission.csvmust contain exactly[id, hform]in that column order, with the same row count and row ordering astest.json. Weak agents often produce outputs that look plausible but swap columns or misalign rows. - Numeric validity. Every prediction has to be a finite number. Catches agents whose model silently returns
NaNon some test rows. - Accuracy threshold. The RMSE in
valid.txtis ≤ 0.20. A fixed acceptance bar, not grade-on-a-curve. - Reproducibility.
main.pymust run standalone inside the container and produce a bit-identical submission on a second run. Catches notebook-style solutions with hidden environment dependencies or nondeterministic training.
Four categories of check, covering four distinct classes of failure. A strong model can write a plausible task brief in one shot. Writing the full rubric, and getting every assertion to actually fail on the agents it should fail on, is the harder part. Across the corpus, Hard-tier tasks like this one typically carry 10 or more independent checks per task; easier tasks carry fewer, but the shape is the same: multiple assertions, covering distinct failure modes.
Building a task
The pipeline has five stages, each producing one artifact of the final task.

Environment parses the source material (a Kaggle notebook with its dataset, a GitHub Issue/PR pair, or an algorithm repository) and produces a minimal Dockerfile plus the data bundle the agent will need. Query turns the source material into the natural-language instruction and task metadata. Test produces the pytest rubric. Solution produces the oracle script. Evaluation validates that the completed candidate works as a coherent task.
Each of the first four stages runs a small chain of agents: a Builder that drafts the artifact, then a Reviewer that checks it against a rubric specific to that stage. Tests get an extra Planner stage because they are the most failure-prone output. Without a Planner to decompose what needs to be verifiable, a Builder tends to write assertions that match its own mental model of the task rather than the task's actual specification.
Evaluation is where the pipeline becomes adversarial, and it runs in two stages. First, a multi-agent flow checks that Environment, Query, Test, and Solution agree with each other and with the source material's intent. It looks for structural mismatches (instructions that reference files not in the environment; tests that expect outputs the solution does not produce), ambiguity (tasks with two valid interpretations that would each produce different graded outputs), and intent drift (tasks internally consistent but subtly off from the source's intent). The Bar Raiser review in the figure is the adversarial final pass whose job is to catch cases earlier reviewers let through.
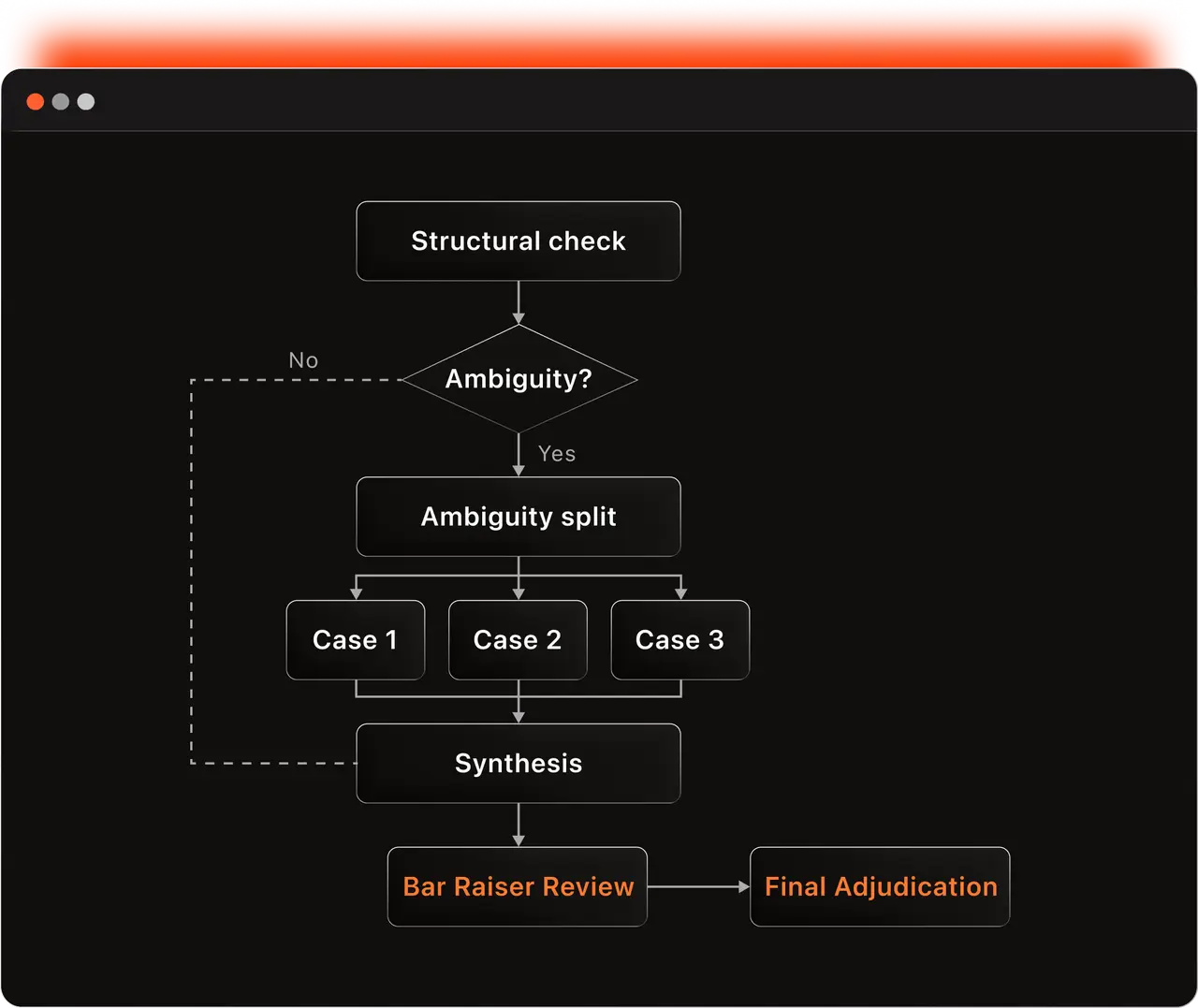
Humans do not manually review every task. They refine the rubrics, audit sampled outputs, and inspect suspicious failures. The task-by-task reviewing itself is handled by specialized reviewer agents.
Signal quality: task-level discrimination
Before using the corpus for post-training, we first checked whether it exhibited a reasonable difficulty profile. A useful training dataset should separate stronger agents from weaker ones. It is most informative when it avoids collapsing stronger systems into the same score, and retains enough headroom that weaker systems do not already pass most tasks. To assess this, we ran four agent stacks (agentic CLI + model) on a 24-task diagnostic slice, pass@1:

Mapping the 24 tasks onto a consolidated view of the full task taxonomy shows where the discrimination comes from:

These diagnostics were run during early corpus calibration. All post-training results that follow are reported on the official 89-task Terminal-Bench 2.0 test set under the Terminus-2 harness, making them directly comparable to public leaderboard entries.
Post-training on Qwen3-32B
One round of supervised fine-tuning on Qwen3-32B, trained on a oracle-pass filtered subset of AB-Terminal Bench (tasks whose oracle solution cleanly passes the full pytest rubric and whose generation cleared every pipeline stage).
.")

The lift is not uniform across the TB 2.0 task taxonomy:
")
The per-difficulty breakdown on the same official test set:

Closing
AB-Terminal Bench is ultimately an attempt to turn task quality from something anecdotal into something procedural. The hard part is not generating plausible instructions, but building tasks that are executable, verifiable, solvable, and discriminative at the same time. It takes a pipeline that can decompose, check, and reject at every stage before a task ever reaches training.
Post-training capability is increasingly bottlenecked by the supply of tasks at this standard. The signal in this post is the +24.7 pp absolute lift on Qwen3-32B from a single SFT pass on roughly 1.8k samples and AB-Terminal Bench is what we built for that bottleneck. Currently, we use the corpus internally for our own SFT and RL experiments. If this shape of data fits what you are building, contact Abaka.
Footnotes:
- AB-Terminal Bench is an independent Abaka dataset. Not affiliated with Terminal-Bench, Stanford University, or the Laude Institute.
- Headline post-training numbers (28.1% averaged Pass@1, 44.9% Pass@4) are computed on the official Terminal-Bench 2.0 89-task test set under the Terminus-2 harness, across 4 reps at temperature 0.6.
- Qwen3-32B baseline (3.37%) is sourced from NVIDIA's published measurement and was not re-measured by Abaka.
References:
- Terminal-Bench — terminal-coding agent benchmark (Stanford + Laude Institute).
- On Data Engineering for Scaling LLM Terminal Capabilities — Nemotron-Terminal-32B, NVIDIA, 2026
- Harbor — containerized runtime for Terminal-Bench (Laude Institute).
- Vals AI leaderboard — frontier model rankings on Terminal-Bench 2.0.
- Measuring AI Ability to Complete Long Tasks — METR, March 2025. Reports a 7-month doubling time on agent task horizons over 2019–2025, accelerating to ~4 months in 2024–2025.
- SWE-Bench Verified — human-validated subset of SWE-Bench used as a real-tasks reference.
FAQ
What is AB-Terminal Bench?
AB-Terminal Bench is a structured dataset of containerized coding tasks designed to train and evaluate terminal-based AI agents. Each task includes a runnable environment, instructions, verification tests, and a ground-truth solution.
Why are terminal-based datasets important for AI agents?
Terminal environments reflect real-world engineering workflows. They require agents to execute code, manage files, debug systems, and meet strict constraints, making them essential for training practical coding agents.
What makes a high-quality agent training dataset?
High-quality datasets must be executable, verifiable, and discriminative. This means tasks must run end-to-end, include objective evaluation criteria, and be difficult enough to differentiate between models.
How does AB-Terminal Bench improve model performance?
Even a single round of supervised fine-tuning on curated tasks can significantly improve agent performance, as the dataset provides structured reasoning, tool-use trajectories, and precise evaluation signals.
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.