
2025 synthetic datasets are AI-generated to mimic real data—solving scarcity, privacy, and bias. Used in auto, healthcare, robotics & more.
Blogs
2025-08-01/General
2025 Synthetic Dataset: What You Must Know Now

Josephine Ongko Wijono,VP of Commercial Strategy
2025 Synthetic Dataset: What You Must Know Now
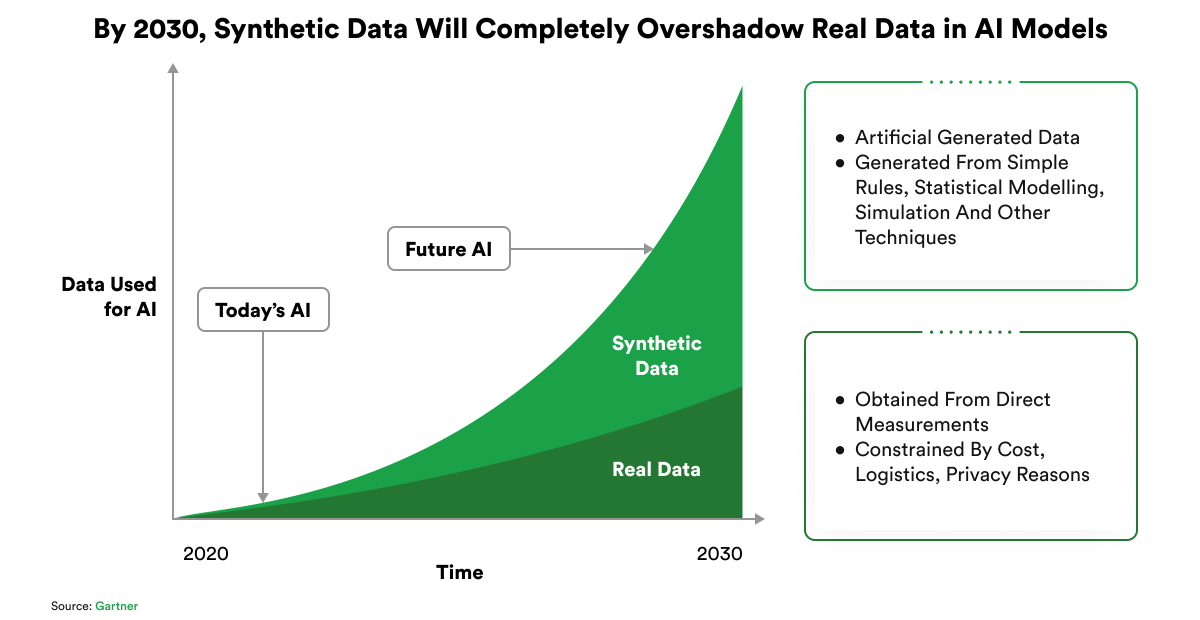
💡 By 2030, synthetic data will become the dominant force in AI training due to its unparalleled scalability, flexibility, and privacy-preserving capabilities.() Leveraging synthetic data, especially with human-in-the-loop validation, is crucial for building the next generation of scalable, fair, and high-performing AI systems. Abaka AI is at the forefront, empowering teams with curated, domain-specific synthetic data pipelines to unlock this future.
What is synthetic data?

Synthetic data is artificially generated data that mimics real-world datasets in structure, distribution, and behavior. Unlike traditional datasets collected from real environments, synthetic data is computer-generated, often using simulations, generative models, or procedural algorithms to recreate reality or even build scenarios that are rare, edge-case, or difficult to capture.
Why Use Synthetic Data?
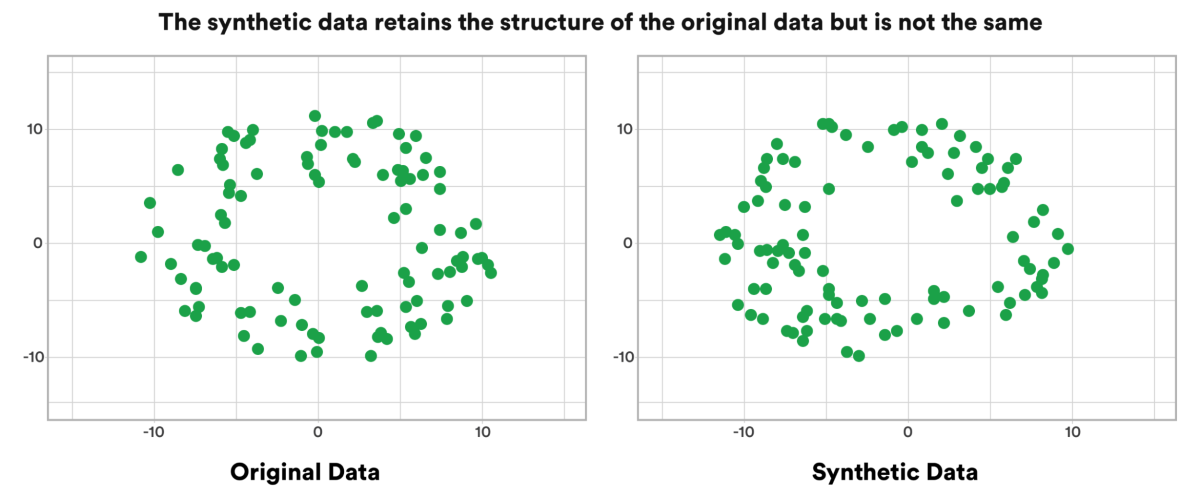
Overcome Data Scarcity: Real-world data is often unavailable, limited, or too expensive to collect—especially for new products, edge cases, or underrepresented groups.
Data Privacy & Compliance: Synthetic datasets protect sensitive information (e.g., PII or HIPAA-regulated data), enabling safer innovation without legal risks.
Bias Correction: You can balance underrepresented categories to improve fairness and reduce algorithmic bias.
Cost Efficiency: Generate thousands of high-quality examples quickly, without long data collection cycles or expensive manual labeling.
Faster Prototyping: Use synthetic data to simulate model performance before real data is even available.
How Is Synthetic Data Generated?
Synthetic data is more than manufactured numbers—it’s carefully engineered using advanced algorithms, simulations, and human oversight to mirror or extend real-world scenarios. Here’s how synthetic data is created today:
1. Rule-Based & Statistical Simulation
Rule-based generation: Built using domain-specific logic and constraints—great for structured tasks like financial transactions or sensor output.
Probabilistic modeling: Sampling from realistic distributions to recreate behavior patterns like customer churn or sensor noise.
2. Generative AI Techniques
GANs (Generative Adversarial Networks): A generator-discriminator setup creates realistic images, videos, or audio.
VAEs (Variational Autoencoders): Compress and reconstruct data to produce synthetic samples with real-like structure.
Diffusion models: Gradually transform noise into high-fidelity outputs—ideal for photorealism and medical imaging.
3. Procedural & Simulation-Based Methods
3D simulations: Create urban traffic, hospital rooms, or warehouse floors in virtual space.
Domain randomization: Inject variations like lighting, angle, and texture so models don’t overfit to unrealistic uniformity.
4. Hybrid & Privacy-Preserving Approaches
Partially synthetic datasets: Replace sensitive features while keeping statistical value intact.
Fully synthetic datasets: Generated from scratch—zero real-world traces, maximum privacy and control.
Abaka AI’s Advantage: Smart Pipelines That Learn
At Abaka AI, we combine cutting-edge generation techniques with real-world awareness:
Component | Abaka’s Approach |
|---|---|
Scenario Modeling | Custom simulations for your use case (e.g., AV, medtech, retail). |
Generative Techniques | GANs, diffusion, VAEs—tailored to your domain. |
Domain Randomization | Built-in variability for generalization. |
Human-in-the-Loop Review | Every batch reviewed for logic, realism, and accuracy. |
Real-Synthetic Hybridization | Combine both for stronger, benchmark-ready performance. |
Examples of use cases
1. Autonomous Driving
Want to train a car to respond to a pedestrian running across the street at night or in heavy rain? You can’t wait for those situations to happen in real life—you simulate them.

Data Type: Photorealistic 3D street simulations with multiple sensor views (RGB, depth, LiDAR).
Annotations: Semantic segmentation, instance masks, bounding boxes, depth maps.
Use Case: Lane detection, object tracking, crash avoidance, edge-case recognition.
2. Healthcare & Medical Imaging
Need to train a model on rare tumors in pediatric cases or simulate underrepresented patient groups? Privacy restrictions and data scarcity make real data hard to find. Synthetic imaging helps bridge the gap.
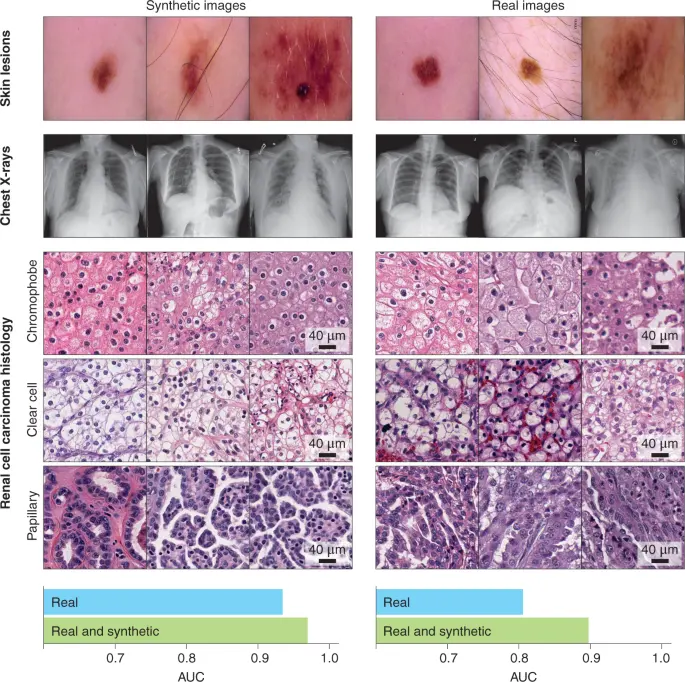
Data Type: AI-generated X-rays, MRIs, CT scans across diverse conditions and demographics.
Annotations: Tumor masks, heatmaps, classification labels, anatomical landmarks.
Use Case: Disease detection, model generalization across age/gender groups, regulatory training datasets.
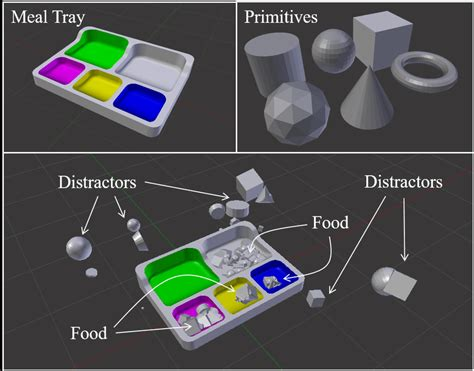
3. Robotics & 3D Object Understanding
Training robots to interact with the physical world—like picking up a coffee mug from a messy table—requires vast, diverse datasets. Synthetic indoor scenes allow developers to test every possible setup without a single physical object.
Data Type: 3D synthetic environments (home, warehouse, lab) with varied object shapes, sizes, lighting.
Annotations: RGB-D, segmentation masks, 6D pose estimation, surface normals.
Use Case: Object grasping, navigation, embodied AI training.
4. Retail & E-Commerce
Need marketing visuals before you even manufacture the product? Want to A/B test how different demographics interact with it? Synthetic product imagery and journey simulations enable faster go-to-market cycles.
Data Type: Synthetic human models, retail environments, apparel/furniture rendering.
Annotations: Gaze tracking, pose estimation, conversion event labels.
Use Case: Visual search, AR product placement, customer journey prediction.
5. Finance & Anomaly Detection
Fraud doesn’t happen every day—but your model should be ready when it does. Synthetic financial datasets can simulate high-risk behavior in low-frequency patterns, giving you enough samples to train a reliable detector.
Data Type: Time-series synthetic transactions, identity graphs, anomaly-injected flows.
Annotations: Fraud flags, transaction categories, behavioral clusters.
Use Case: Fraud detection, synthetic customer behavior modeling, adversarial testing.
Key considerations
Synthetic data can be magical, but only if done right. Consider:
Does it reflect real-world complexity?
Is it diverse enough to reduce bias—or is it replicating one?
Who’s validating the outputs? Humans, algorithms, or both?
Are you combining it with real data for robustness?
At Abaka AI, we help you navigate these questions with a hands-on approach: from custom scenario design to human-reviewed annotations and performance testing against real benchmarks.
🚀 Ready to future-proof your AI with high-performance synthetic datasets?
Book a demo with Abaka AI to explore tailored solutions for your domain—whether it's automotive, robotics, healthcare, or generative AI.
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.