
The primary difference between structured and unstructured data lies in their schema: structured data follows a rigid, tabular format (SQL), while unstructured data (text, images, video) lacks a predefined model and accounts for 90% of enterprise data. For Machine Learning pipelines, this distinction dictates everything—from the shift from manual feature engineering to vector embeddings, to the requirement for high-performance GPU computing and specialized human-in-the-loop annotation for unstructured datasets.
Blogs
2026-01-23/General
Structured vs Unstructured Data in Machine Learning: How Each One Breaks Your Pipeline

Yuna Huang,Marketing Curator
How Structured and Unstructured Data Affect Machine Learning Pipelines Differently
In the modern AI landscape, data is no longer just "numbers in a spreadsheet." As enterprises race to deploy Generative AI and Computer Vision, the architecture of the Machine Learning (ML) pipeline must evolve to handle two fundamentally different types of fuel: Structured and Unstructured data.
Understanding these differences is the key to reducing technical debt and accelerating time-to-market for your AI products.
The Anatomy of Data: Rows vs. Raw Content
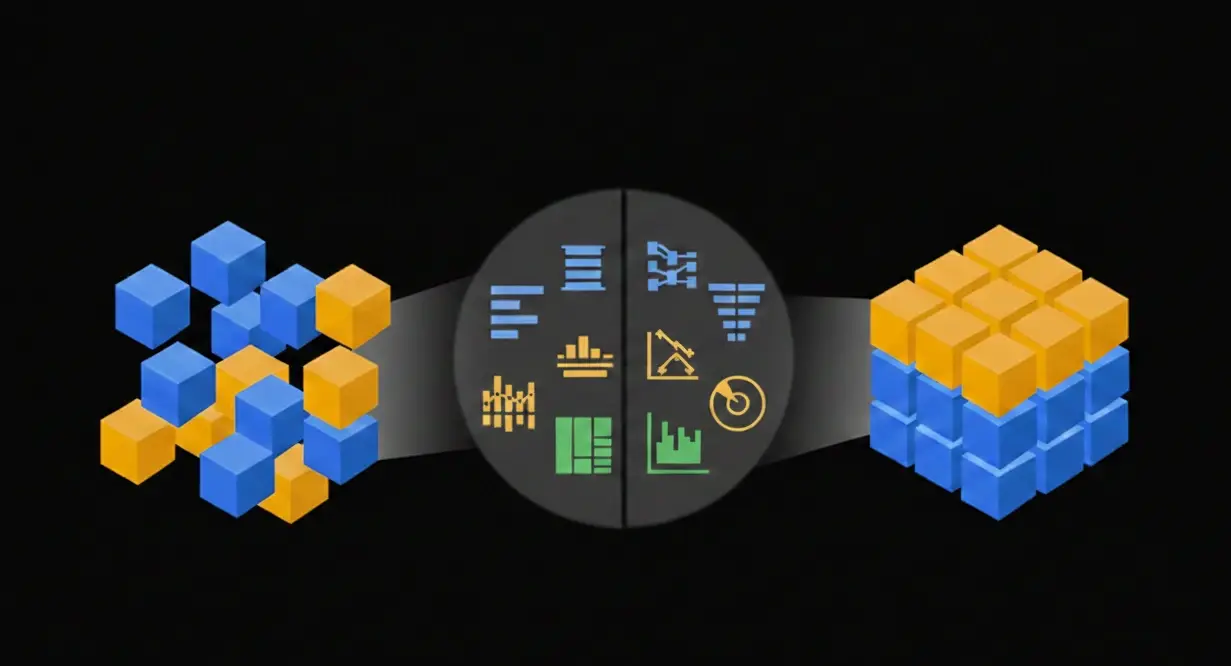
Structured Data: The Predictable Backbone
Structured data is highly organized and formatted in a way that is easily searchable by traditional algorithms.
Examples: Financial transactions, CRM records, inventory logs.
Storage: Relational databases (RDBMS) like PostgreSQL or data warehouses like Snowflake.
Unstructured Data: The Untapped Goldmine
Unstructured data is information that doesn't fit into a pre-defined data model. It is diverse, massive in scale, and rich in context.
Examples: Customer support emails, medical X-rays, Zoom recordings, LiDAR point clouds.
Storage: Data Lakes or NoSQL databases like MongoDB and Azure Blob Storage.
Impact on the ML Pipeline: A Comparative Deep Dive
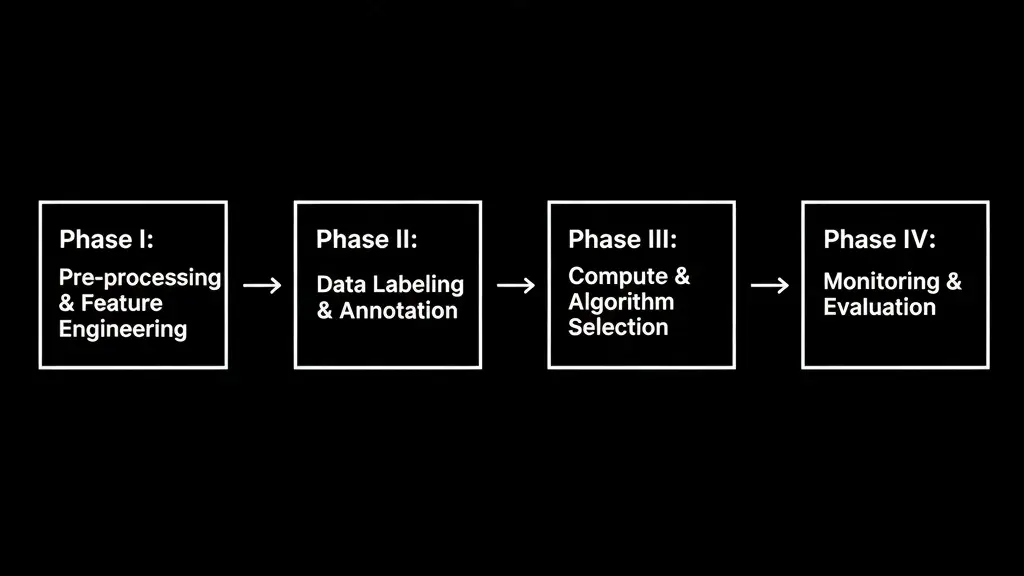
The choice of data type ripples through every stage of your ML pipeline. Here is how they differ across the four critical phases:
Phase I: Pre-processing & Feature Engineering
Structured Pipeline: Success depends on Feature Engineering. Data scientists spend weeks transforming raw columns into meaningful inputs (e.g., calculating "customer lifetime value" from purchase history).
Unstructured Pipeline: Modern pipelines rely on Representation Learning. Instead of manual features, we use Embeddings—converting raw images or text into high-dimensional vectors. These vectors capture semantic meaning, allowing the model to "understand" that a photo of a cat and the word "feline" are related.
Phase II: Data Labeling & Annotation
Structured: Labeling is often "implicit." For instance, a "churn" label is automatically generated if a user cancels their subscription.
Unstructured: This is where the bottleneck occurs. Unstructured data requires Human-in-the-Loop (HITL) annotation. Whether it’s bounding boxes for autonomous driving or Named Entity Recognition (NER) for legal docs, you need a robust platform like Abaka AI to manage high-quality labeling at scale.
Phase III: Compute & Algorithm Selection
Structured: You can often achieve state-of-the-art results using Tree-based models (XGBoost, LightGBM) on standard CPUs. Training is fast and cost-effective.
Unstructured: This is the domain of Deep Learning (Transformers, CNNs). These models require massive GPU/TPU clusters. To manage costs, pipelines often use Transfer Learning, taking a pre-trained model (like GPT-4 or ResNet) and fine-tuning it on specific enterprise data.
Phase IV: Monitoring & Evaluation
Structured: Monitoring focuses on Data Drift—checking if the statistical distribution of features (like average age) has changed.
Unstructured: Evaluation is more nuanced. You must monitor Embedding Drift and use complex metrics like mAP (mean Average Precision) for vision or ROUGE/BLEU scores for NLP to ensure the model isn't hallucinating or degrading.
The Hybrid Challenge: Bridging the Gap
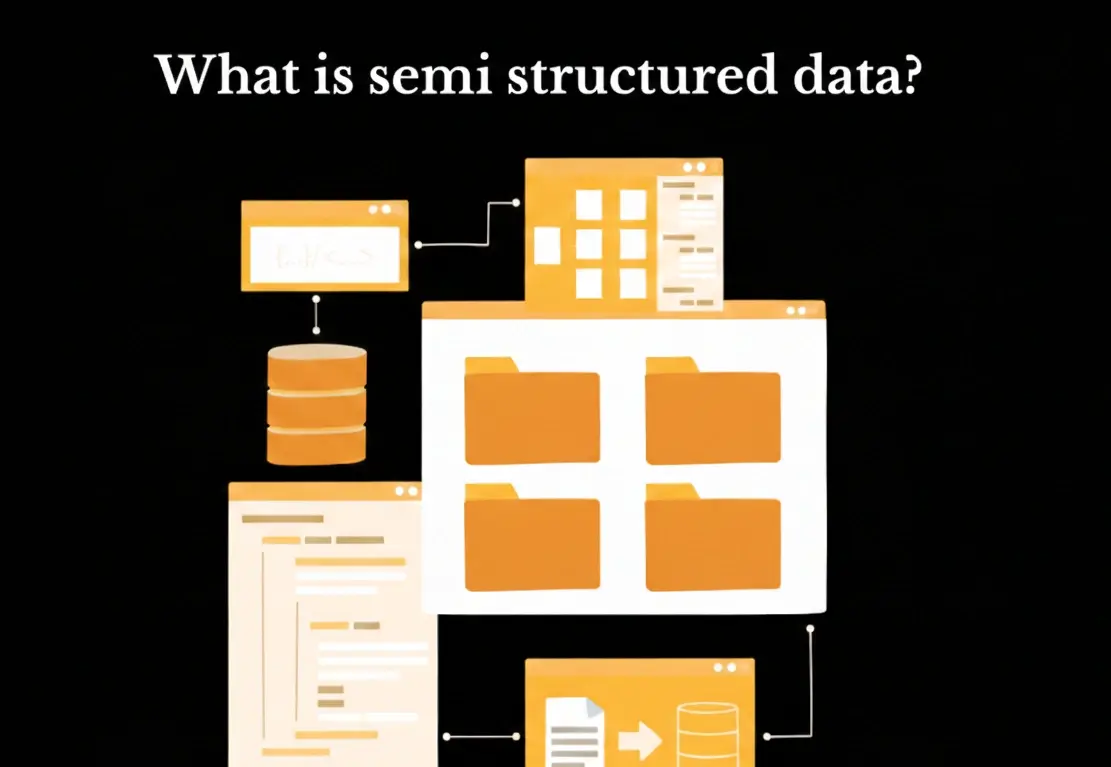
Many modern applications are semi-structured. Take an email: it has structured headers (To, From, Date) and an unstructured body (the text).
A high-performing ML pipeline must be able to ingest both. This is where many companies struggle—managing a fragmented stack of tools that don't talk to each other.
Why Abaka AI is the Catalyst for Your ML Pipeline
At Abaka AI, we specialize in turning data chaos into model clarity. Our platform is designed to handle the heavy lifting of the unstructured data lifecycle while maintaining the precision required for structured analysis.
Unified Data Ingestion: Connect your SQL databases and your S3 buckets into a single workflow.
AI-Assisted Labeling: Reduce annotation time by 60% using our pre-labeling algorithms for text and vision.
Embedding Management: Visualize your unstructured data clusters to identify edge cases and outliers before they hit production.
Seamless Integration: Export your high-quality datasets directly into your training environment with one click.
The gap between structured and unstructured data is narrowing as AI becomes more sophisticated. The winners will be the organizations that can build a unified pipeline capable of extracting value from both.
Ready to optimize your ML Pipeline? Book a Demo with Abaka AI.
FAQ: Structured vs. Unstructured Data in Machine Learning
Q: What is the main difference between structured and unstructured data in ML?
A: The primary difference is the schema. Structured data follows a rigid, tabular format (SQL) suitable for tree-based models, while unstructured data (text, images, video) lacks a predefined model, accounting for 90% of enterprise data and requiring Deep Learning for processing.
Q: How does the preprocessing of unstructured data differ from structured data?
A: Structured data relies on manual feature engineering (e.g., column transformations). In contrast, unstructured data uses representation learning to create vector embeddings, converting raw content into high-dimensional numerical values that capture semantic meaning.
Q: Why is human-in-the-loop (HITL) annotation critical for unstructured datasets?
A: Unlike structured data, where labels are often implicit (e.g., transaction records), unstructured data requires explicit interpretation. Humans must provide context through tasks like bounding box annotation for vision or NER for text to ensure model accuracy.
Q: What are the compute requirements for structured vs. unstructured ML pipelines?
A: Structured pipelines are cost-effective and typically run on CPUs using algorithms like XGBoost. Unstructured pipelines require GPUs/TPUs to handle the massive parallel processing demands of Transformers and CNNs.
Q: How do you monitor performance in an unstructured data pipeline?
A: Beyond standard data drift, unstructured pipelines must monitor embedding drift. Evaluation uses specialized metrics such as mAP (mean Average Precision) for computer vision and ROUGE/BLEU scores for natural language processing to detect model hallucination or degradation.
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.