A Guide to Synthetic Data Generation with Machine Learning
Agnese Cipollone,AI Product Sales Specialist
Synthetic data offers scalable, privacy-preserving alternatives to real-world data. This article reviews key methods (GANs, VAEs, LLMs), applications, risks (bias, evaluation), and how companies can leverage synthetic data to accelerate AI development.
Synthetic Data Generation: Machine Learning Techniques, Challenges & Best Practices
Introduction
Data is the foundation of modern AI systems, but using real data often raises privacy, cost, or compliance challenges. Synthetic data generation aims to simulate datasets that reflect real data properties without exposing sensitive information. While early efforts relied on statistical models, machine learning methods now dominate this field.
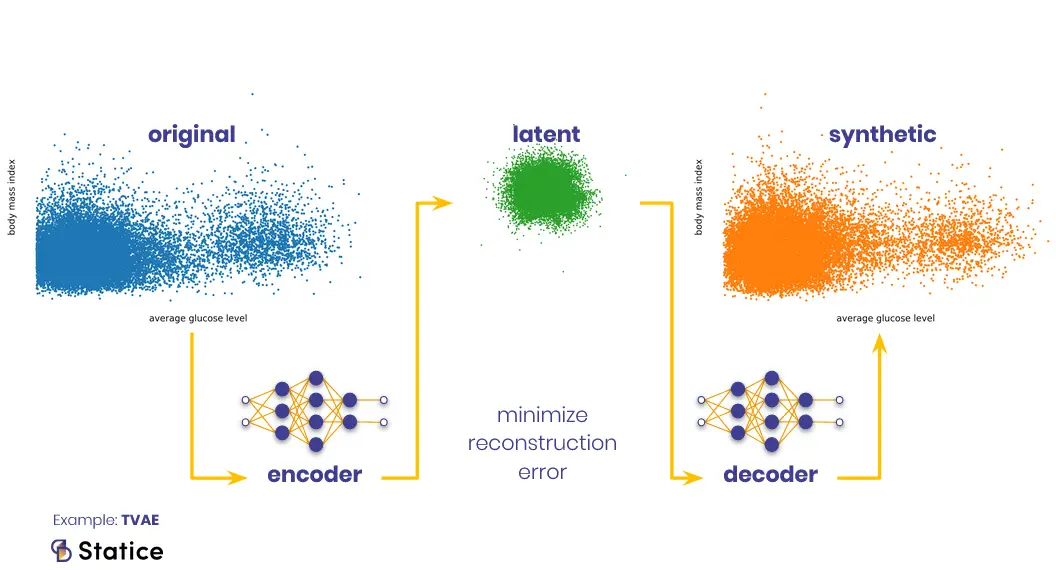
Sythetic Data Generation Process
Core techniques in synthetic data generation include:
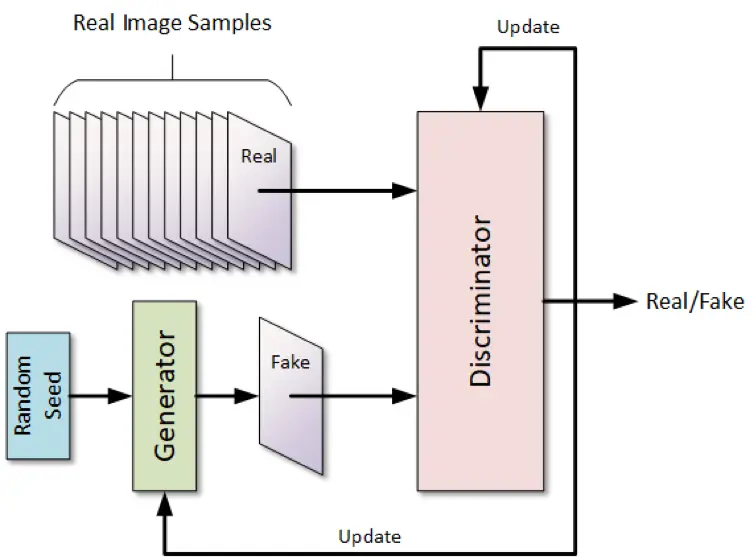
Generative Adversarial Networks (GANs) & Variational Autoencoders (VAEs):GANs pit a generator and discriminator in adversarial training, while VAEs encode data into latent spaces and sample new instances.
Tabular & Latent Space Methods:In tabular settings, models often combine feature-level density estimation, latent space sampling, or conditional synthesis
LLM-based & Hybrid Models: LLMs generate synthetic data by learning underlying patterns, using techniques like domain-specific tuning, multimodal synthesis, and automated validation.
Overview of GAN Structure
This data is used across industries to drive innovation, address scarcity, protect privacy, and simulate rare events or edge-case scenarios. Key examples include:
Computer Vision & Synthetic Imaging: Synthetic image data helps train vision systems in scenarios where real images are scarce or costly.
Healthcare & Medical Data: Synthetic approaches allow cross-border data sharing, simulate clinical trials, and preserve privacy while supporting predictive models.
NLP & Text Synthesis: Synthetic user-generated text data can help address label scarcity and privacy, and new evaluation frameworks aim to assess realism and utility.
Computer Vision Representation
While synthetic data offers clear advantages, it also brings important challenges that researchers and practitioners must carefully address, including the following key risks:
Bias & Distribution Shifts: Synthetic datasets may replicate or even amplify biases present in the original data, leading models astray in deployment.
Evaluation & Utility: Ensuring synthetic data supports downstream model performance is nontrivial.
Model Collapse / Recursion: If AI models train on synthetic data generated by earlier models, errors can propagate (“model collapse”).
Privacy Risks: Though synthetic data is designed to be non-identifying, adversarial attacks or poor design can leak sensitive signals.
To make synthetic data effective for ML, best practices include hybrid datasets, domain-specific tuning, automated validation, transparent governance, and continuous feedback. Hybrid, validated pipelines maximize utility, and Abaka AI can help design reliable, tailored datasets.
Ready to build a synthetic data pipeline that delivers real-world results? Contact Abaka AIto discuss your project needs.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.