Gemini 3.1 Pro: The 77.1% ARC-AGI-2 Breakthrough in AI Reasoning
Yuna Huang,Marketing Curator
Google’s Gemini 3.1 Pro has established a new benchmark for abstract reasoning, achieving a verified 77.1% on ARC-AGI-2—more than doubling the performance of Gemini 3 Pro. By shifting from pattern recognition to true logical synthesis, 3.1 Pro enables complex problem-solving across 1M+ token contexts and multimodal inputs. For enterprise and developer ecosystems, this upgrade represents the transition from simple chatbots to production-grade agentic workflows capable of handling science, research, and high-fidelity engineering challenges.
Google’s Gemini 3.1 Pro Hits 77.1% on ARC-AGI-2 — More Than Double Gemini 3 Pro
On February 19, 2026, Google released Gemini 3.1 Pro, a major upgrade to its core intelligence designed for the world's most complex tasks.
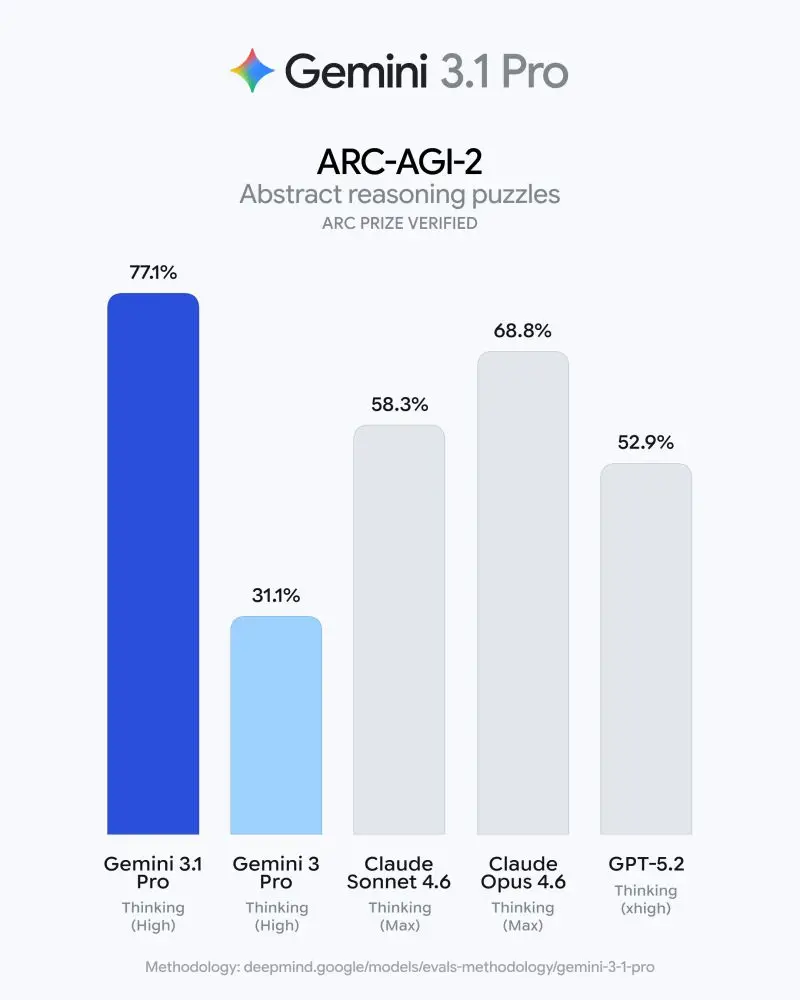
The model's standout achievement is a verified score of 77.1% on the ARC-AGI-2 benchmark, representing more than double the reasoning performance of its predecessor, Gemini 3 Pro. This jump signals a shift from pattern matching to true abstract reasoning, making 3.1 Pro the new baseline for ambitious agentic workflows and scientific problem-solving.
The ARC-AGI-2 Breakthrough: Decoding the 77.1% Score
The ARC-AGI-2 (Abstraction and Reasoning Corpus) is widely considered one of the hardest benchmarks in AI because it requires models to solve entirely new logic patterns they have not seen during training.
Quantitative Leap: Gemini 3.1 Pro achieved 77.1%, a staggering increase from the 31.1% scored by Gemini 3 Pro.
Competitive Edge: This score places Google significantly ahead of industry peers; for comparison, Opus 4.6 (Thinking Max) follows at 68.8%, while GPT-5.2 (Thinking xhigh) sits at 52.9%.
The "Why": Unlike "black box" generation, 3.1 Pro utilizes enhanced reasoning to synthesize data into a single view and comprehend vast datasets from multimodal sources including text, images, and entire code repositories.
Intelligence Applied: Beyond Simple Answers
Google designed Gemini 3.1 Pro for environments where a "simple answer isn't enough". According to the official Google DeepMind technical report, the model excels in practical, high-stakes applications:
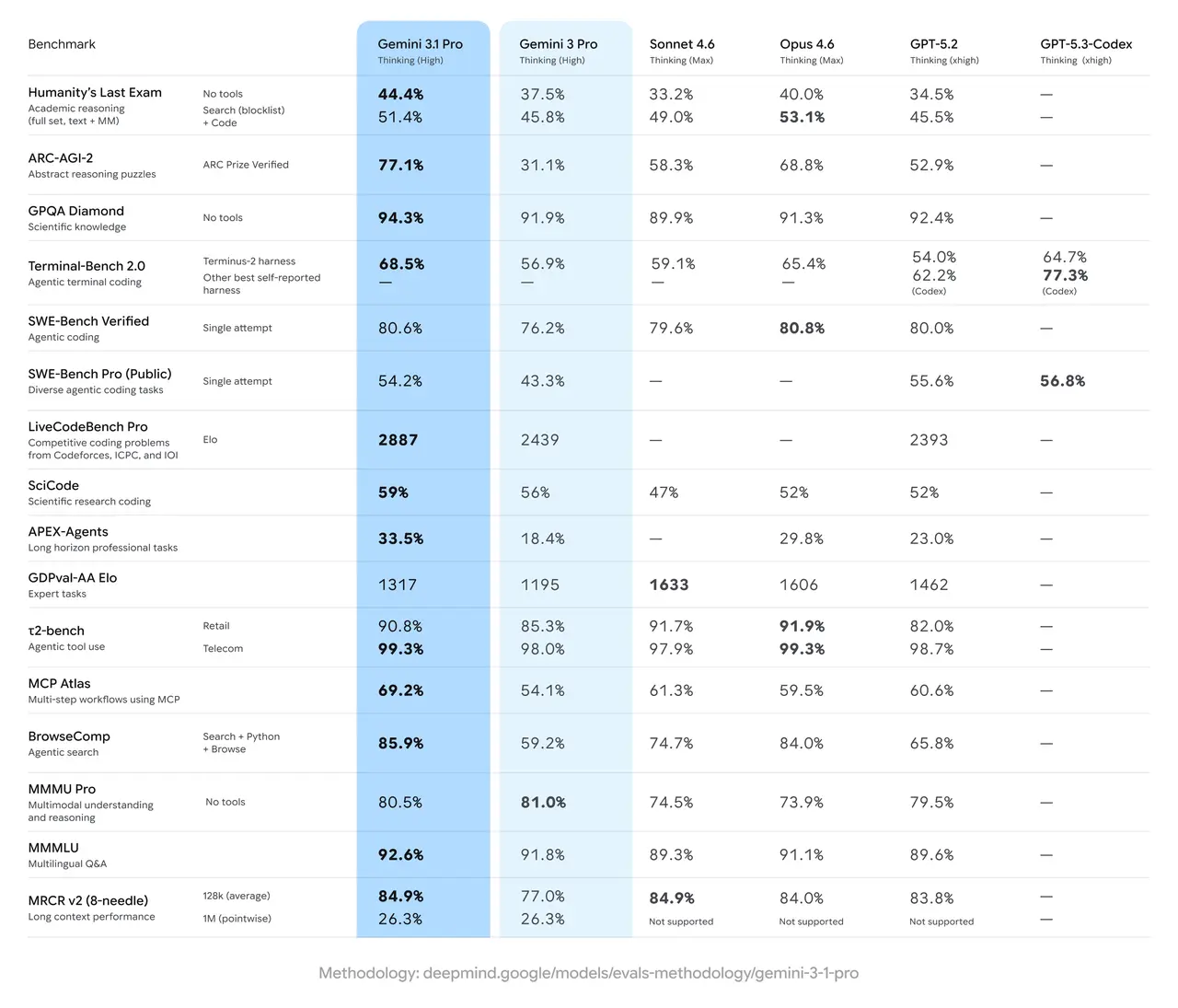
Complex Coding: In Terminal-Bench 2.0 (Agentic terminal coding), 3.1 Pro reached 68.5%, outperforming both Gemini 3 Pro (56.9%) and GPT-5.3-Codex (64.7%).
Scientific Research: The model scored 94.3% on GPQA Diamond, a benchmark for expert-level scientific knowledge, and 59% on SciCode, a scientific research coding suite.
Long-Context Professionalism: On the APEX-Agents benchmark, which measures performance on long-horizon professional tasks, 3.1 Pro nearly doubled the performance of the previous version, jumping from 18.4% to 33.5%.
In short, Gemini 3.1 Pro is used when tasks require strategic planning and step-by-step improvements but fails when high-fidelity pointwise accuracy is needed across 1M+ token contexts without additional search tools.
Frontier Safety: Deep Think and Mitigations
With great power comes the need for rigorous safety. Google’s Frontier Safety Framework evaluated 3.1 Pro across five critical risk domains:
Cybersecurity: While the model shows an increase in cyber capabilities, it remains below alert thresholds for Critical Capability Levels (CCL).
Deep Think Mode:Interestingly, when accounting for inference costs, the "Deep Think" mode performs considerably worse in certain cyber domains than the standard mode, suggesting that high-level reasoning doesn't always translate to higher risk in specialized technical attacks.
Machine Learning R&D: The model demonstrated a human-normalized average score of 1.27 on RE-Bench, successfully reducing the runtime of a fine-tuning script from 300 seconds to 47 seconds.
Final Thoughts: The New Operating System for Agents
The release of Gemini 3.1 Pro across Google Antigravity, Vertex AI, and the Gemini API suggests that AI is moving from a chatbot-centric model to an agentic "operating system". For developers, the key difference between 3.1 Pro and previous models is not just the speed of response, but the deterministic logic applied to entirely new puzzles.
Q: What is the token context window for Gemini 3.1 Pro?
A: Gemini 3.1 Pro supports a token context window of up to 1M tokens for inputs and 64K tokens for outputs.
Q: Where can developers access Gemini 3.1 Pro today?
A: It is currently available in preview via the Gemini API in Google AI Studio, Gemini CLI, Vertex AI, and Google’s agentic development platform, Google Antigravity.
Q: How does the ARC-AGI-2 score compare to a human?
A: While 77.1% is a record-breaking score for an AI model, the benchmark is designed to measure "human-like" abstract reasoning. Achieving this score indicates the model can solve logical puzzles it hasn't seen before, a core requirement for AGI.
Q: Does Gemini 3.1 Pro have multimodal capabilities?
A: Yes. It is natively multimodal, meaning it can process and reason across text, audio, images, video, and entire code repositories simultaneously.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.