
Cinematic AI video isn’t built on models alone—it’s powered by production-grade datasets. This article will explores why they matter, highlights recent research on AI-driven video summarization using deep learning (CNNs, LSTMs, ResNet50), and shows how ABAKA AI’s MooreData platform transforms raw footage into training-ready data for next-gen video generation.
Blogs
2025-08-22/General
Cinematic AI Video: Power of Production-Grade Datasets & MooreData

Josephine Ongko Wijono,VP of Commercial Strategy
AI Video Generation Secrets: Training Models with Production-Grade Datasets

Why do most AI-generated videos still look jittery or blurry—while some look almost cinematic? The difference isn’t just in the model architecture. It’s in the data.
Behind every smooth, photorealistic frame lies a hidden layer of production-grade datasets—clean, curated, and diverse enough to teach models how the real world looks, sounds, and moves. At ABAKA AI, we specialize in building these datasets so AI teams can move from prototypes to studio-quality video generation.
Why Datasets Matter More Than Ever

For video generation, models must capture movement, temporal coherence, context, emotion, and fidelity. High-quality, production-ready datasets are foundational:
High-resolution — training on 4K+ footage builds real-world texture, lighting, and depth.
Multimodal richness — synchronized video, audio, transcripts, and metadata allow models to align motion, lip sync, and narrative context.
Diverse scenarios — variability in lighting, settings, and demographics prevents synthetic uniformity.
Rights-cleared — ensures commercial legality and ethical deployment.
What Makes Data “Production-Grade”?
Curated and Cleaned: Internet-sourced video is noisy; production-grade datasets are filtered and de-duplicated.
Rich Annotations: Beyond frames—labels for gestures, interactions, emotions, and scene dynamics.
Balanced Representation: Diverse across culture, age, and setting, to avoid bias.
Scalable: Capable of supporting large-scale deep learning workloads (think petabytes).
Academic Edge: Insights from Recent Research
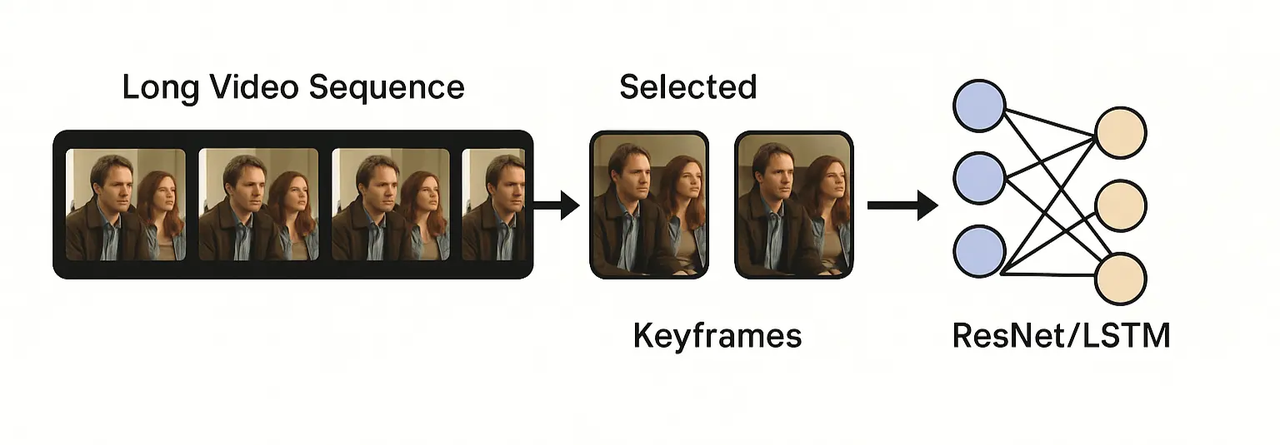
A recent study in Scientific Reports explores AI-driven video summarization using deep learning techniques, including convolutional neural networks, LSTMs, and ResNet50 models. Why it matters:
Temporal understanding: Summarization models grasp frame-to-frame coherence, useful when generating smooth, consistent video.
Feature extraction: Deep architectures (e.g., ResNet50) help understand visual semantics—informative when training generation models to capture scene structure.
Retrieval and management: Summarization improves how we index and select data—key to building curated training sets.
These summarization approaches allow us to preprocess and structure datasets more intelligently—ensuring models train on meaningful, representative content, not noise.
SmartDev’s Playbook: Holistic AI Model Training

SmartDev’s comprehensive guide on AI model training outlines best practices across the lifecycle:
Data is King: Emphasizes rigorous data preparation—cleaning, labeling, and partitioning into training, validation, and test sets.
Diverse Training Types: Covers supervised, unsupervised, semi-supervised, and reinforcement learning—helpful for blending labeled video with synthetic or unlabeled sources.
Workflow:
Define problem & objectivesPrepare data (clean-label-split)Choose algorithm/frameworkTrain with hyperparameter tuning and validation loops
Tools & Infrastructure: Highlights GPUs, TPUs, and cloud platforms (AWS, GCP, Azure) for scalable deep learning.
Ethics & Performance: Bias mitigation, data privacy, and AutoML tools for tuning and deployment.
Abaka Forge in Action: Streamlining Video Data for Training
Production-grade datasets aren’t just about sourcing high-quality footage—they require efficient processing tools to prepare video for large-scale model training. That’s where ABAKA AI’s Abaka Forge platform comes in.
With Abaka Forge, teams can:
Extract Frames at Scale – Use the built-in Video Frame Extraction Tool to break videos down into high-resolution frames, with flexible options for timed or count-based extraction.
Customize Outputs – Control compression levels, formats (JPG/PNG), and indexing for seamless dataset integration.
Support Annotation & Labeling – Pair video frames with tools like the Image Annotation Tool or RLHF Annotation Tool for action labeling, gesture detection, and reinforcement learning workflows.
Synthesize Data – The Data Synthesis Tool allows for batch generation of synthetic data, enhancing dataset diversity and balance.
By integrating dataset preparation, annotation, and synthetic data generation under one platform, Abaka Forge helps AI teams transform raw footage into training-ready datasets—faster, cleaner, and at scale.
How Abaka AI Elevates Video Generation
Here’s how we combine academic rigor, SmartDev’s engineering best practices, and Abaka Forge’s platform capabilities to deliver superior datasets:
Component | Description |
|---|---|
Summarization-Enhanced Curation | Applying deep summarization techniques (e.g., ConvLSTM, ResNet50) to filter and structure training video, ensuring relevance and temporal richness. |
Multimodal Annotation Pipelines | Frame-level and sequence-level labels covering objects, actions, speech, emotions, and metadata. |
Balanced & Rights-Cleared Content | Diverse, licensed footage across demographics and environments, ensuring legal compliance. |
Scalable Infrastructure | Leveraging cloud GPUs/TPUs and MLOps pipelines to manage petabyte-scale training with reproducible workflows and auto-retraining. |
Abaka Forge Tools | From frame extraction to data synthesis, enabling end-to-end preparation of training-ready video datasets. |
Looking Ahead: Cinematic AI Video at Scale

With the right data foundation, AI-generated video will evolve into:
Personalized content creation—multilingual virtual actors or on-demand VR scenes.
Real-time education & training—dynamic, curriculum-aligned video generation.
Immersive entertainment—procedurally generated content for games, simulations, or live experiences.
The key driver? Production-grade datasets designed for scale, coherence, and multimodal richness.
Final Thoughts
Great models don’t just run on GPUs—they run on data you can trust.
If your team is building the next Veo, Sora, or proprietary video model, don’t let poor data be the bottleneck. With Abaka Forge and production-grade, licensed, multimodal datasets, ABAKA AI empowers you to train at scale—ethically, efficiently, and commercially ready scale.
👉 Get in touch with us to start building with data that delivers cinematic results.
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.