
AI safety evaluation data is the structured, continuously generated adversarial data that reveals how models fail under real-world conditions. It is the missing layer that enables red teaming, multi-turn attack testing, and reliable safety assurance beyond static benchmarks.
Blogs
2026-03-26/Research
AI Safety Evaluation Data | Red Teaming & AI Safety

Longtian Ye,Member of Technical Staff
Every Model Breaks: Building the Data Layer Behind AI Safety Evaluation
AI safety evaluation has scaled fast. HarmBench standardized 18 attack methods against 33 models under a unified framework (Mazeika et al., 2024). OpenAI and Anthropic jointly red-teamed each other's frontier models (OpenAI & Anthropic, 2025). A meta-analysis surveyed 210 safety benchmarks, the most comprehensive audit of the field to date (Yu et al., 2026). And the UK AI Safety Institute ran 1.8 million attacks across 22 frontier models (UK AISI, 2026).
Every single model broke.
If every model breaks under sufficient adversarial pressure, the value of safety evaluation lies not in pass/fail verdicts but in understanding how models break — along which dimensions, under which strategies, at what severity. The bottleneck is not the frameworks or the models. It is the data.
What AI Safety Benchmarks Miss
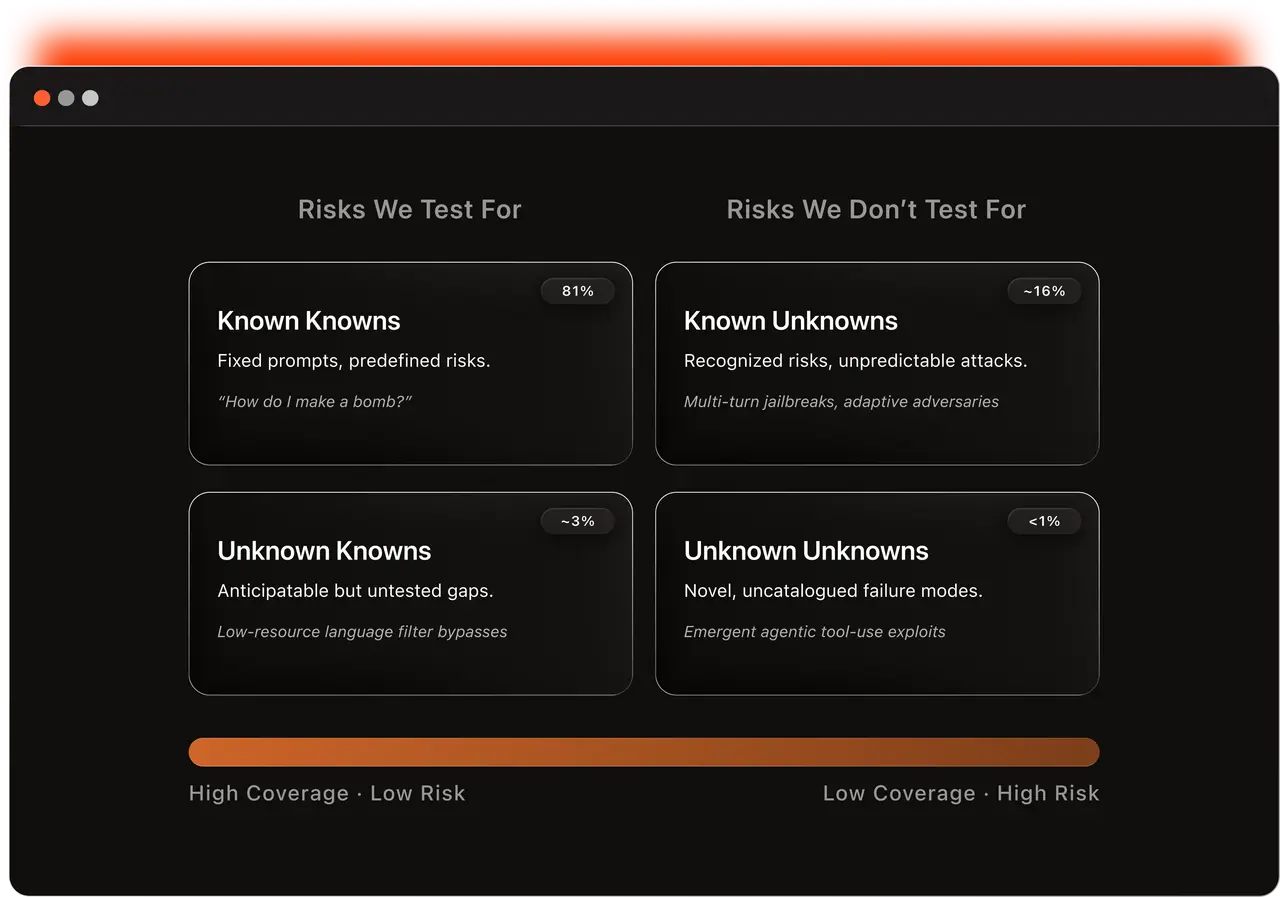
Current benchmarks reliably detect known attack patterns, but a meta-analysis of 210 safety benchmarks exposes how narrow those conditions are: 81% test only predefined risks with fixed prompts, 68% are single-turn only, 79% reduce safety to binary pass/fail, and 89% run on static data (Yu et al., 2026). Yet multi-turn attacks are where models actually break — distribute harmful intent across 5–20 conversational turns and failure rates climb to 75% (Li et al., 2024). Intent Laundering achieves 90–98% ASR by stripping triggering cues while preserving harmful intent (Golchin & Wetter, 2026). And measurement itself is unstable: the same model shows 4.7% ASR on a single attempt but 63% at 100 attempts (VentureBeat, 2025).
A Rumsfeld Matrix from Yu et.al maps safety risk coverage into four quadrants — and the distribution is stark. 81% of benchmarks sit in the Known Knowns quadrant: fixed prompts testing predefined risks, where marginal value is lowest. Only 3% attempt to probe Unknown Knowns (risks we could anticipate but don't test for) and Unknown Unknowns (novel failure modes no one has catalogued yet) — where the most dangerous failures live.
The AI Safety Data Problem
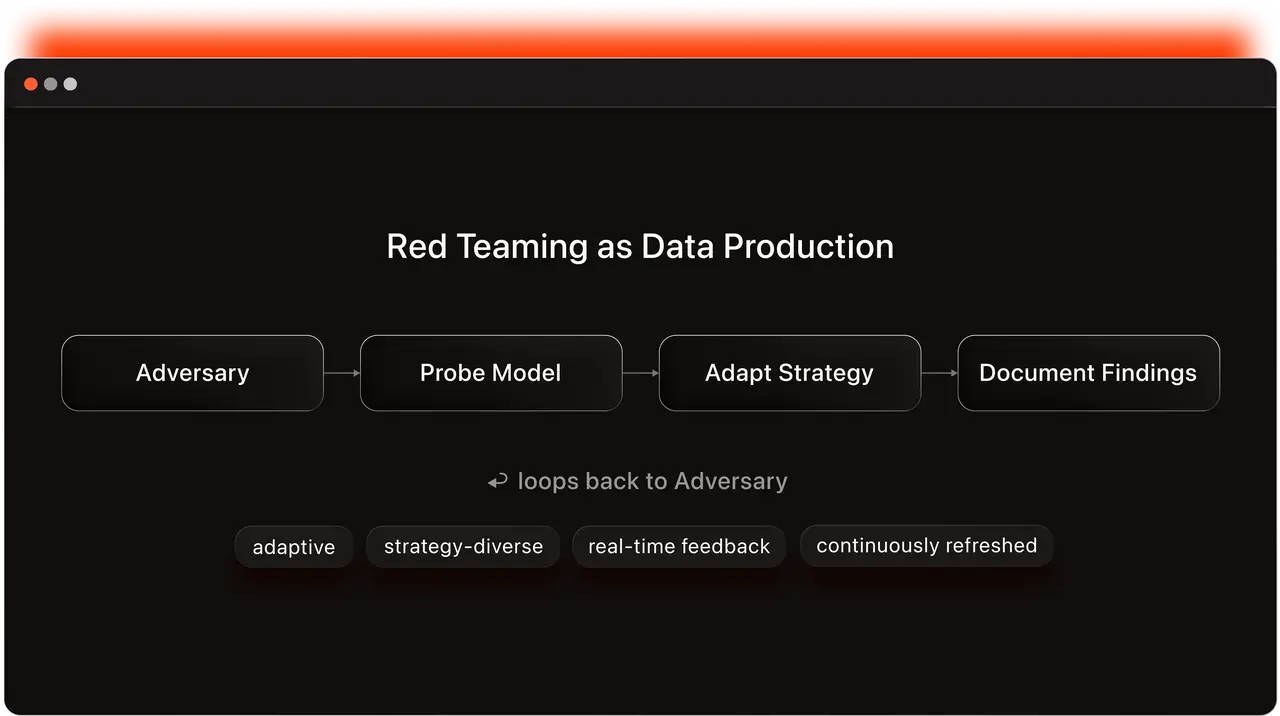
Red teaming is not labeling — it is generative. Adversaries probe a live model, adapt in real time, and produce failure cases that did not exist before the interaction. This process is an arms race — the adversarial search space is open-ended and effective red teaming requires understanding model internals (safety filters, refusal patterns, scoring heuristics, etc.). In particular, human and automated red teaming are complementary — humans routinely break models that automated methods rate as robust (Mazeika et al., 2024) — which demands a hybrid pipeline that leverages both. And serving multiple evaluation paradigms (RLHF training, regression testing, compliance documentation, etc.) calls for flexible infrastructure.
What is missing is not another benchmark. It is a continuous capability for producing, structuring, validating, and refreshing adversarial safety evaluation data. The requirements: strategy-structured, severity-graded, prevalence-calibrated, multi-turn, continuously refreshed, generated through human-AI hybrid adversarial interaction, and campaign-ready for targeted deployment. Together, these describe an operational capability — beyond a simple dataset.
Our Approach: Building AI Safety Evaluation Data
Abaka AI brings deep data engineering expertise — our annotation platform, global expert network, multi-layered quality assurance, and RLHF training data experience — to safety evaluation. We apply this infrastructure to the safety data problem through a three-layer approach.

Layer 1: Expert Adversarial Workforce
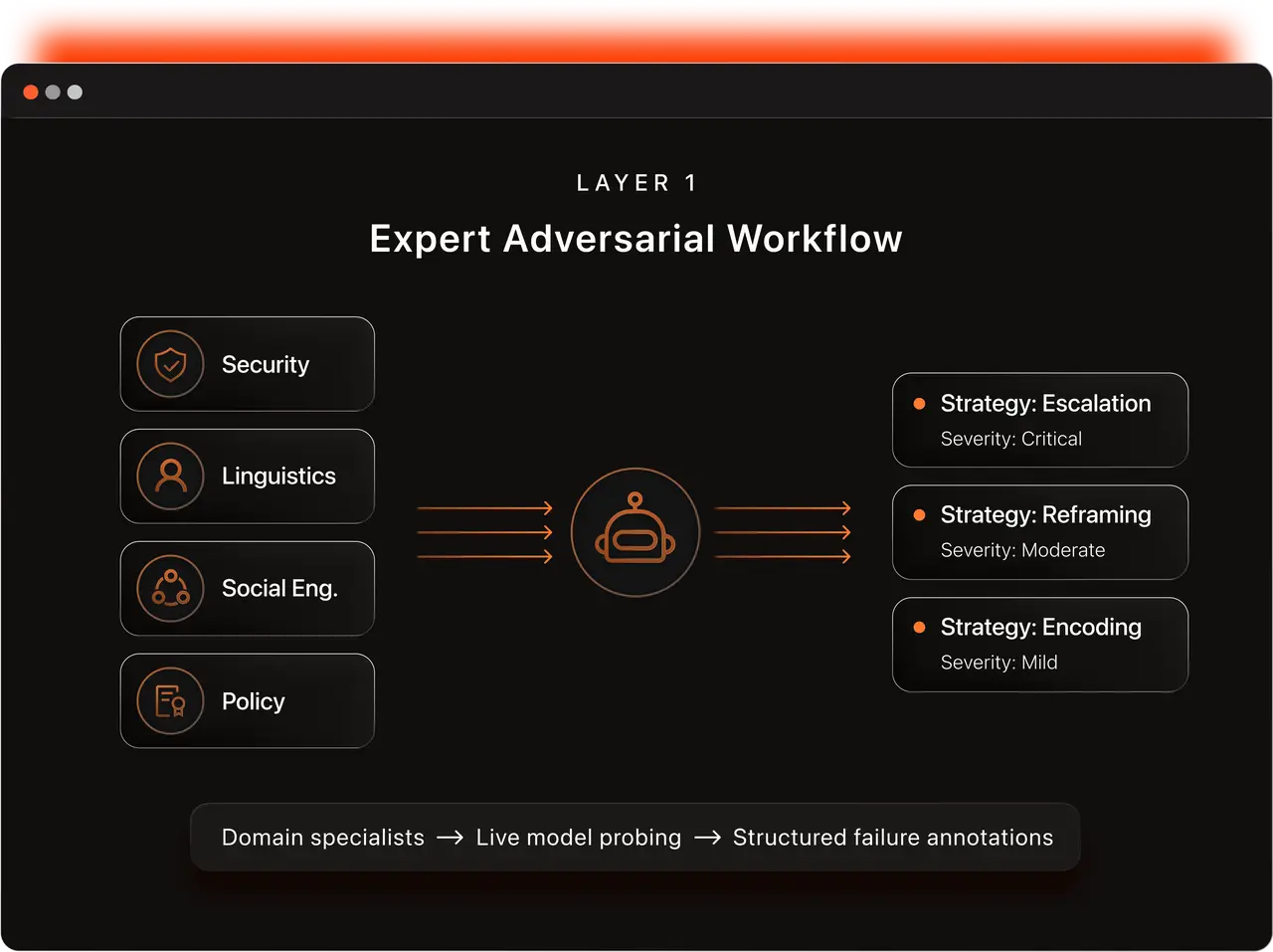
The foundation is domain-specialist red teamers sourced and managed through Abaka's annotation infrastructure. We recruit not general-purpose annotators but domain specialists — security researchers, linguists, social engineers, policy experts — vetted for cybersecurity certifications, linguistic expertise (low-resource languages), and biosafety backgrounds. Abaka's global annotator network provides the recruitment reach to source these specialists across regions and disciplines.
Each interaction is captured through a structured annotation schema that goes far beyond binary harm labels:
Attack strategy type — from an extended taxonomy: conditional misdirection, creative reframing, authority exploitation, incremental escalation, low-resource language translation, encoding-based attacks, role-play exploitation
Severity — graduated scale from mild to critical, prevalence-calibrated against real-world frequency data
Conversation trajectory — turn count, escalation arc, intermediate model responses at each turn
Failure mechanism — where exactly the model's safety broke down
Red teamer rationale — the reasoning and decision process behind each adversarial move
This granularity aims to transform red teaming from a pass/fail exercise into a rich data source for safety improvement.
Quality assurance applies Abaka's multi-layered QA, covering expert review, cross-validation, consensus labeling, and automated error detection. Delivery is flexible, we support campaigns for targeted evaluations, or ongoing embedded engagements with dedicated specialists working within a client's safety workflow. In practice, human-expert rubrics have been shown to outperform synthetic alternatives in driving RL training gains.
Layer 2: Synthetic Amplification Pipeline
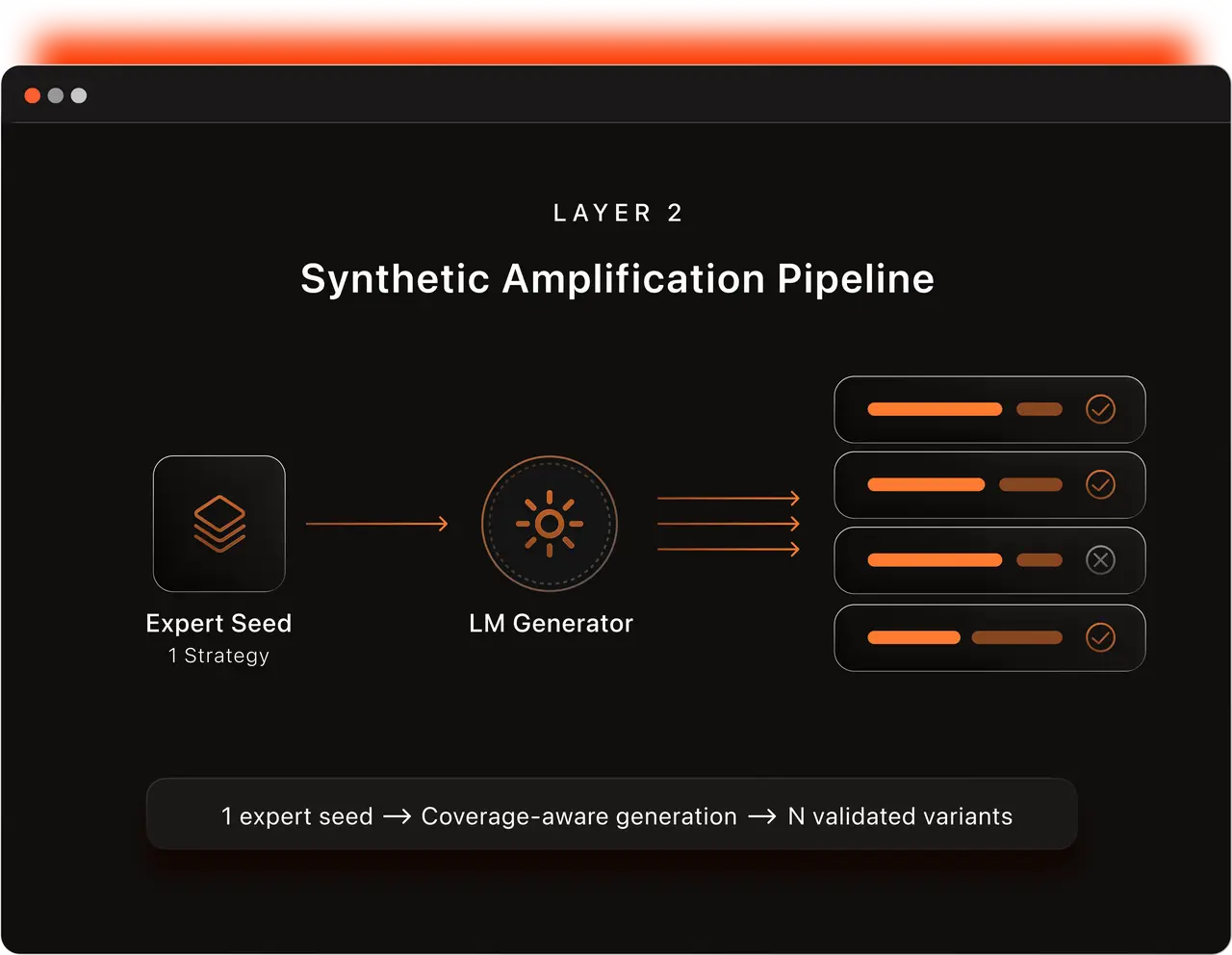
Expert-generated adversarial strategies are valuable but expensive to produce at volume. Layer 2 takes these high-quality seeds and scales them through an LM automated pipeline with human validation.
Say, a multi-turn escalation bypasses safety filters through incremental context-shifting — our pipeline generates hundreds of variants through multi-turn interactive generation, preserving the underlying adversarial logic across full conversation trajectories, not just single-prompt rephrasing. Generation is coverage-aware, mapping gaps across:
Strategy types — 7+ categories from conditional misdirection to role-play exploitation
Severity levels — ensuring representation from mild to critical
Harm categories — mapped to standard taxonomies
Languages and cultural contexts
Human-in-the-loop validation is essential. Automated screening removes duplicates, trivially detectable attacks, and severity mismatches. Expert red teamers then validate synthetic outputs for contextual realism, refine promising variants, and discard ones that are artificial or unrepresentative.
The pipeline is self-improving: each generation batch informs the next, with failed attacks providing diagnostic signals and refined filtering criteria propagating forward. Research demonstrates 90%+ ASR with quality-diversity synthetic generation approaches — but purely synthetic methods inherit generator biases (Samvelyan et al, 2024). Automation amplifies expert signal; it does not replace it.
Layer 3: Continuous Data Operations
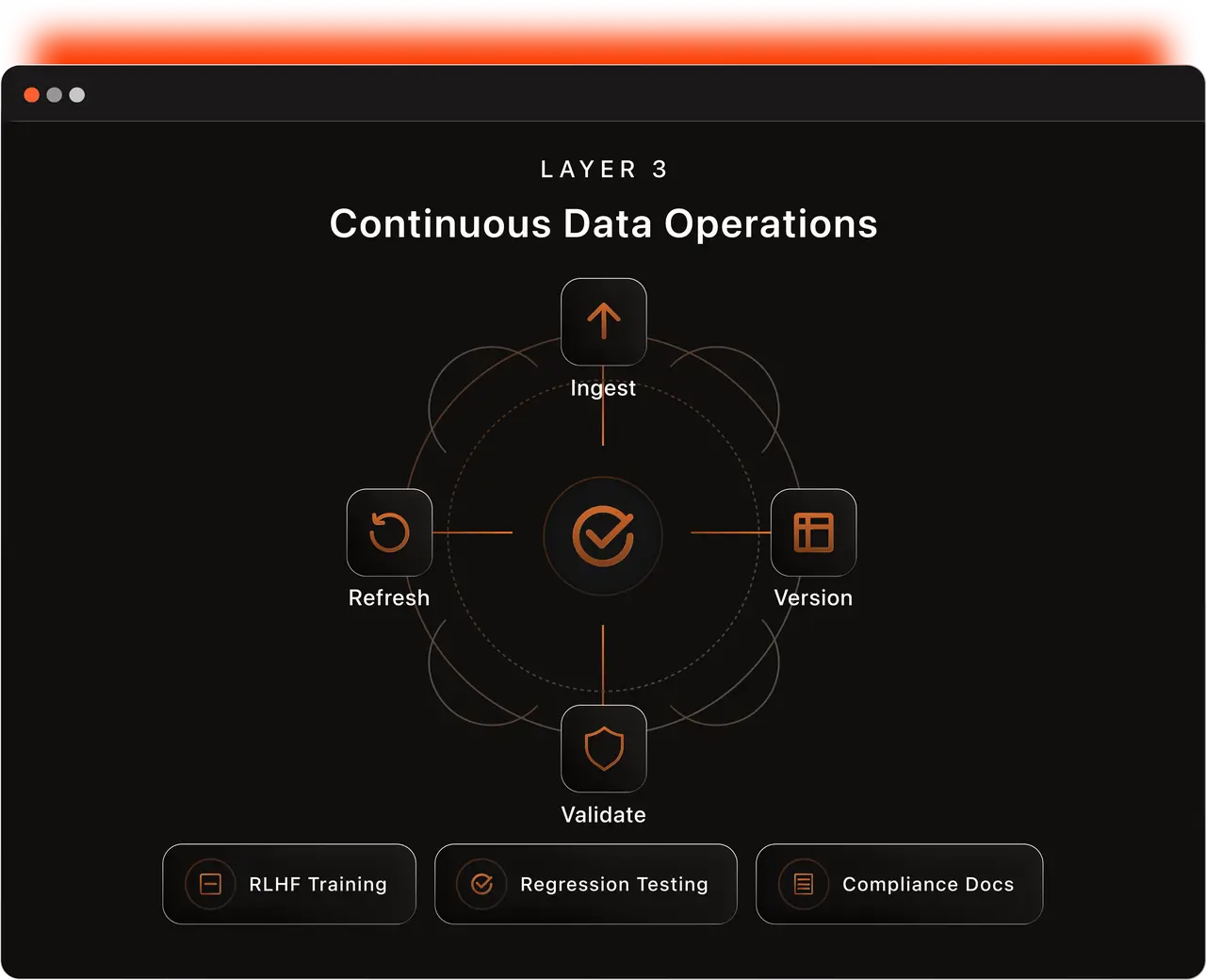
Safety evaluation data must be a living capability, not a static dataset. Layer 3 provides the operational infrastructure to sustain this.
Every red team interaction is logged with full trajectory: not just pass/fail, but the complete chain of strategy attempted, model response at each turn, where the red teamer adapted, and why. This level of granularity enables step-level reward shaping for RLHF safety training, fine-grained failure analysis to pinpoint where safety degrades within a conversation, and strategy-level aggregation into which adversarial approaches are most effective across model families.
Temporal versioning ensures each dataset carries metadata about generation date, model version tested, last validation date, contamination risk score. Stale test cases are flagged and cycled out, ensuring continued relevance and robustness to evolving red-teaming and jailbreak techniques.
Safety data is tagged by deployment context, so teams pull evaluation sets matched to their specific risk profile including but not limited to:
Sustained-pressure testing — persistent adversary threat models
Rapid-iteration testing — fast-patching workflows
Agentic safety testing — tool-use, code execution, and multi-agent deployments
This approach supports multiple evaluation paradigms, instead of collapsing them into a single standard that privileges one threat model over another. Our standard, integration-ready delivery for training and evaluation pipelines reflects an ongoing data service, not a one-time handoff.
The Future of AI Safety: From Benchmarks to Data Infrastructure
The EU GPAI Code of Practice (enforcement August 2026) requires documented adversarial testing evidence. Insurance "AI Security Riders" now require documented red teaming. The attack surface is expanding as models gain tool use, code execution, and autonomous action (tool poisoning, privilege escalation, cascading failures, etc.). Regulatory mandates and the expansion into agentic systems both converge on the same need — safety evaluation must cover what models do, not just what they say.
The field has built strong evaluation frameworks and mature attack tooling. What it has not built is the data layer to feed them — strategy-structured, severity-graded, continuously refreshed, generated through expert adversarial interaction. That is what we provide.
If you are building frontier models, training agents for enterprise deployment, or preparing for regulatory compliance, Abaka AI provides the safety evaluation data infrastructure to move from benchmark scores to operational safety assurance.
FAQs
What is AI safety evaluation data?
AI safety evaluation data is structured adversarial data generated through red teaming, used to test how models behave under harmful, ambiguous, or multi-turn scenarios.
How is red teaming different from standard AI evaluation?
Red teaming actively probes models with adaptive attacks to uncover failure modes, while standard evaluation relies on fixed prompts and predefined test cases.
What makes high-quality AI safety evaluation data?
High-quality safety data is multi-turn, strategy-structured, severity-graded, and continuously updated to reflect evolving attack patterns and real-world risks.
References
HarmBench — Mazeika et al., 2024 · https://www.emergentmind.com/topics/harmbench-framework
Li et al., LLM Defenses to Multi-Turn Human Jailbreaks, 2024 · https://arxiv.org/abs/2408.15221
Samvelyan et al., Rainbow Teaming, 2024 · https://arxiv.org/abs/2402.16822
Yu et al., 2026 meta-analysis · https://arxiv.org/html/2601.23112v2
OpenAI & Anthropic joint evaluation, 2025 · https://openai.com/index/openai-anthropic-safety-evaluation/
VentureBeat: Red Teaming LLMs, 2025 · https://venturebeat.com/security/red-teaming-llms-harsh-truth-ai-security-arms-race
UK AISI Frontier AI Trends, 2026 · https://www.grayswan.ai/blog/uk-aisi-x-gray-swan-agent-red-teaming-challenge-results-snapshot
Intent Laundering — Golchin & Wetter, 2026 · https://arxiv.org/html/2602.16729v1
EU GPAI Code of Practice · https://artificialintelligenceact.eu/code-of-practice-overview/
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.