AI Generated vs Real Image Data sets: What Matters for Training
Jessy Abu Khalil,Director of Sales Enablement
Compare AI generated vs real image datasets for model training. Learn their strengths, limitations, and how to combine them for optimal results
AI Generated vs Real Image Datasets: What Matters Most in Model Training?
💡 The best approach is combining both real and AI-generated image datasets. Real data ensures authenticity and trust, while AI-generated images offer scale and coverage of rare cases. For optimal AI performance, use a hybrid strategy—Abaka AI provides expert solutions to help you balance, build, and validate both types of image datasets.
An image dataset is a curated collection of labeled images used to train machine learning models. But not all image datasets are created the same. Real image datasets are sourced from cameras, smartphones, satellites, surveillance systems, and crowdsourced content. Examples include ImageNet, COCO, and Open Images. AI generated image datasets are created using generative models like DALL•E, Midjourney, or Stable Diffusion. These images may not exist in the real world but are synthesized from prompts or training data.
Real photo vs AI-generated photo
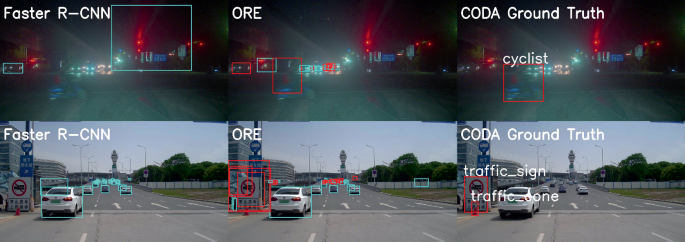
Both dataset types have their place, but choosing between AI generated vs real image datasets depends on the context of the model you're building. Real image datasets bring authenticity, capturing real-world noise, lighting, occlusions, and variability. They are also more trustworthy for high-risk applications like medical imaging or autonomous driving, as they reflect actual distributions and edge cases in deployment environments.
Real-world image edge cases
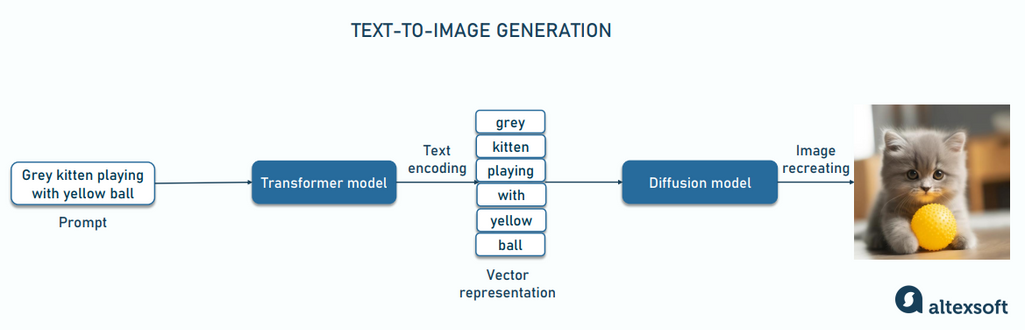
However, real images come with challenges such as licensing restrictions, privacy risks, and being time-consuming and expensive to collect and annotate. On the other hand, AI generated image datasets offer scalability, cost-efficiency, and greater control. You can generate thousands of diverse samples instantly, customize scenes, lighting, poses, or fabricate rare situations that are difficult to capture in real life.
Prompt-to-image pipeline
These datasets are especially useful for synthetic environments, bootstrapping new domains with limited real data, and testing model robustness against unusual scenarios. But they too have limitations: there's a risk of domain gap (a mismatch with real-world distributions), biases inherited from the generating model, and a lack of genuine noise and texture variation.
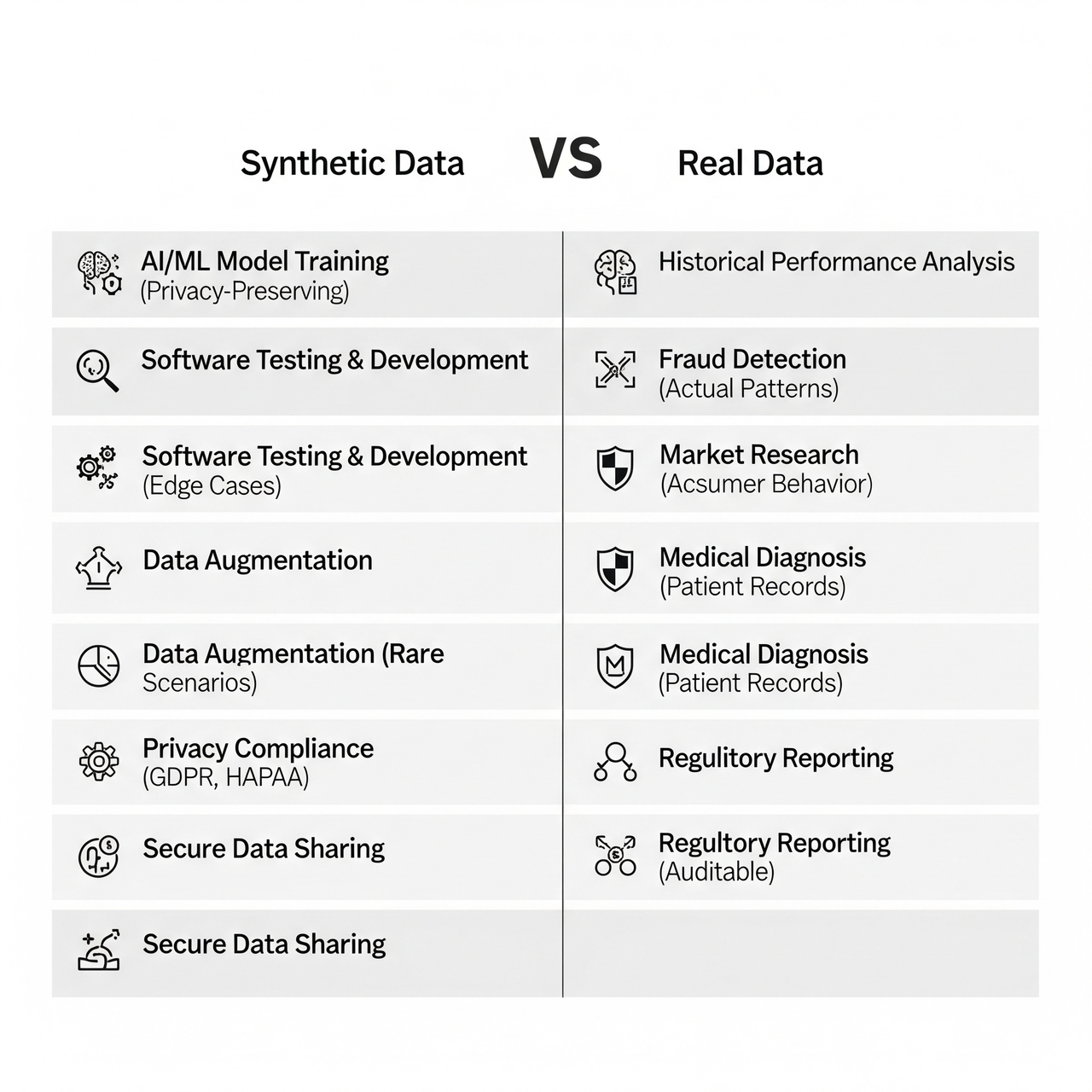
So when should you use AI generated vs real image datasets? For safety-critical applications like medicine or autonomous vehicles, real data is essential. For rapid prototyping or early-stage training, AI-generated images help you scale quickly. They're also ideal for modeling rare events or edge cases, while real data remains key for final testing and deployment. In multimodal learning (paired with text or audio), both types are often necessary.
Dataset type by use case
The smartest approach is to use hybrid datasets: AI generated image datasets to scale quickly and cover edge cases, and real image datasets to validate and calibrate models with authentic signals. At Abaka.ai, we help clients generate synthetic datasets using detailed prompts and domain-specific guidelines, curate real datasets from licensed sources, and blend them into seamless pipelines with annotation, QA, and performance tracking.
When it comes to AI generated vs real image datasets, it’s not a matter of which is better universally—it’s about knowing when and how to use each. Real image datasets offer realism and trust, while AI generated image datasets bring flexibility, scale, and control. The best-performing models often learn from both. Whether you're building perception models, LLM vision extensions, or simulation-ready pipelines, the data you start with will shape everything that comes after.
Want to learn more about how we build multimodal, licensed, and hybrid datasets? Contact us or request a demo.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.