Agent Datasets: The Backbone of AI Assistant Training
Jessy Abu Khalil,Director of Sales Enablement
What are agent datasets (dialogue logs, interaction flows)? Understand their crucial role in AI assistant training, key challenges, and quality standards. See how Abaka AI expertly collects and cleans task-oriented interaction data.
Agent Datasets: The Backbone of AI Assistant Training
In the rapidly evolving landscape of Artificial Intelligence, AI assistants are becoming increasingly integral to how businesses interact with customers and streamline internal processes. From handling customer queries to automating complex workflows, the potential of intelligent agents is vast. However, the true power and reliability of these AI assistants hinge on a critical element: agent datasets.
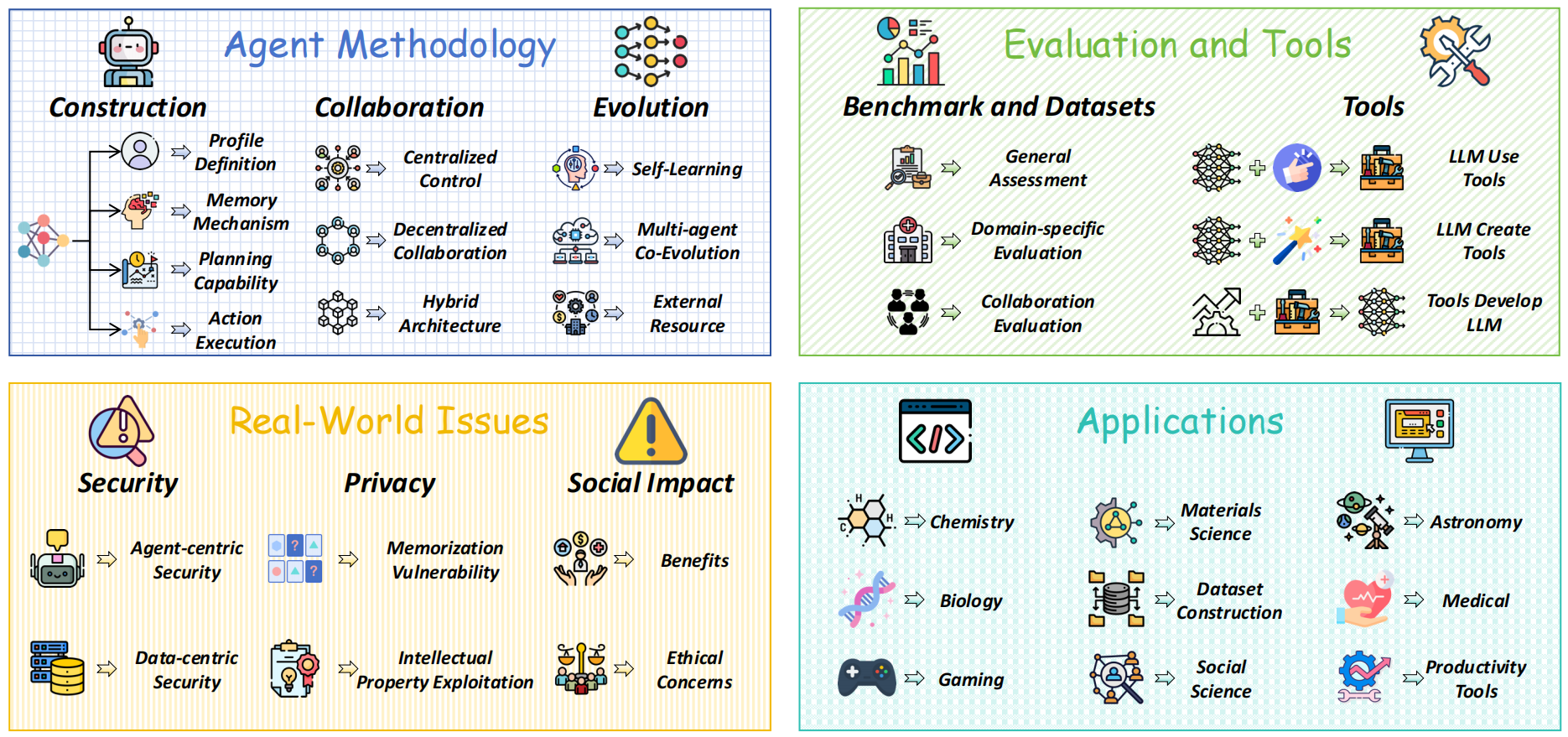
A Comprehensive of Large Language Model Agent
Agent dataset, voice agent training data, and GenAI ML data are the foundational building blocks that enable AI assistants to learn, understand, and respond effectively. Without high-quality data, even the most sophisticated AI models will falter, leading to inaccurate responses and frustrating user experiences.
1. What Exactly Are Agent Datasets?
At their core, agent datasets comprise collections of information that AI models use to learn how to behave and interact in specific contexts. These datasets can take various forms, including:
Dialogue Logs: Records of conversations between humans and AI assistants or between two humans simulating an AI interaction. These logs capture the nuances of language, intent, and conversational flow.
Interaction Flows: Structured representations of how a typical interaction with an AI assistant should unfold for specific tasks. This includes the steps involved, potential user inputs, and expected system responses.
Task-Oriented Data: Specific examples of users trying to accomplish particular goals, along with the correct actions and information the AI assistant should provide.
The richness and diversity of an agent dataset directly impact the AI assistant's ability to generalize and handle a wide range of user requests and scenarios.
2. Navigating the Challenges and Upholding Quality Standards
High-quality Datasets
Building effective agent datasets is not without its challenges. Several factors can compromise the quality and utility of the data:
Data Scarcity: Acquiring sufficient amounts of real-world interaction data can be difficult, especially for niche applications.
Data Noise and Inconsistency: Raw interaction data often contains errors, irrelevant information, and inconsistencies in language and format.
Bias: Datasets can inadvertently reflect existing biases in language or behavior, leading to AI assistants that are unfair or discriminatory.
Lack of Standardization: The absence of universal standards for data collection and annotation can hinder the development of robust and interoperable AI models.
To overcome these hurdles, rigorous quality standards are paramount. High-quality agent datasets should be:
Relevant: Directly aligned with the tasks the AI assistant is intended to perform.
Comprehensive: Covering a wide range of potential user intents and scenarios.
Accurate: Free from errors and reflecting real-world interactions truthfully.
Diverse: Representing a variety of users, languages (if applicable), and interaction styles.
Well-Annotated: Clearly labeled and structured to facilitate effective machine learning.
3. Abaka AI: Building High-Quality, Competitive Agent Datasets
At Abaka AI, we understand that agent datasets are not just collections of data points; they are the very foundation upon which successful AI assistants are built. We are committed to constructing high-quality, competitive datasets that empower businesses to deploy truly intelligent and reliable AI solutions.
Our approach to building exceptional agent datasets focuses on:
Strategic Data Collection: We employ a variety of methods to gather task-oriented interaction data relevant to specific business needs. This includes leveraging existing customer interactions (with appropriate anonymization and consent), conducting simulated dialogues with trained human agents, and utilizing synthetic data generation techniques where appropriate.
Rigorous Data Cleaning and Preprocessing: Our expert data science team implements stringent data cleaning processes to identify and remove noise, inconsistencies, and errors. This ensures that our voice agent training data and GenAI ML data are accurate and ready for model training.
Human-in-the-Loop Annotation: For complex tasks requiring nuanced understanding, we employ skilled human annotators to label and structure the data. This human oversight ensures the accuracy and consistency necessary for effective learning.
Focus on Task Orientation: We prioritize the collection and curation of data that directly supports the specific tasks our AI assistants are designed to handle. This targeted approach ensures that our agent datasets are highly effective for training models that can achieve real business outcomes.
By focusing on quality, relevance, and rigorous processes, Abaka AI equips businesses with the agent datasets necessary to build and deploy AI assistants that are not only intelligent but also truly competitive in today's market. Investing in high-quality voice agent training data and GenAI ML data is the key to unlocking the full potential of AI and delivering exceptional user experiences.
Ready to build a powerful AI assistant with a competitive, high-quality agent dataset? Contact Abaka AI today to learn more.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.