
From VeriGUI to Trustworthy Agent Data: Abaka AI’s Practice
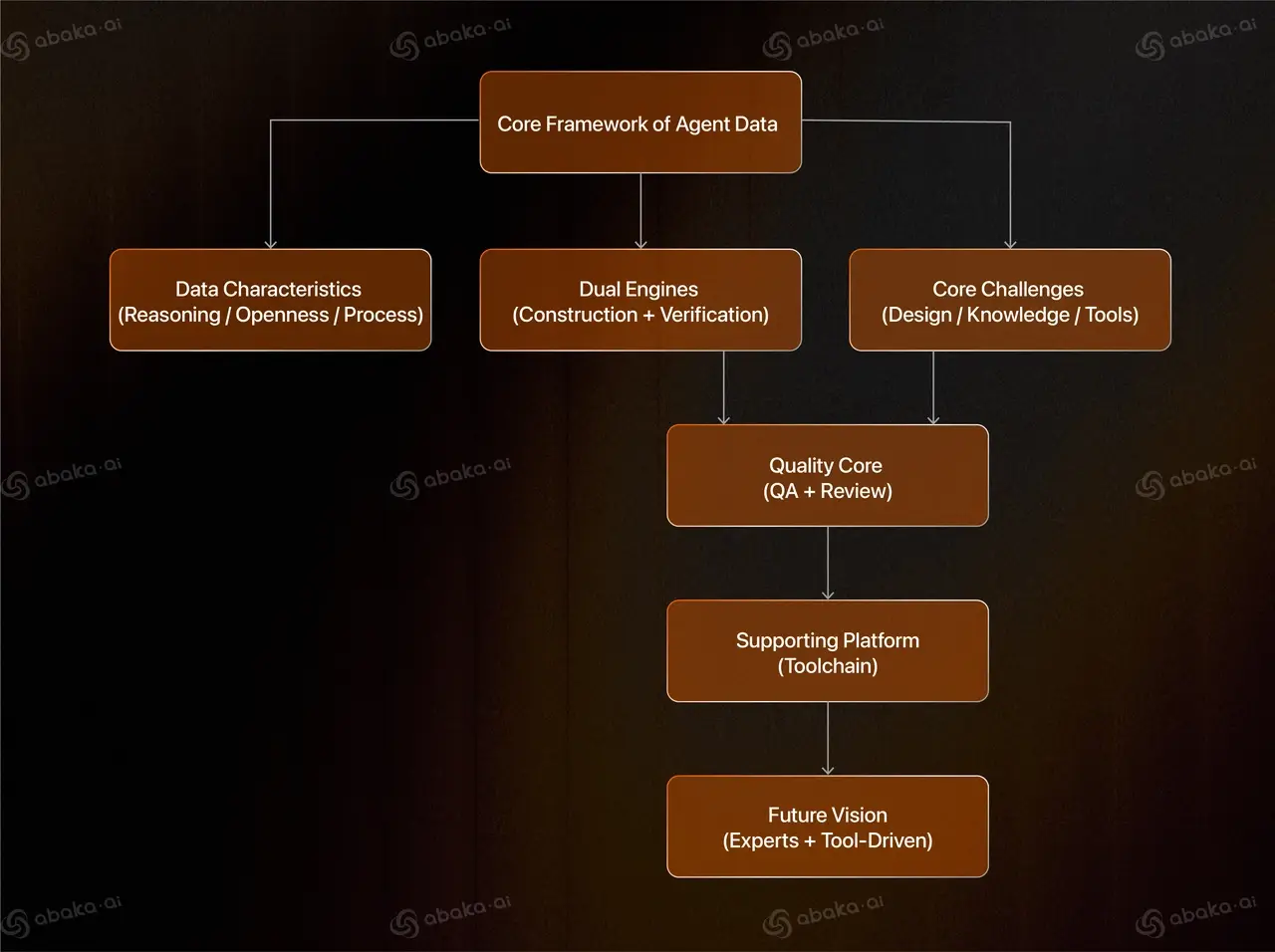
As AI systems move toward agent capabilities, the demand for agent-centric data has never been greater. At Abaka AI, our VeriGUI project tackles this challenge by combining scalable task construction with rigorous, multi-layer quality assurance. Unlike traditional NLP datasets, agent data must capture multi-step reasoning, open-ended decision-making, and transparent processes. Our pipeline integrates strategies such as real-world task transformation, backward design, and adversarial review, supported by purpose-built QA platforms. The result is data that is both challenging and trustworthy.
As AI systems evolve into capable agents, the demand for agent-centric data has skyrocketed. Unlike traditional NLP datasets, agent data must capture reasoning chains, complex decision-making, and authentic interactions.
At Abaka AI, our VeriGUI project explores exactly this frontier: not only setting standards for what agent data should look like but also building scalable production pipelines that bring high-quality agent data beyond small-scale lab research into true industrialization.

What Makes Agent Data Different?
Conventional NLP datasets often focus on closed tasks such as classification, Q&A, or summarization, with relatively simple evaluation methods. Agent data, however, is designed to enable models to perform complex operations in real-world contexts, giving it several defining characteristics:
- Reasoning is multi-step:
Agent tasks rarely end in one step. They require the model to jump between pieces of information, connect them logically, and verify correctness. For example, a model may need to search across multiple candidate answers and then validate them through a reasoning chain. The dataset must therefore include not only the final results but also the explicit thought process. - Tasks are open-ended:
Not every task has a single correct answer. Choosing the “best route” or recommending a “viable plan” may yield multiple valid solutions. Agent data must capture this open space, allowing models to explore while remaining logically coherent—rather than producing templated responses. - Process over outcome:
In agent tasks, transparency, reproducibility, and coherence of the reasoning process matter more than simply “getting the right answer.” A model that produces the correct output without an interpretable process cannot support future agent applications.
To meet these requirements, agent data must combine creativity, logical rigor, and verifiability. It is not just a pile of text—it is the fuel that enables models to act more like humans.
From Construction to Validation: A Dual-Engine Pipeline
Our practice has converged on a two-stage pipeline: task construction and quality assurance (QA) validation.
- Task construction:
We explored multiple strategies:
Each approach has its strengths: large-scale coverage, authenticity, or difficulty control.
- Quality validation:
The validation process is equally complex. We designed a multi-stage QA system that includes:
This dual-engine workflow enables both scalability and depth, ensuring trustworthy datasets.
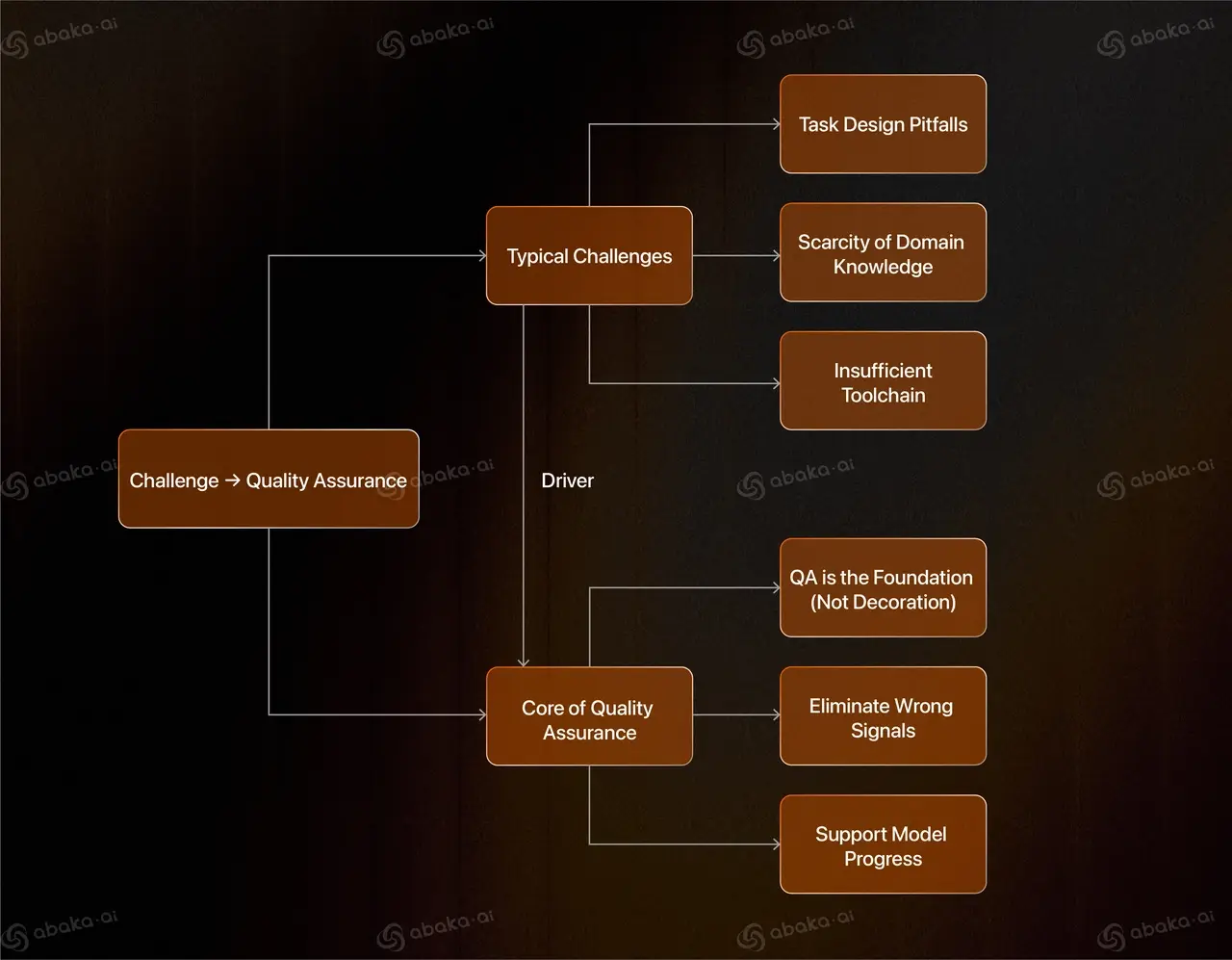
Challenges Along the Way: More Than Just Engineering
Building agent data is itself a research problem. We repeatedly face three recurring challenges:
- Task Design Pitfalls: Problems that seem reasonable on paper can turn out to be unanswerable or require impractically large searches. This demands a rigorous validation mechanism in the design phase, rather than relying on intuition.
- The Scarcity of Human Expertise: As tasks become more complex, the need for specialized knowledge grows. Medical or legal reasoning tasks, for example, may exceed the capabilities of general annotators. We've had to bring in domain experts and develop more robust training protocols.
- Immature Tooling: The tools for data production often lag behind the complexity of the tasks. We need platforms that support multi-step annotation, interactive reasoning logs, and collaborative review, all of which have required iterative development.
Ultimately, we argue that producing agent data is a scientific exploration, not an assembly-line project.
Why Quality Assurance Is Core
Agent data is fundamentally different from traditional NLP benchmarks due to its complexity and open-ended nature. This is why QA cannot be an afterthought—it must be central to the entire process.
If ambiguous instructions, fabricated answers, or hidden logical flaws are allowed into the dataset, the evaluation signal is weakened. This can lead to models that appear more or less capable than they truly are. In other words, low-quality data isn't just useless; it can actively misdirect the research field.
At Abaka AI, we define QA as the foundation of data production, not a final touch-up.
A Multi-Layered Review Process
To ensure reliability, we've designed a layered review pipeline. Each task and its corresponding solution passes through multiple rounds, often involving different reviewers or teams:
- Instruction review – ensuring clear, well-posed tasks.
- Formal validation – checking answers for consistency and relevance.
- Content verification – grounding answers in real evidence, not assumptions.
- Adversarial review – reviewers challenge or attempt to overturn existing answers.
- Final acceptance – an internal audit akin to peer review before release.
Even at the final stage, tasks may be sent back for revision. This iterative loop is slow but the only way to guarantee progress.
Platforms and Tools: The Bedrock of Expert Review
A rigorous QA process depends on the right infrastructure. We've built and refined a dedicated platform to help experts work more efficiently and consistently. Key features include:
- Structured Workflows: Guiding reviewers step-by-step to avoid missing crucial checks.
- Automated Checks: Handling common, low-level errors so experts can focus on higher-level judgments.
- Multi-Role Collaboration: Allowing reviewers with different backgrounds to compare and discuss reasoning paths in real-time.
- Scalability and Traceability: Ensuring that even across hundreds of review cycles, every change is tracked and explainable.
These tools have been continuously improved based on expert feedback, resulting in a review system that is not only faster but also more transparent and defensible.
Raising the Bar for Agent Data
Our experience with developing VeriGUI has made one thing clear: QA is the true bottleneck in producing high-quality agent data. But this is a strength, not a weakness. A bottleneck implies value; it means the quality bar is high and continually rising.
As models become more advanced, tasks will only grow more complex, and the demands on reviewers and platforms will increase in parallel. We believe that combining skilled human experts with purpose-built tools is the only way to create datasets that are both challenging and trustworthy.
At Abaka AI, our vision is clear: without rigorous QA, there can be no reliable progress.
Open-Source & Easy Start
We have fully open-sourced VeriGUI to make it more accessible for the research community.
- GitHub Repository: https://github.com/VeriGUI-Team/VeriGUI
- Hugging Face Dataset: https://huggingface.co/datasets/2077AIDataFoundation/VeriGUI
The dataset can be easily loaded with thedatasetslibrary, allowing researchers to start experiments quickly. - Arxiv Paper: https://arxiv.org/abs/2508.04026
For details about our experimental process and dataset construction, please refer to our paper.
The VeriGUI project is still in progress. We are actively expanding the dataset, with future versions expected to include more interaction-focused web tasks (e.g., form filling, account login) as well as complex desktop software operation tasks.
Abaka AI will continue to support open research and collaboration in this area, and updates will follow as the dataset evolves.For collaboration or further information, please Contact our data specialist .