

Data cleaning is a foundational step in every data-driven project, ensuring that raw information is accurate, consistent, and ready for analysis. In machine learning, clean data directly impacts model performance, as poor-quality inputs lead to unreliable outputs. The challenge is that datasets collected from real-world sources—such as websites, sensors, or user interactions—are often riddled with missing values, duplicates, or formatting inconsistencies. By combining automated tools with human oversight, modern data cleaning workflows make it possible to transform noisy datasets into reliable assets for training and decision-making.
What Is Data Cleaning and Why It Matters for AI Projects
What Is Data Cleaning?
Data cleaning is the process of detecting, correcting, and removing inaccurate or incomplete records from datasets so they can be used reliably in analytics or machine learning. In practice, this means fixing typos, removing duplicates, normalizing formats, and validating values across millions of rows. Clean data ensures consistent input for AI models, which leads to more trustworthy predictions across industries such as healthcare, finance, retail, and autonomous systems.
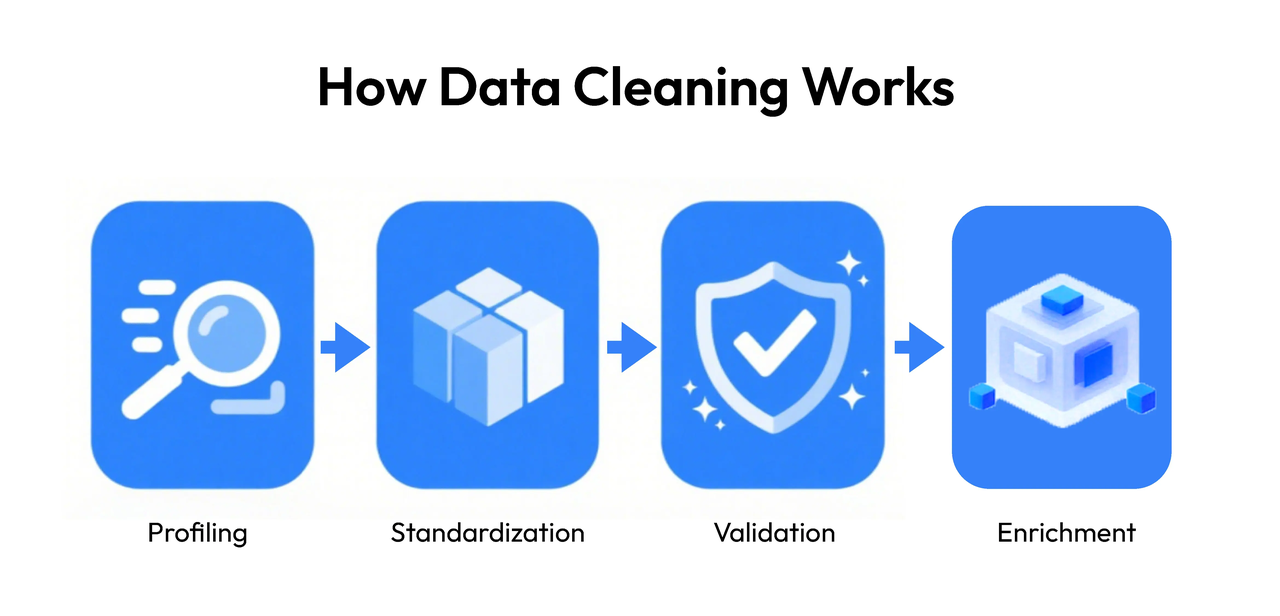
How Data Cleaning Works
The data cleaning workflow typically begins with data profiling—scanning datasets to identify errors, missing values, or inconsistencies. Next, standardization and transformation ensure data follows a uniform format, such as date conventions or numeric ranges. Finally, validation and enrichment enhance datasets with contextual accuracy, making them ready for modeling.
At ABAKA AI, automation tools are combined with human expertise to deliver precise results. For instance, AI scripts can flag 95% of duplicates, while human reviewers handle complex edge cases like ambiguous values or mislabeled categories.
Cutting Costs with Automated Data Cleaning
Manual data cleaning requires thousands of hours of tedious review, making it one of the most expensive steps in data preparation. By using automation to handle repetitive corrections, businesses can reduce the need for manual work while improving efficiency.
For example, a dataset with 5 million entries might take weeks for a team to clean manually. With automation, the process can be shortened to days, reducing costs by up to 60–70%. Human experts then review only the most complex cases, ensuring quality while keeping expenses low.
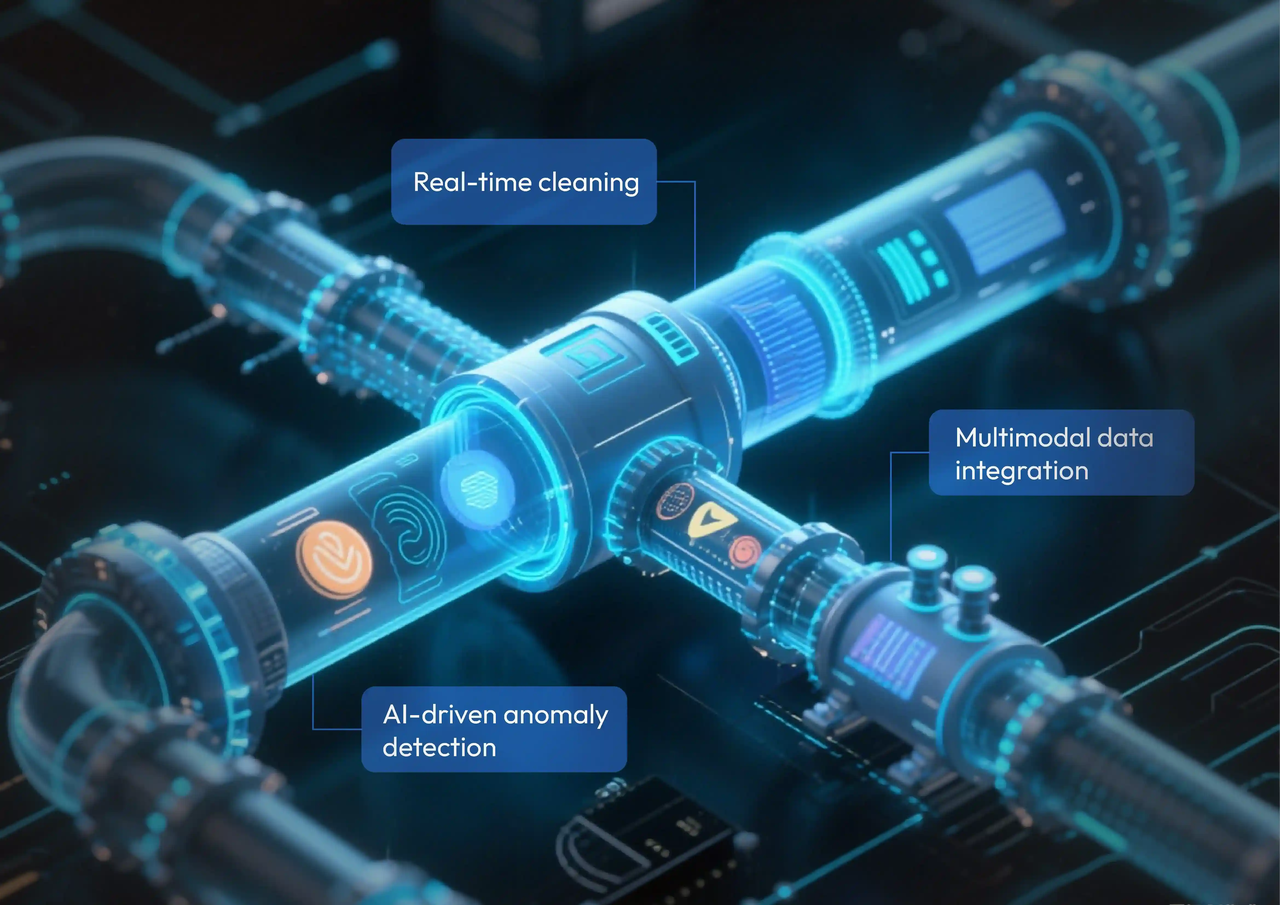
Advanced Trends in 2025
Data cleaning is evolving beyond traditional error detection. In 2025, new techniques are emerging:
Real-time cleaning ensures that streaming data from IoT and sensors is processed instantly.
Multimodal data integration links text, images, and audio to build richer, cross-format datasets.
AI-driven anomaly detection spots outliers with higher precision, minimizing bias in training data.
ABAKA AI is at the forefront of these innovations, providing scalable solutions that adapt to different industries and data types.
Why Partner with ABAKA AI
Managing data cleaning internally can be overwhelming, leading to bottlenecks and inefficiencies. ABAKA AI eliminates these challenges by offering:
Fully licensed, pre-cleaned datasets.
Automated pipelines with advanced quality assurance.
Multilingual teams experienced in diverse industries.
Transparent dashboards for monitoring progress in real time.
By merging AI-powered automation with expert human oversight, we help clients accelerate AI deployment while ensuring high-quality outcomes.
Get Started Today
Need reliable, ready-to-use datasets for your next AI project? From cleaning financial transaction logs to standardizing healthcare records, we’ve delivered it before.
📩 Contact us to explore our cleaned datasets or request a custom data cleaning solution. Let’s build smarter AI together☺️
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.