Talking-Head Video Data: Core for Multimodal AI’s Speaking Skills
Talking-head video data, featuring highly synchronized speech and visual streams, is a crucial resource for training multimodal AI models in areas such as AIGC and digital humans. It supports core tasks like speech synthesis (TTS), video understanding, and talking head generation. Although public datasets such as AVSpeech, CelebV-HQ, and VoxCeleb exist, they often fail to meet the stringent demands of high-quality commercial model training. To bridge this gap, Abaka AI offers a comprehensive solution for high-quality talking-head video dataset construction, encompassing meticulous data collection, multi-stage filtering, AI-assisted screening, and manual review. The company provides specialized datasets—ranging from real-person and singing videos to dialogue interactions—along with tailored collection and annotation services to enable the development of more intelligent, vivid, and lifelike AI applications.
Talking-Head Video Data: A Must-Have for Multimodal AI’s “Speaking Skills”
What Is Talking-Head Video Data?
As multimodal large language models (LLMs) advance at a record speed, talking-head videos — where audio and visuals are tightly synchronized — are emerging as a vital training resource. These videos typically feature a presenter, news anchor, or influencer speaking directly to the camera. They can be live-action footage or AI-generated digital humans and animated characters, characterized by clear semantics, standardized delivery, and perfect lip-audio alignment.
As a structured, high-correlation multimodal data format, talking-head videos are widely used in multimodal pre-training, text-to-speech (TTS), automatic speech recognition (ASR), video understanding, lip-sync generation, and talking-head generation. Key technology areas include photorealistic and stylized digital human synthesis, audio-driven lip and facial expression modeling, emotional expression control, audio-video alignment, and cross-modal pre-training.
Notable models include Wav2Lip, AV-HuBERT, Vtoonify, EMO, LAVISH, and Uni-AV, which target lip-sync, style transfer, emotion-driven generation, and multimodal modeling. These form the technical backbone for digital human talking-head production, enabling AIGC content creation, virtual human interaction, education & training, and film production.
Publicly Available Talking-Head Video Datasets
To support research and model training, the AI community has built and open-sourced numerous talking-head video datasets, typically featuring precise audio-video alignment, accurate subtitles, and clearly identified speakers. Some notable datasets include:
AVSpeech
Introduction: AVSpeech is a large-scale audiovisual dataset containing speech clips without interfering background signals. These clips vary in length, between 3 and 10 seconds, and in each clip, the only visible face in the video and the audible voice in the soundtrack belong to a single speaker. The dataset contains a total of approximately 4,700 hours of video clips, with about 150,000 distinct speakers, covering a wide variety of people, languages, and facial poses.
Introduction: CelebV-HQ contains 35,666 video clips, involving 15,653 identities and 83 manually labeled facial attributes covering appearance, action, and emotion. Researchers have conducted comprehensive analysis of this dataset in terms of ethnicity, age, brightness, motion smoothness, head pose diversity, and data quality to demonstrate the diversity and temporal consistency of CelebV-HQ. Furthermore, its versatility and potential have been validated in unconditional video generation and video facial attribute editing tasks.
Introduction: CelebV-Text comprises approximately 70,000 natural face video clips featuring real individuals, covering rich visual content. Each video clip is paired with 20 text descriptions generated by a proposed semi-automatic text generation strategy, which can accurately describe the static and dynamic attributes of the video. A comprehensive statistical analysis of CelebV-Text's video, text, and text-video relevance has been conducted, verifying its advantages over other datasets. In addition, extensive self-evaluation has been performed to demonstrate the effectiveness and potential of CelebV-Text. Furthermore, a benchmark containing representative methods has been built to standardize the evaluation of the face text-to-video generation task.
Introduction: This dataset was collected from YouTube and contains about 16 hours of 720P or 1080P video. Instead of directly learning the audio-to-video mapping, researchers used a 3D Morphable Model (3DMM) of the face to divide the framework into two cascaded modules.
Introduction: The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) contains 7,356 files (total size: 24.8 GB). The dataset includes 24 professional actors (12 female, 12 male), who utter two lexically-matched statements in a neutral North American accent. Speech includes calm, happy, sad, angry, fearful, surprised, and disgusted expressions, and song contains calm, happy, sad, angry, and fearful emotions. Each expression is produced at two levels of emotional intensity (normal and strong), with an additional neutral expression. All expressions are available in three modality formats: audio-only (16-bit, 48kHz, .wav), audio-video (720p H.264, AAC 48kHz, .mp4), and video-only (no sound). Actor_18 has no song files.
Introduction: The Multi-view Emotional Audio-visual Dataset (MEAD) is a video corpus of talking faces, featuring 60 actors speaking with eight emotions at three different intensity levels. Researchers captured high-quality audiovisual clips from seven different viewpoints in a strictly controlled environment. Along with this dataset, researchers have also released a baseline for emotion-controllable talking face generation that can manipulate both the emotion and its intensity simultaneously. This dataset can benefit many different research areas, including conditional generation, cross-modal understanding, and expression recognition.
Introduction: VoxCeleb is an audiovisual dataset consisting of short clips of human speech, extracted from interview videos sourced from YouTube. The dataset has two versions, VoxCeleb1 and VoxCeleb2. VoxCeleb1 contains over 150,000 utterances from 1,251 celebrities, while VoxCeleb2 contains over 1,000,000 utterances from 6,112 celebrities.
While public datasets are valuable, they rarely meet the diverse, high-quality needs of large-scale model training and commercial deployment. Abaka AI leverages its expertise in multimodal data production and processing to deliver a complete talking-head dataset solution.
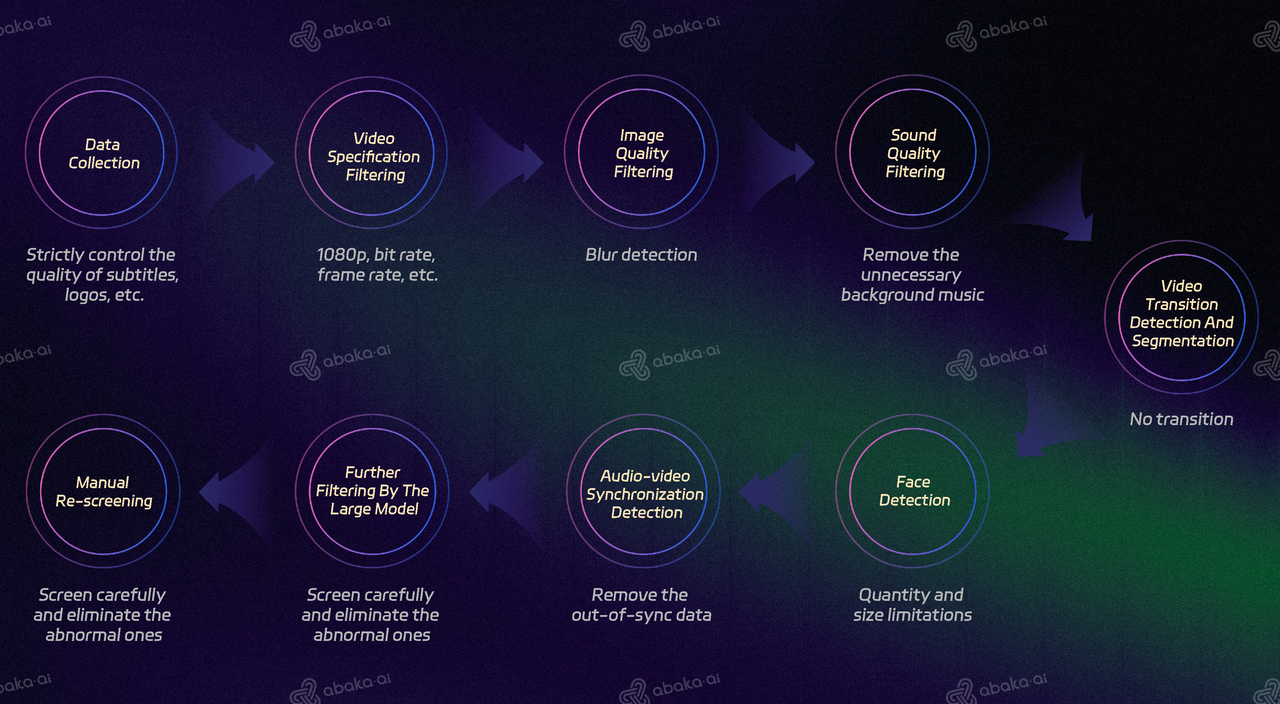
Abaka AI’s Oral Broadcast Dataset Pipeline
Our workflow includes:
Data Collection – Combining public and in-house recorded data (with full subject consent) across diverse settings, languages, age groups, and ethnicities. Multi-camera setups capture multiple angles under varied lighting conditions.
Data Cleaning & Segmentation – Removing substandard footage, cutting long videos into seamless short clips, filtering by face count and position to ensure consistency.
Standardization & Quality Control – Unifying encoding formats, enforcing annotation standards, and applying automated and manual quality checks for accuracy, completeness, and diversity.
Annotation – Adding metadata (speaker attributes, scene type, language), transcripts, audio-video synchronization, emotion labels, and lip-shape classification.
Featured Talking-Head Datasets at Abaka AI
Abaka AI offers a rich, high-quality portfolio of talking-head video datasets that span multiple scenarios, styles, and languages, including:
Real-Person Oral Videos: Diverse in gender, age, and language; recorded from multiple angles, including front and side views; spanning numerous domains and content types, totaling thousands of hours.
Real-Person Singing Videos: Covers various music styles and emotional expressions; clear vocal recordings and stable visual quality.
Anime Oral Videos: Carefully curated clips featuring well-lit facial imagery and high-fidelity audio; spans multiple styles and character types, with high-quality audio and visuals.
Dual-Speaker Oral Videos: Includes formats such as interviews, Q\&As, and debates with natural speech interaction, clear audio, low overlap, and realistic content.
All datasets undergo rigorous filtering and enhancement to ensure multi-language, multi-angle, and multi-scene diversity. We also offer custom data collection and annotation services, with options such as:
Age Coverage: From children and teens to older adults—meeting cross-age modeling needs for voice and facial behavior.
Multilingual and Dialectal Diversity: Support for Mandarin, Cantonese, English, and regional accents—enhancing multilingual model training and generalization.
Speaker Diversity: Inclusive of various genders and skin tones, improving dataset diversity and representativeness.
Diverse Collection Scenarios: Indoor/outdoor recordings under different backgrounds and lighting conditions; customizable scripts simulating contexts like classroom teaching, customer service, and medical inquiries.
Precision-Controlled Annotation: Annotation options include A/V alignment, speech transcription, phoneme labeling, lip shape classification, keypoint tracking, emotion classification, and 3D facial parameters.
In summary, talking-head video data is uniquely valuable for training and deploying multimodal AI models due to its deep integration of speech and vision. With Abaka AI’s premium, diverse, and scalable talking-head datasets, clients in AIGC, digital human, and intelligent interaction domains can build AI applications that are more realistic, expressive, and engaging.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.