
Among October’s top 6 most popular papers on Hugging Face was QeRL: Beyond Efficiency – Quantization‑enhanced Reinforcement Learning for LLMs (QeRL), which explores how quantization and adaptation techniques can boost RLHF speed and accuracy.
Blogs
2025-11-11/General
QeRL: How Quantization-Enhanced Reinforcement Learning is Redefining Speed and Accuracy in RLHF

Jessy Abu Khalil,Director of Sales Enablement
QeRL: How Quantization-Enhanced Reinforcement Learning is Redefining Speed and Accuracy in RLHF
Understanding QeRL and RLHF
Reinforcement Learning from Human Feedback (RLHF) has become the cornerstone of LLM alignment\~ teaching models to respond in ways that feel natural, safe, and useful. But as model sizes grow, RLHF training becomes computationally expensive and time-consuming.
QeRL introduces a breakthrough: it leverages quantized representations (like NVFP4 precision) to drastically reduce memory and computation requirements, while LoRA (Low-Rank Adaptation) ensures the model retains nuanced learning capacity.
Together, they create a lean, high-performance RLHF pipeline.
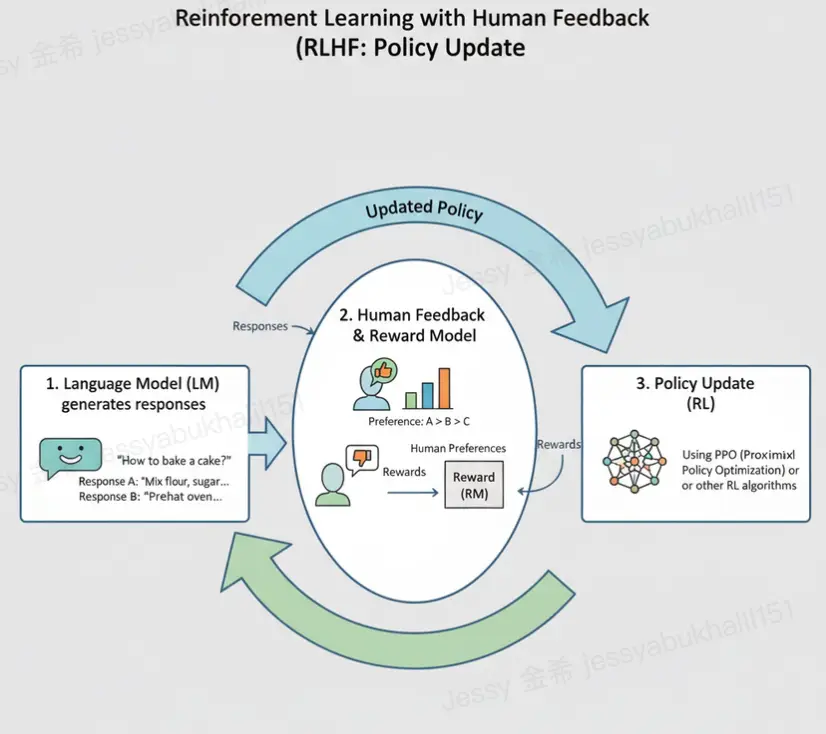
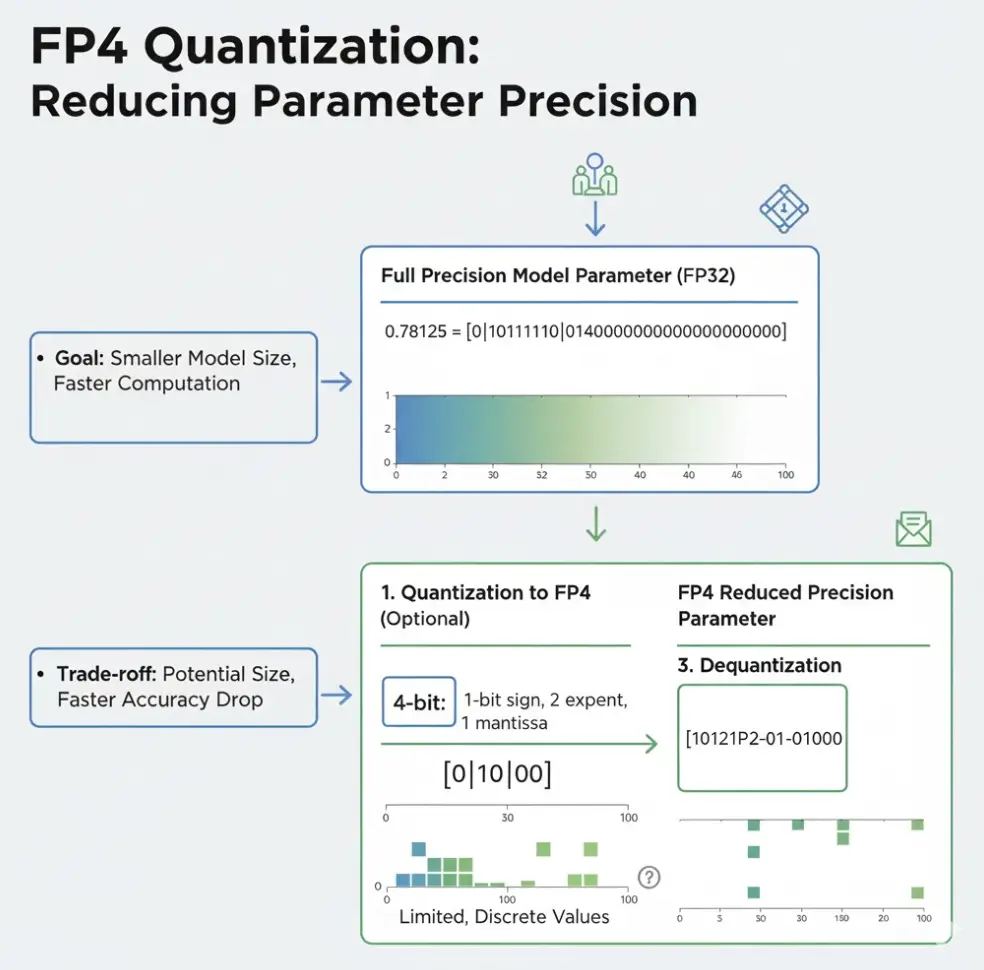
How NVFP4 and LoRA Accelerate RLHF
At the technical level, QeRL integrates two powerful optimizations:
NVFP4 Quantization (NVIDIA FP4)
Reduces parameter precision from 16-bit or 8-bit down to \~4-bit floating point.
Slashes memory usage and bandwidth requirements.
Enables substantially faster model updates without degrading alignment quality.
LoRA (Low-Rank Adaptation)
Fine-tunes only a small set of trainable parameters (low-rank matrices) rather than the entire model.
Preserves pretrained knowledge while allowing fast and cheap adaptation.
Cuts down training time by orders of magnitude\~ crucial for RLHF loops.
When combined, NVFP4 + LoRA make RLHF not only faster, but more energy-efficient and deployable. This combination allows researchers to run multiple experiments in parallel\~ accelerating the iteration cycle that drives high-quality model alignment.
Why QeRL Matters
The implications go far beyond speed. QeRL represents a paradigm shift in how we train responsibly:
Accessibility: Makes RLHF feasible for smaller labs and startups without massive GPU clusters.
Scalability: Enables training across multi-billion-parameter models while staying cost-efficient.
Sustainability: Reduces energy consumption and carbon footprint in large-scale AI training.
Iterative Alignment: Faster RLHF cycles mean more frequent updates and refinements to safety, style, and reasoning performance.
In short, QeRL bridges the gap between industrial-scale training and democratized experimentation.
Trends to Watch in 2025
The QeRL revolution reflects a broader shift across the AI ecosystem: optimization is becoming the competitive edge.
Key 2025 trends include:
Quantization-Aware RLHF: Integrating precision scaling into reinforcement training loops.
Cross-Hardware Adaptation: Training pipelines optimized for multi-vendor GPUs and on-device inference.
RLHF Democratization: Lightweight open frameworks that make alignment training possible outside Big Tech labs.
Evaluation Beyond Accuracy: Measuring response consistency, context awareness, and alignment drift across training runs.
The future of alignment is smarter, not simply heavier.
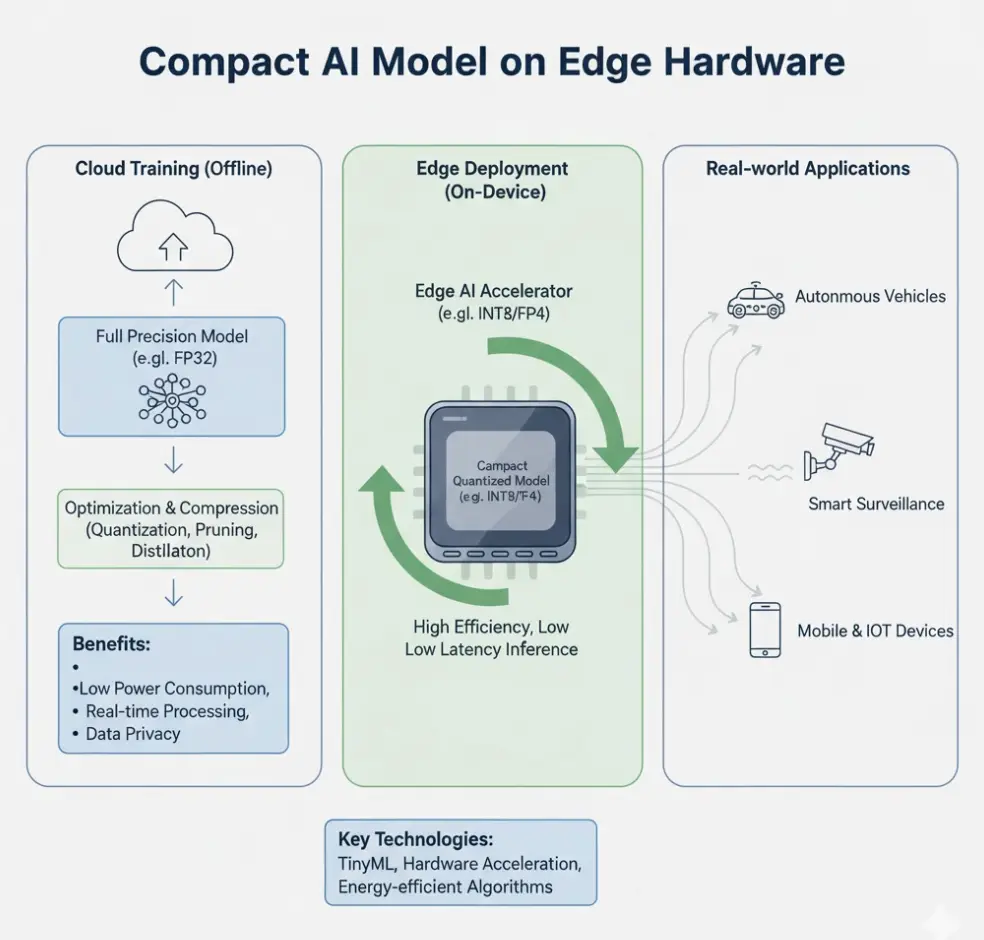
How Abaka AI Supports Reinforcement Learning Research
At Abaka AI, we help researchers and builders accelerate the path from model idea to production-ready intelligence. Our curated, large-scale datasets support text, dialogue, and multimodal RLHF workflows\~ enabling accurate, bias-mitigated reward models and human-aligned fine-tuning.
We specialize in:
Human Feedback Data Curation: High-quality instruction and preference datasets.
Video, Text, and Audio Datasets: For multimodal alignment and agent behavior modeling.
Benchmarking Services: Evaluate model performance across reasoning, factuality, and safety.
Whether you’re building foundational models or refining existing ones, Abaka AI datasets ensure your reinforcement learning cycles are efficient, fair, and scalable.
Get Started Today
The fusion of QeRL, NVFP4, and LoRA is shaping a new era of intelligent efficiency in AI training. As models grow in complexity, the key to staying ahead lies not in more computing but in smarter optimization and cleaner data.
At Abaka AI, we’re proud to power this evolution with the datasets and tools needed to train the next generation of aligned, efficient AI systems.
📩 Contact us to explore our curated datasets or discuss your RLHF projects and let’s build a faster, fairer future for AI together. 🚀
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.