
Synthetic data generated by LLMs provides a scalable, customizable alternative to real-world datasets. By leveraging the contextual understanding and generative capabilities of LLMs, organizations can produce structured text, code, or multimodal data for training, fine-tuning, and testing AI models without relying solely on labor-intensive manual collection.
Blogs
2025-09-26/General
Synthetic Data Generation: Using LLMs for Synthetic Data

Agnese Cipollone,AI Product Sales Specialist
Synthetic Data Generation: Using LLMs for Synthetic Data — The Definitive Guide
Understanding Synthetic Data and LLMs
Synthetic data is artificially generated information that mirrors real-world datasets in structure and patterns. LLMs, trained on massive textual corpora, can now produce realistic synthetic data across domains: from text and dialogue to structured tables and multimodal inputs like paired text-image data.
Applications of LLM-generated synthetic data include:
Training AI models when real-world data is scarce or sensitive.
Testing models under rare or extreme conditions.
Augmenting datasets to reduce bias and increase diversity.

How LLMs Generate Synthetic Data
LLMs leverage learned patterns in text, code, and structured data to produce realistic outputs. The process typically involves:
Prompt Engineering: Crafting prompts to guide the model toward generating data in a desired format or domain.
Contextual Sampling: Using probabilistic sampling strategies (top-k, nucleus sampling) to create diverse outputs.
Validation & Filtering: Automatically or manually checking outputs for consistency, accuracy, and relevancy.
Augmentation & Formatting: Structuring the generated data to fit the needs of downstream AI training or testing.
Different LLMs offer distinct capabilities depending on size, training data, and fine-tuning approaches. Emerging techniques increasingly allow multimodal data generation, combining text, images, or structured tables for richer datasets.
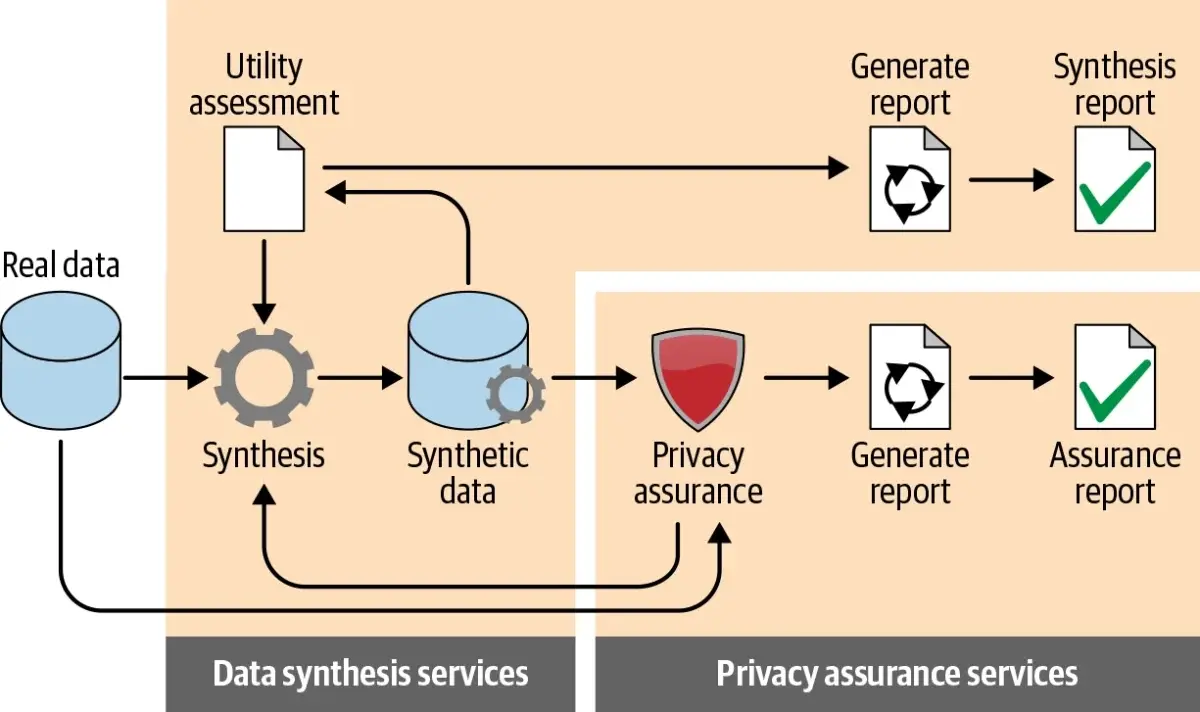
The Importance of Curated Synthetic Data
Not all synthetic data is equally useful. Curated synthetic datasets improve model reliability by:
Aligning generated data with target domains.
Removing implausible or noisy examples.
Balancing classes or categories to reduce bias.
Ensuring semantic and structural consistency for training tasks.
High-quality curated synthetic data can often replace or supplement real-world datasets, significantly reducing labeling costs and protecting sensitive information.
Emerging Trends in 2025
Key trends in synthetic data generation using LLMs include:
Multimodal Synthesis: Generating text, images, and code together for richer AI training datasets.
Domain-Specific Generation: Custom datasets for healthcare, finance, or autonomous systems.
Automated Validation: Using AI to check synthetic data quality and reduce human annotation.
Bias Mitigation: Targeted data generation to balance datasets across demographics and scenarios.
These trends indicate a shift toward scalable, ethical, and high-fidelity data generation for AI applications.
How Abaka AI Supports Synthetic Data
At Abaka AI, we provide both off-the-shelf and fully customized synthetic datasets powered by LLMs. Our offerings include:
Text & Dialogue
Structured & Tabular Data
Multimodal Datasets
Our expert annotation and validation pipelines ensure the generated datasets are accurate, diverse, and aligned with real-world use cases. By leveraging Abaka AI synthetic datasets, companies can accelerate model training, mitigate privacy concerns, and expand their AI capabilities safely and efficiently.
Get Started Today
Synthetic data generation with LLMs is transforming how AI models are trained, tested, and fine-tuned. Its success relies on both advanced model capabilities and carefully curated datasets.
📩 Contact us today to explore curated image datasets or discuss your project needs. Let’s power the next generation of vision AI together 🚀
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.