
Explore AI agent advancements: datasets, evaluation, CGAT tool, VeriGUI paper, ACL 2025 recap, and Bay Area hiring.
Blogs
2025-08-15/Weekly Insights
Abaka Pulse: AI Agents & Coding Data Insights | Aug 1-Aug 12
Abaka Pulse : Latest Insights in AI & Data | Aug1-Aug12
At the Core | What We're Exploring
What's Driving the AI Agent Revolution?
The race to build truly autonomous AI Agents is accelerating. As headlines showcase their potential to revolutionize industries, leading developers are facing the critical next step: moving from promising demos to reliable, real-world products. This leap depends entirely on overcoming two core challenges: sourcing intelligent data and proving genuine capability.
Building the Brain: Beyond Simple Datasets
To perform complex tasks, an agent needs more than just data; it needs a blueprint for thinking. Standard datasets fall short because they don't capture the essential reasoning, tool use, and decision-making sequences that define an effective agent. Abaka AI specializes in Agent Dataset Construction, creating high-fidelity data that maps the entire "thought-to-action" process. We provide the rich, structured foundation your models need to learn how to strategize and execute in dynamic environments.
The Reality Check: Evaluating True Performance
Once an agent is built, how do you verify it's truly effective and not just good at passing simple tests? Standard benchmarks often fail to measure an agent's real-world problem-solving skills. Our Agent Evaluation Services are designed to provide that certainty. We create custom, complex testing scenarios that push agents to their limits, assessing their true reasoning and tool-handling capabilities. This rigorous evaluation provides the critical insights needed to refine your agent and ensure a reliable return on your development investment.
Ready to Lead the Agent Revolution?
Whether you are building the foundational intelligence with advanced training data or validating its real-world effectiveness, Abaka AI has the expertise to help you succeed.
BOOK A DEMO to see how our Agent Dataset and Evaluation services can accelerate your roadmap, or CONTACT OUR EXPERT TEAM for a free consultation.
Moore Power | Updates & Features of Abaka Forge Platform
CGAT: The Chrome GUI Annotation Tool
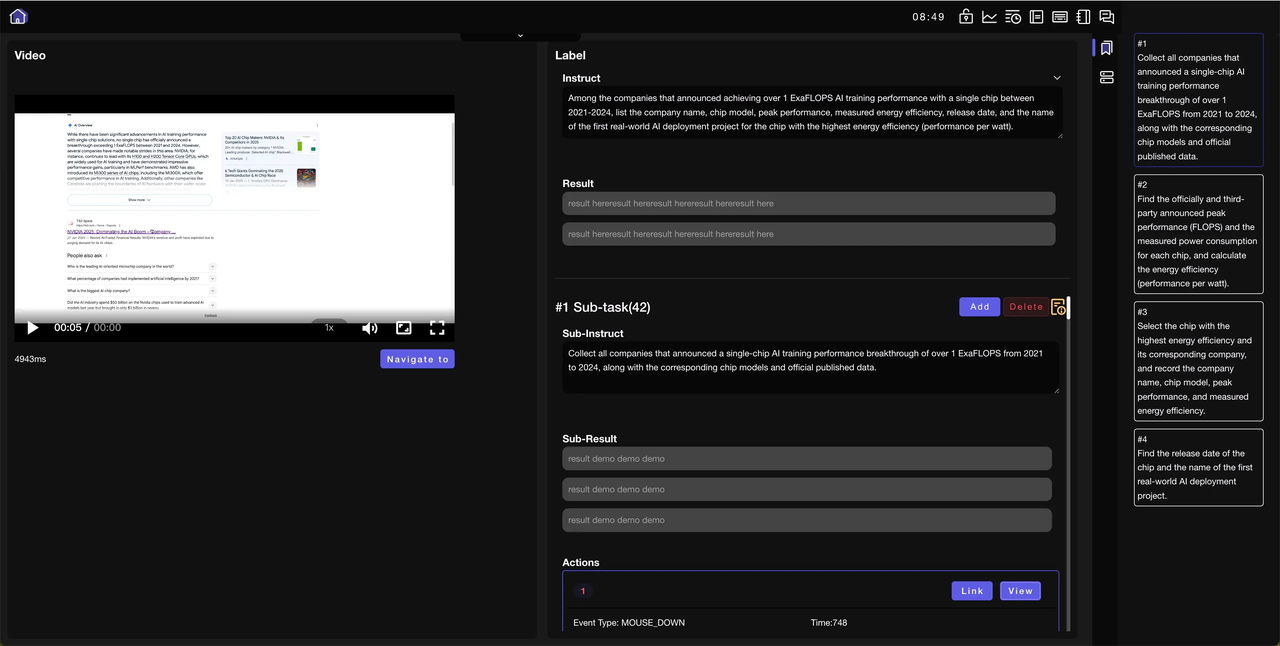
We are excited to introduce the Chrome GUI Annotation Tool (CGAT), a powerful data collection and annotation tool engineered specifically for creating high-quality datasets for AI Agent training and evaluation.
CGAT allows users to simulate the step-by-step process of an agent executing commands, such as using web searches to solve complex problems. It excels at breaking down a large task into multiple sub-tasks and precisely recording the entire problem-solving chain. The tool captures a comprehensive range of data—from behavioral data and screen operation videos to the raw HTML of the webpage.
After collection, the platform supports detailed manual annotation and result summarization, ensuring that every single data point is traceable and verifiable. This level of precision is crucial for building the next generation of smarter, more reliable AI Agents.
Dynamic Workflows with Dual-Mode Data Flow
We've completely re-architected our workflow system to accelerate your entire data lifecycle, from initial annotation to final acceptance. This new dynamic framework is built around four core stages—Annotation, Internal Review, Review, and Acceptance—with, with an innovative system designed to optimize each step.
At its core is a dual-mode data flow system that intelligently adapts to the needs of different stages:
Item-by-Item Flow for Annotation: In the crucial initial stage, data is processed one item at a time. This allows annotators to maintain a seamless, uninterrupted rhythm, maximizing their focus and productivity to ensure the highest level of precision on each task.
Batch Flow for Review & Delivery: Once data progresses to later stages, the system switches to a batch flow model. This bundles validated data into cohesive, independent modules, which are essential for simplifying final quality assurance, optimizing project delivery, and guaranteeing the structural integrity of the final dataset.
This hybrid approach empowers your team by perfectly balancing the dual needs of the data lifecycle: the demand for speed and precision during annotation, and the need for structure and integrity during delivery.
Latest Insights | Knowledge, Releases, Ideas
Our VeriGUI Paper is Live and Trending!

We are thrilled to announce the official release of our paper, VeriGUI: A Verifiable Long-Chain GUI Dataset for General-purpose Agents, which Abaka AI is proud to have contributed to. The paper was met with incredible community interest, climbing the charts to #3 on the Hugging Face leaderboard on its release day.
VeriGUI addresses the critical challenge of long-chain complexity that has limited GUI agents. By featuring tasks with hundreds of interdependent operations and unique step-by-step verifiability, it provides the foundation for training agents that can handle realistic, complex workflows. This expertly-annotated dataset is a crucial step forward for developing more robust planning and decision-making in GUI agents.
On the Ground | Where We Are & Who We're Talking To
PAST EVENT: Wrapping Up a Great Week at ACL 2025
We've just concluded an inspiring week at ACL 2025! It was a fantastic opportunity to connect with the world's leading minds in computational linguistics and natural language processing. A special thank you to everyone who took the time to meet with our Head of the Abaka European Team, Omid. We're energized by the insightful conversations about the future of AI and look forward to the collaborations ahead.
On Our Radar | What We’re Reading
SWE-SWISS: A "Swiss Army Knife" for Efficiently Fixing Code A joint effort from Peking University and ByteDance introduces SWE-SWISS, a complete methodology for training highly efficient code-fixing agents. Their 32B model achieves a new state-of-the-art 60.2% accuracy on the SWE-bench, performing on par with much larger models. The "recipe" deconstructs bug-fixing into three core skills (localization, repair, and test generation) and uses a sophisticated process combining SFT and RL. This work's focus on structured methodology and high-quality data to empower smaller models aligns perfectly with our philosophy for building powerful, specialized AI agents.
WideSearch: A New Benchmark for Broad Info-Seeking Agents Current benchmarks often fail to test an agent's ability to perform large-scale information gathering. The new WideSearch benchmark fills this critical gap, featuring 200 complex, real-world queries that require agents to collect a large volume of verifiable facts. The findings are stark: most state-of-the-art systems score near 0%, revealing a major weakness in today's agentic search capabilities. This research underscores the urgent need for robust evaluation frameworks—a core focus of our Agent Evaluation Services—to truly understand and improve agent performance.
Stay Tuned with Abaka Pulse!
Missed an issue? Check out our NEWSLETTER ARCHIVE.
See you next pulse!
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.