How AI Data Collection Works: Methods, Challenges, and Best Practices
Nadya Widjaja,Director of Growth Marketing
AI model performance depends on the data choices teams make before training even starts. Data collection, including how data is sourced, cleaned, labeled, and managed, is the main driver of whether models scale reliably or fail during production. This article explains how AI data collection works in practice, compares the main data collection methods, highlights the most common risks teams face, and outlines best practices for building high-quality, scalable, and compliant datasets for modern multimodal AI systems.
How AI Data Collection Works: Methods, Challenges, and Best Practices
When improving AI model performance, emphasis is often placed on model architecture and training methods. What is often overlooked is data quality. If raw data is incomplete, biased, or legally risky, no amount of fine-tuning can compensate for it.
This article breaks down how AI data collection actually works, examines the most common failure modes, and outlines best practices for building high-quality, scalable, and compliant datasets, particularly for multimodal AI systems spanning text, image, video, and audio data.
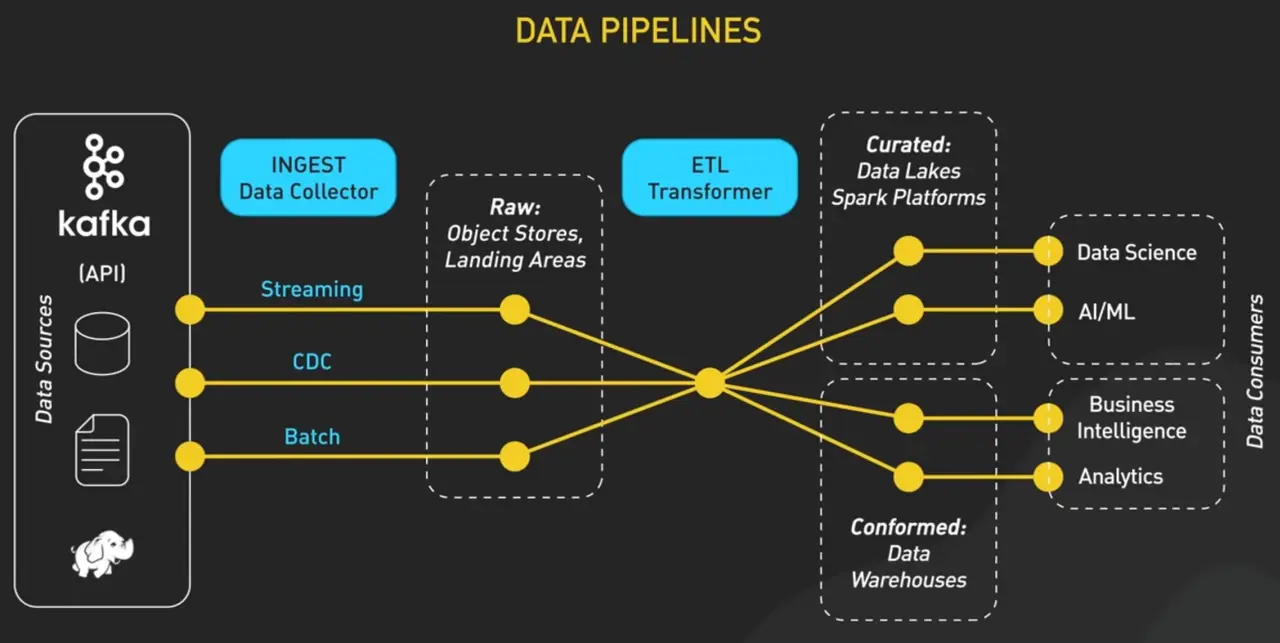
A Practical AI Data Pipeline Map [1]
What is AI Data Collection?
AI data collection is the end-to-end process of gathering, organizing, and preparing data so that machine learning and AI models can learn patterns reliably. It goes far beyond simply accumulating large volumes of raw information. Instead, effective data collection ensures that the data used in training pipelines is relevant, usable, and aligned with the model's objectives.
In practice, AI data collection begins with data sourcing. This may involve collecting data from the web, accessing structured data through APIs, ingesting sensor or IoT data, working with third-party partners, using user-generated content, or generating synthetic data to fill gaps where real-world examples are limited. Once data is sourced, it must move through data pipeline intake that supports storage, tracking changes, and traceability, allowing teams to track how datasets evolve over time.
Quality control is a critical step in this process. Since raw data is rarely model-ready, it must be checked for errors, inconsistencies, and duplicates. This includes removing duplicate records, a process called deduplication, running integrity checks to ensure fields are valid and complete, and performing sampling audits to verify that the dataset accurately represents the intended population or use case.
After quality checks, data often requires labeling and refinement. This step involves annotating data with meaningful labels, designing clear label structures that reflect real-world concepts, and adding contextual information that helps models interpret the data accurately. High-quality labeling is essential for supervised learning, as poorly defined or inconsistent labels can degrade model performance more than small dataset size.
Finally, AI data collection must be managed by clear data governance practices. This includes managing user consent, protecting privacy, respecting licensing and intellectual property rights, and maintaining audit trails that document how data is collected and used. Governance ensures that datasets are not only effective, but also legally compliant and ethical.
A rule of thumb to follow is:
If you cannot explain where your data came from, what rights you have, and how it changed over time, you don't have an AI-ready dataset.
Why Do AI Teams Need So Much Data?
Modern AI models require large volumes of data for two main reasons.
First, training, validation and test datasets must be clearly separated to ensure models are evaluated on data they have never seen before. Without this separation, performance metrics become misleading and unreliable.
Second, datasets must be sufficiently representative to allow models to generalize beyond the training distribution. Models trained on narrow or incomplete data often perform well in controlled settings but fail in real-world deployment.
The hidden cost is that teams spend enormous effort turning raw data into usable training material. Cleaning, filtering, labeling, and validating data often consume the majority of project time and resources. As a result, poor data quality is not just a technical issue but a financial one. One widely cited estimate suggests that organizations lose an average of $12.9 million annually due to poor data quality, emphasizing how expensive bad data can be (Forbes Leadership).
What Are the Main Methods of AI Data Collection?
Modern AI systems rely on data from multiple sources. Each collection method serves a different purpose, comes with distinct trade-offs, and requires specific safeguards to ensure data quality, scalability, and compliance.
Web Scraping for AI Datasets
Web scraping extracts publicly available content, such as product pages, documentation, forums, listings, and media, and converts them into structured records usable for training and evaluation.
This method is suitable for capturing broad coverage and long-tail domains, making it especially useful for messy, real-world language and fast-evolving topics. However, it must be noted that it is also one of the most fragile data sources. Websites frequently change their structure, and many deploy anti-bot defenses such as CAPTCHAs, fingerprinting, and rate limits. Legal and licensing ambiguity can further complicate large-scale scraping efforts.
Best Practices
Prioritizing official APIs where available
Implementing rate-limits, retries, monitoring, and change detection
Storing both raw captures and cleaned, structured outputs for traceability and auditability
APIs and public datasets typically provide cleaner, more structured data, often in JSON format, and are generally more stable and reliable than web scraping. They are suitable for financial data, government statistics, platform analytics, and other standardized data sources.
Best Practices
Treat APIs as data contracts rather than static sources:
Monitoring schema changes
Versioning datasets
Keeping a clear data dictionary that documents field meaning, units and how missing values are handled
Sensor and IoT Data Collection
Sensors and IoT data are the primary data sources for robotics, automotive systems, wearables, healthcare devices, and industrial AI. These systems generate continuous streams of real-world data that are critical for time-sensitive and safety-critical applications.
Best Practices
Validating sensor calibration and monitoring for drift
Logging environment metadata such as weather, lighting, and device models
Designing data collection loops that capture edge cases, since rare events are often where models fail
Manual labeling and annotation
Labeling and annotation convert raw data into supervised learning signals, including anything from class labels, bounding boxes, segmentation masks, attributes, temporal events, question-answer pairs, and many others. While essential, data annotation is often where teams lose the most time, consistency, and at times, overall data quality.
Common failure points include vague label definitions due to annotator disagreements, label structures that don't align with models' objectives, and the absence of audit loops, allowing errors to accumulate silently.
Best Practices
Writing annotation guidelines with clear definitions, counterexamples, and edge cases
Using gold tasks and inter-annotator agreement checks
Reviewing overall label distributions rather than just relying on random sample checks
Abaka AI supports multimodal data collection and annotation through trained global annotator experts, structured QA workflows, and enforced label structures, which allows teams to scale labeling without sacrificing consistency.
Synthetic data is artificially generated data designed to mimic real-world data distributions. It is commonly used to reduce privacy exposure, generate rare edge cases, address class imbalances, and stress-test models under controlled conditions.
Something to be careful of is that synthetic data can also introduce "fake realism", where evaluation metrics improve while real-world performance worsens.
Best Practices
Using synthetic data to target specific gaps such as rare events and long tail rather than replace real data
Validating performance against real-world thresholds
Tracking synthetic proportion by label and domain to avoid over-reliance
What Are the Biggest Challenges in AI Data Collection?
Despite advances in automation and tooling, AI data collection remains one of the most fragile and risk-prone stages of model development. Legal exposure, bias, technical instability, and cost constraints frequently undermine otherwise strong AI systems.
Legal and ethical risks
AI data collection has become a board-level issue due to growing concerns around intellectual property, privacy and user consent. The lawsuit filed by The New York Times against OpenAI and Microsoft back in December 2023 illustrates how training-data sourcing can escalate into a high-stakes legal dispute.
Beyond litigation risk, research also emphasizes the ethical tradeoff between AI innovation and privacy, especially regarding consent, governance, and bias controls.
Best Practices
Maintain clear dataset lineage and proof of usage rights, including licenses, terms of service, and contracts
Separate research-only data from production-trainable data
Implement privacy filters and retention policies early, not only after launch
Dataset Biases and Representation Gaps
Biases in AI datasets rarely come from a single source. Instead, they emerge through a combination of structural and human factors, including over-representation of certain languages, demographics, residual bias embedded in historical data, and subjectivity of labeling decisions.
For example, Amazon reportedly scrapped an internal recruiting tool back in 2018 after discovering bias against women, which was linked to patterns in historical hiring data (Reuters, 2018).
Best Practices
Run bias audits during data collection , not only during model evaluation
Track coverage metrics to identify who, where, and what is underrepresented
Create targeted data collections to fill specific representation gaps
Why Web Scraping Breaks at Production Scale
Although web scraping is a powerful data collection method, many pipelines that perform well during experimentation fail once deployed at scale. Production environments introduce reliability, monitoring, and maintenance challenges that are often underestimated during initial setup, leading to silent failures and data degradation over time.
Cost vs. Accuracy
Higher model accuracy usually requires better data sourcing, stronger quality assurance, deeper domain expertise, and more consistent labeling. These improvements can drive costs up rapidly, especially for video, multilingual, and multimodal datasets.
The key challenge is not choosing between cost and accuracy, but deciding where additional data investment actually improves model performance.
Best Practices
Prioritize underperforming data segments rather than expanding datasets uniformly
Treat annotation as core model infrastructure, not routine maintenance work
Use model evaluation results to decide what data should be collected next
How Abaka AI addresses this
Abaka AI designs evaluation-driven data collection strategies that directly target model weaknesses. Instead of scaling datasets blindly, Abaka identifies underperforming segments, collects and labels the data that matters most, and enforces quality controls that translate directly into measurable performance gains. This approach allows teams to improve accuracy efficiently without unnecessary data expansion or wasted annotation costs.
Common Data Collection Risks [2-4]
What Does a Best Practice AI Data Pipeline Look Like?
Not every part of an AI data pipeline should be automated; some steps require human judgment. The most effective pipelines combine automation for scale and consistency with human judgment for decisions that involve nuance, interpretability, and accountability. Knowing which tasks to automate and which require human decision-making is critical to maintaining data quality and regulatory compliance over time.
Tasks that are repetitive, rule-based, and difficult to manage manually at scale should be automated wherever possible. This includes bringing data into internal systems, validating data structures when formats or fields change, removing duplicate records, and tracking how datasets change over time. Automated validation checks and anomaly detection help identify issues early, while regularly scheduled data updates ensure that models are not trained on outdated or drifting data sources.
At the same time, certain decisions should remain human-led. Defining how data should be labeled, creating high-quality reference labels, resolving ambiguous cases, and reviewing sensitive or high-risk data all require contextual judgment that automation alone cannot provide. Human review is especially important in domains involving safety, regulation, or ethical risk, where small errors can have disproportionate consequences.
Effective pipelines also rely on quality checks that catch problems early and before they reach model training. These include monitoring for duplicate or inconsistent records, verifying label consistency across annotators, measuring dataset coverage to identify gaps, and tracking data drift as underlying sources change over time.
Finally, a best-practice AI data pipeline is designed to be compliant and audit-ready from the start. This means clearly documenting where data originates, how it is transformed, and which dataset versions are used in training or evaluation. Strong access controls, encryption, and clearly defined data retention and deletion policies help protect sensitive information, while well-maintained documentation ensures continuity even as teams change.
In summary, the goal of a best-practice AI data pipeline is not merely to move data efficiently, but to make data reliable, traceable, and defensible throughout the entire model lifecycle.
AI-Ready Data Final Checklist [AI generated]
Key Takeaways
AI model performance is shaped long before training begins. Data collection decisions, including how data is sourced, filtered, labeled and governed, determine whether models generalize reliably or fail silently in production. Data collection should be treated as infrastructure instead of merely a preprocessing step with the increasing dependence on multimodal AI systems. Teams that invest in traceability, evaluation-driven collection, and quality enforcement build models that are not only more accurate, but more defensible. In modern AI systems, better data is not just input, but a competitive advantage.
Want to Build AI-Ready Datasets Without Scaling Risk?
Contact Abaka AI - Speak with our specialists about evaluation-driven data collection, annotation quality control, and scalable pipelines for text, image, video, and multimodal AI.
Explore Our Blog - Read insights on AI data collection, multimodal annotation, synthetic data, and dataset best practices.
Read Our FAQs - Get answers on data sourcing, annotation workflows, governance, and scaling AI datasets responsibly.